СПРАВКА
Источник публикации
М.: ФГБУ "Институт стандартизации", 2025
Примечание к документу
Документ введен в действие с 01.01.2026 на период до 01.01.2029 (Приказ Росстандарта от 23.09.2025 N 31-пнст).
Название документа
"ПНСТ 1019-2025. Предварительный национальный стандарт Российской Федерации. Информационные технологии. Биометрия. Методология оценки эксплуатационных характеристик биометрических систем с использованием статистических моделей"
(утв. и введен в действие Приказом Росстандарта от 23.09.2025 N 31-пнст)
"ПНСТ 1019-2025. Предварительный национальный стандарт Российской Федерации. Информационные технологии. Биометрия. Методология оценки эксплуатационных характеристик биометрических систем с использованием статистических моделей"
(утв. и введен в действие Приказом Росстандарта от 23.09.2025 N 31-пнст)
Содержание
Приказом Федерального
агентства по техническому
регулированию и метрологии
от 23 сентября 2025 г. N 31-пнст
ПРЕДВАРИТЕЛЬНЫЙ НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
БИОМЕТРИЯ
МЕТОДОЛОГИЯ ОЦЕНКИ ЭКСПЛУАТАЦИОННЫХ ХАРАКТЕРИСТИК
БИОМЕТРИЧЕСКИХ СИСТЕМ С ИСПОЛЬЗОВАНИЕМ
СТАТИСТИЧЕСКИХ МОДЕЛЕЙ
Information technologies. Biometrics. Biometric performance
estimation methodologies of biometric systems using
statistical models
ПНСТ 1019-2025
ОКС 35.240.15
Срок действия
с 1 января 2026 года
до 1 января 2029 года
1 РАЗРАБОТАН Федеральным государственным бюджетным учреждением "Российский институт стандартизации" (ФГБУ "Институт стандартизации") и Некоммерческим партнерством "Русское общество содействия развитию биометрических технологий, систем и коммуникаций" (Некоммерческое партнерство "Русское биометрическое общество")
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 098 "Биометрия и биомониторинг"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 23 сентября 2025 г. N 31-пнст
Правила применения настоящего стандарта и проведения его мониторинга установлены в ГОСТ Р 1.16-2011 (разделы 5 и 6).
Федеральное агентство по техническому регулированию и метрологии собирает сведения о практическом применении настоящего стандарта. Данные сведения, а также замечания и предложения по содержанию стандарта можно направить не позднее чем за 4 мес до истечения срока его действия разработчику настоящего стандарта по адресу: 107045 Москва, Сретенский тупик, д. 3, стр. 1, e-mail: standards@rusbiometrics.com и/или в Федеральное агентство по техническому регулированию и метрологии по адресу: 123112 Москва, Пресненская набережная, д. 10, стр. 2.
В случае отмены настоящего стандарта соответствующая информация будет опубликована в ежемесячном информационном указателе "Национальные стандарты" и также будет размещена на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет (www.rst.gov.ru)
Настоящий стандарт устанавливает методологию оценки эксплуатационных характеристик биометрических систем на основе статистических моделей, отнесенных к категории теории экстремальных значений. Эта методология особенно эффективна при оценке вероятности ложного совпадения на наборе данных небольшого объема. Методология является альтернативой методам оценки на основе эмпирических данных.
Для надежной оценки вероятности ложного совпадения в системах биометрической верификации требуется наличие набора данных со значительным числом попыток непарного сравнения. В высокоточных системах для оценки вероятности ложных совпадений требуется большое число попыток. По мере улучшения эксплуатационных характеристик систем биометрической верификации получение репрезентативных данных о попытках непарного сравнения в достаточном объеме становится все более трудным и затратным по времени, стоимости и практическому созданию наборов данных. Дополнительные ограничения может создавать политика сбора и использования биометрических персональных данных.
Если в экспериментальном наборе данных не наблюдают случаев ложного совпадения, то в биометрии используют основанное на статистике правило трех (см. ГОСТ Р 71414.1). Правило трех применяют только при отсутствии случаев ложного совпадения в испытуемом наборе данных, при этом следует учитывать, что отсутствуют сведения об ожидаемых уровнях точности и достоверности результатов оценки биометрической системы в случае отличного от нуля количества ложных совпадений. Если было обнаружено не менее 30 ложных совпадений, то применяют правило тридцати, согласно которому истинная вероятность ошибки находится в пределах +/- 30% наблюдаемой вероятности ошибки с достоверностью 90%.
В настоящем стандарте представлены два основных статистических метода для оценки вероятности ложного совпадения при относительно небольшом объеме данных. Оба метода используют в различных отраслях экономики, включая гражданское строительство, метеорологию, гидрологию, финансы и страхование. Данные методы зарекомендовали себя как высоконадежные методы оценки вероятности возникновения редких экстремальных явлений, например максимальной скорости ветра или высоты цунами. Эти статистические методы также применяют к схожим редким случаям ложного совпадения в биометрии и используют для оценки вероятности возникновения таких случаев, если больший набор данных для непарного сравнения недоступен. Предполагаемая вероятность ложного совпадения в настоящем стандарте представлена в виде кумулятивной функции распределения и ее доверительного интервала.
Настоящий стандарт определяет процедуры экстраполяции эксплуатационных характеристик биометрических систем в технологических испытаниях. Эти процедуры допускается применять в сценарных и оперативных испытаниях, если доступны данные о результатах сравнения. В настоящем стандарте установлена методология, которую должны использовать экспериментаторы для оценки вероятности ложного совпадения в случае отсутствия или ограниченного числа случаев ложного совпадения.
Настоящий стандарт устанавливает методологию оценки эксплуатационных характеристик биометрических систем с использованием статистических моделей на основе определения вероятности ложного совпадения (ВЛС) на небольших наборах данных.
В настоящем стандарте установлены требования:
- к оценке эксплуатационных характеристик биометрических систем на основе экстраполяции с использованием статистических моделей экстремальных значений;
- применению статистических методов для оценки ВЛС систем биометрической верификации;
- регистрации данных и формированию протокола испытаний.
Настоящий стандарт не распространяется на оценку вероятности ложноположительной биометрической идентификации для реализаций "один ко многим" и оценку вероятности ложного допуска в транзакциях биометрической верификации.
В настоящем стандарте использованы нормативные ссылки на следующие стандарты:
ГОСТ ISO/IEC 2382-37 Информационные технологии. Словарь. Часть 37. Биометрия
ГОСТ Р 71414.1-2024 (ИСО/МЭК 19795-1:2021) Информационные технологии. Биометрия. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 1. Принципы и структура
Примечание - При пользовании настоящим стандартом целесообразно проверить действие ссылочных стандартов в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет или по ежегодному информационному указателю "Национальные стандарты", который опубликован по состоянию на 1 января текущего года, и по выпускам ежемесячного информационного указателя "Национальные стандарты" за текущий год. Если заменен ссылочный стандарт, на который дана недатированная ссылка, то рекомендуется использовать действующую версию этого стандарта с учетом всех внесенных в данную версию изменений. Если заменен ссылочный стандарт, на который дана датированная ссылка, то рекомендуется использовать версию этого стандарта с указанным выше годом утверждения (принятия). Если после утверждения настоящего стандарта в ссылочный стандарт, на который дана датированная ссылка, внесено изменение, затрагивающее положение, на которое дана ссылка, то это положение рекомендуется применять без учета данного изменения. Если ссылочный стандарт отменен без замены, то положение, в котором дана ссылка на него, рекомендуется применять в части, не затрагивающей эту ссылку.
В настоящем стандарте применены термины по ГОСТ ISO/IEC 2382-37, а также следующие термины с соответствующими определениями:
3.1 экстраполированная вероятность ложного совпадения; экстраполированная ВЛС: ВЛС, которую оценивают с использованием любых статистических моделей, например тех, которые используют в теории экстремальных значений.
3.2 график квантиль-квантиль; график Q-Q: Квантиль-квантильное сравнение двух распределений, одно или оба из которых могут быть эмпирическими или теоретическими.
В настоящем стандарте применены следующие сокращения:
ВЛНС - вероятность ложного несовпадения;
ВЛС - вероятность ложного совпадения;
CDF - кумулятивная функция распределения (cumulative distribution function);
FRGC - конкурс по распознаванию лиц (face recognition grand challenge);
GEI - изображение энергии походки (gait energy image);
GEV - обобщенное распределение экстремальных значений (generalized extreme value distribution);
GP - обобщенное распределение Парето (generalized Pareto distribution);
MLE - метод максимального правдоподобия (maximum likelihood estimation);
rGEV - предельное совместное обобщенное распределение экстремальных значений для статистики наибольшего порядка r.
5.1 Оценка эксплуатационных характеристик биометрической системы на основе теории экстремальных значений
Теорию экстремальных значений используют для правильной оценки хвостов распределения результатов сравнения разных субъектов сбора биометрических персональных данных. Анализ хвоста распределения результатов сравнения позволяет экстраполировать значения за пределы наблюдаемого диапазона.
Метод извлечения хвоста распределения результатов сравнения различается в зависимости от того, является ли применяемая модель распределения экстремальных значений моделью GEV (rGEV) или моделью GP. Более подробную информацию об этих моделях см. в 5.3, 5.4 и приложении А.
Теорию экстремальных значений применяют к извлеченному набору результатов сравнения для оценки оптимальных параметров распределения, а распределение результатов сравнения аппроксимируют.
Результат, аппроксимированный статистикой экстремальных значений, сравнивают с исходным распределением результатов сравнения с использованием диагностической диаграммы. Экстраполируя распределение результатов сравнения, получают распределение для диапазона, не имеющего эмпирического значения результата сравнения. Экстраполированную ВЛС получают путем установки порогового значения из распределения результатов сравнения.
Данную методологию можно применять не только при технологических испытаниях, но и при сценарных и оперативных испытаниях, если доступны результаты сравнения.
Если результаты сравнения получены на наборе данных, в котором некоторые субъекты сбора биометрических персональных данных генетически связаны (например, однояйцевые близнецы или братья и сестры), то распределение вероятностей в области крайних значений может быть выше, чем при отсутствии таких связанных данных, что, как правило, приводит к небольшому вторичному пику. Метод экстраполяции ВЛС работает для таких распределений, отражая увеличение вероятности. Экспериментатор должен зафиксировать предполагаемые результаты вместе с демографической информацией о наборе данных.
Если набор данных имеет непреднамеренный(е) пик(и) в области экстремальных значений и эти значения не находятся в диапазоне игнорируемых ошибок, то рекомендуется ввести стратифицированный анализ. Один набор данных состоит из n разных групп испытуемых субъектов сбора биометрических персональных данных. Распределение набора данных будет иметь синтезированные характеристики каждой группы, отражающие каждый статистический параметр (например, среднее значение, дисперсию и число образцов). Если различия между группами оказываются статистически значимыми и долю таких групп нельзя игнорировать, то эти группы могут быть разделены на поднаборы данных (до n) и оценены независимо. Несмотря на то, что эти поднаборы данных зависят от биометрических модальностей, в общем случае они характеризуются следующими свойствами испытательной группы:
а) родство;
б) раса и пол;
в) род деятельности;
г) состояние здоровья;
д) другие факторы, снижающие уникальность представляющих интерес биометрических признаков.
Экстраполированную ВЛС для каждого поднабора данных рассчитывают в соответствии с требованиями 5.3 и 5.4. Детальная информация о поднаборах данных должна быть задокументирована в соответствии с требованиями ГОСТ Р 71414.1-2024, пункт 12.1.
5.2 Оценка размера выборки
Размер выборки определяют с учетом целевого значения ВЛС и требуемой точности оценки. Для измерения ВЛС (0,0001 +/- 30)% с достоверностью 90% требуется 30 ложных совпадений в 30 миллионах непарных сравнений ["правило тридцати" (см. ГОСТ Р 71414.1)]. Это означает, что для расчета ВЛС необходимо несколько тысяч испытуемых. Данное число испытуемых можно уменьшить, используя соответствующие статистические оценки и допуская определенное количество ошибок.
Экстраполированную ВЛС оценивают с использованием экстремальных значений, поэтому для получения более точных результатов рекомендуется использовать значительное число образцов, при этом точность количественно определяют доверительным интервалом, дающим наилучшее и наихудшее значения ВЛС для определенного уровня достоверности. Если значения экстраполированной ВЛС получены при нескольких пороговых значениях, то значение экстраполированной ВЛС с более узким доверительным интервалом считают более надежным.
Решение о подлежащем протоколированию пороговом значении и соответствующем ему экстраполированном значении ВЛС принимает экспериментатор. Для протоколирования ВЛНС применяют то же пороговое значение.
Оценка rGEV основана на модели обобщенного распределения экстремальных значений, как описано в А.2. Этапы процесса оценки следующие:
n должно быть достаточно большим, чтобы каждый блок содержал некоторые экстремальные значения, т.е. большие значения результатов непарного сравнения. С другой стороны, n нужно учитывать при выборе числа блоков m, поскольку число экстремальных значений в блоке уменьшается по мере увеличения m.
Значение r определяет число экстремальных значений, извлеченных из каждого блока, и следовательно число образцов, используемых для оценки. Для оценки "сходства" используют наибольшие экстремальные значения внутри блока; для оценки "несходства" - наименьшие экстремальные значения внутри блока. Чем больше значение r, тем больше набор данных для оценки, что повышает пригодность оцененной CDF. Если значение r слишком велико, то в набор данных для оценки могут быть включены результаты непарного сравнения, которые нельзя рассматривать как экстремальные значения, что ухудшает пригодность оцененной CDF. Типичный диапазон значений r для оценки экстремальных природных явлений составляет от 1 до 5, что также применимо к оценке экстраполированной ВЛС.
3) Вычисление предполагаемого набора параметров 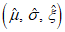 (см. А.2) с помощью экстремальных значений, полученных на этапах 1) и 2), и алгоритма MLE.
(см. А.2) с помощью экстремальных значений, полученных на этапах 1) и 2), и алгоритма MLE.
(см. А.2) с помощью экстремальных значений, полученных на этапах 1) и 2), и алгоритма MLE.На основании гипотезы о том, что истинная функция распределения вероятностей принадлежит к семейству GEV, следует применять алгоритм MLE для получения набора параметров 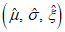 .
.
.4) Построение графика Q-Q и проверка пригодности оценки
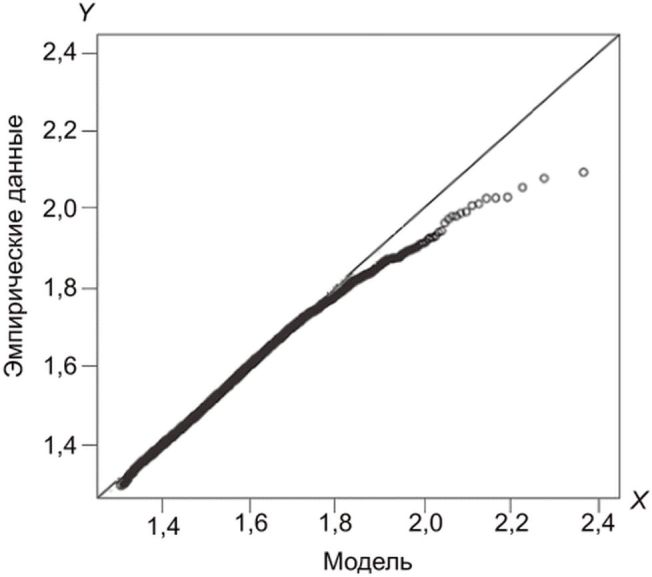
График Q-Q - это графический статистический метод, в котором сравнивают два распределения вероятностей, сопоставляя их друг с другом. Сначала выбирают набор квантильных интервалов. Точка (x, y) на графике соответствует одному из квантилей первого (координата x) и второго (координата y) распределения. Таким образом, линия представляет собой кривую с параметрами, соединяющими квантили. Если два сравниваемых распределения похожи, то точка на графике Q-Q находится рядом с линией y = x. На рисунке 1 показан пример графика Q-Q.
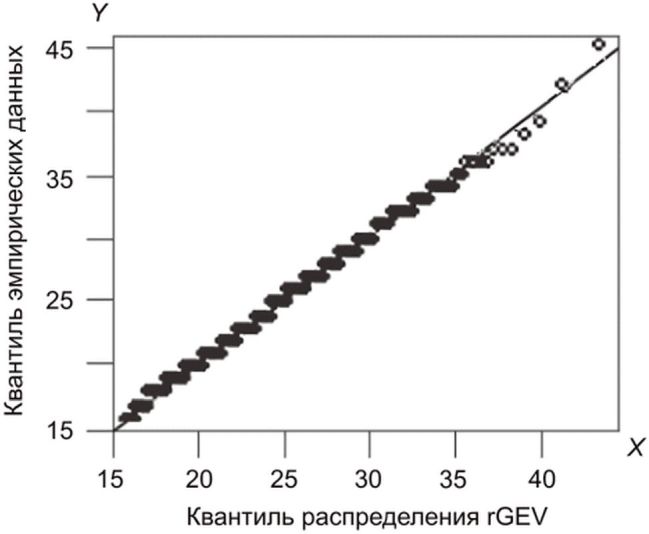
и эмпирических данных
5) Проведение анализа графика квантиль-квантиль для оценки пригодности полученной модели, особенно в области экстремальных значений (см. правый верхний угол графика).
6) Сравнение полученной модели и эмпирических значений
Выполняют построение расчетной кривой CDF с использованием модели rGEV и параметров, полученных на этапе 3), с 95% доверительным интервалом с обеих сторон. Построение эмпирических значений осуществляют на той же плоскости. Далее проводят анализ пригодности модели, особенно в области, где эмпирические значения недоступны.
7) Проверка реализуемости модели
Если оценка пригодна (см. 5.5), то переходят к следующему этапу. Если оценка не пригодна (см. 5.5), то выполняют этап 2) с другим значением r. Если ни одно значение r не дает пригодной оценки, то выполняют этап 1) с другим значением n.
8) Получение экстраполированной ВЛС
Экстраполированную ВЛС получают из расчетной кривой 1-CDF (см. рисунок 2 и приложение Б).
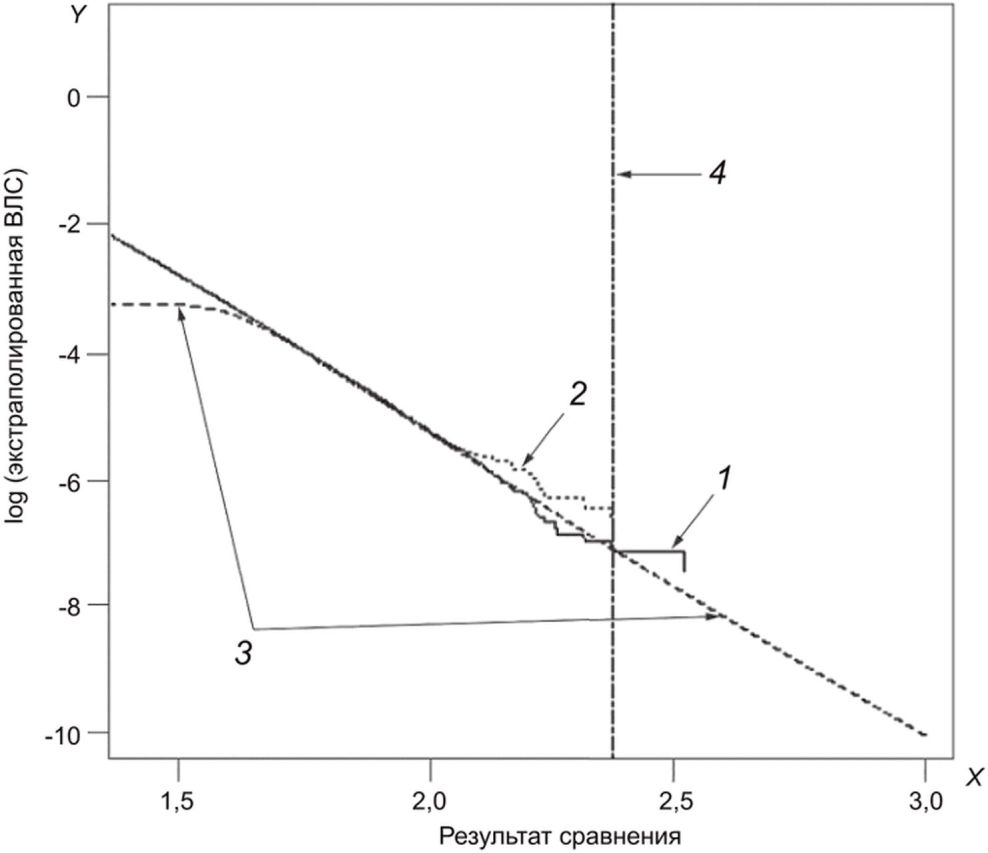
1 - эмпирические данные (все), 2 - эмпирические данные
(используемые для оценки), 3 - оценка rGEV,
4 - максимальное значение используемых для оценки
результатов сравнения
и экстраполированной ВЛС
Выбирают интересующие точки на расчетной кривой 1-CDF и протоколируют параметры m, n, r экстраполированной ВЛС и соответствующего доверительного интервала.
Оценка GP основана на модели GP, как описано в А.3. Этапы процесса оценки следующие:
1) Определение параметра местоположения 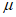
Для отбора используемых при применении модели GP экстремальных результатов сравнения из всего набора данных необходимо установить пороговое значение 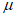 , которое получают путем оценки стабильности параметра масштаба
, которое получают путем оценки стабильности параметра масштаба 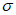 и параметра формы
и параметра формы 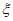 . На рисунке 3 показаны полученные с помощью MLE оптимальные значения параметра формы
. На рисунке 3 показаны полученные с помощью MLE оптимальные значения параметра формы 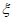 для соответствующих значений порога (оси Y и X соответственно).
для соответствующих значений порога (оси Y и X соответственно).
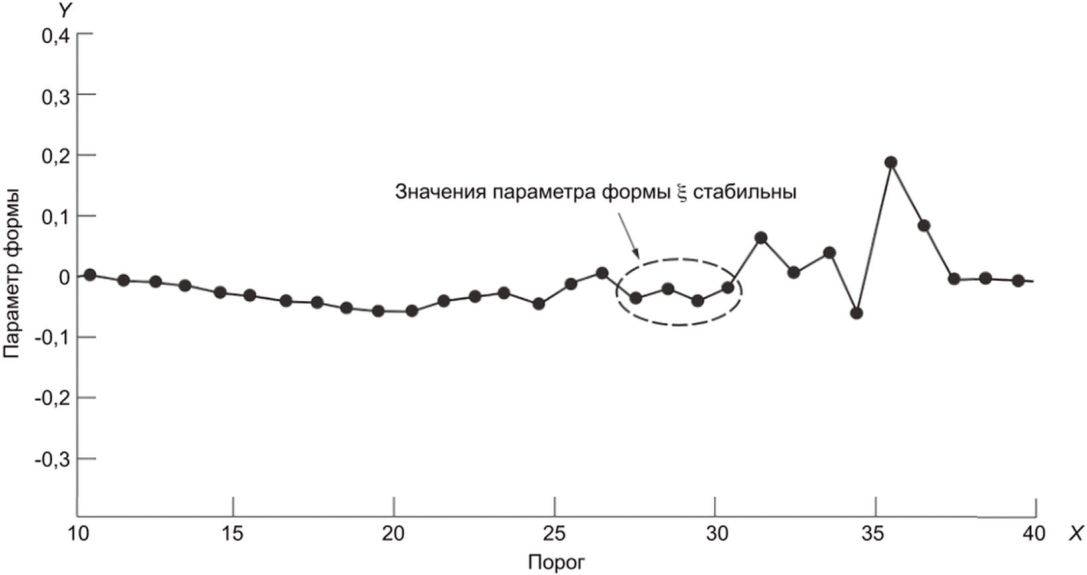
Параметр формы 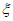 считают стабильным в обведенном диапазоне, а соответствующий порог рекомендуется выбрать из значений, близких к нижней границе диапазона. Таким же образом для нахождения значения
считают стабильным в обведенном диапазоне, а соответствующий порог рекомендуется выбрать из значений, близких к нижней границе диапазона. Таким же образом для нахождения значения 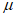 допускается использовать график зависимости параметра масштаба
допускается использовать график зависимости параметра масштаба 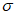 от порога.
от порога.
2) Оценка параметров 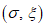 GP
GP
Распределение GP аппроксимируют к данным, превышающим определенное на этапе 1) пороговое значение 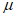 . Затем параметр масштаба
. Затем параметр масштаба 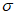 и параметр формы
и параметр формы 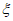 оценивают с использованием MLE.
оценивают с использованием MLE.
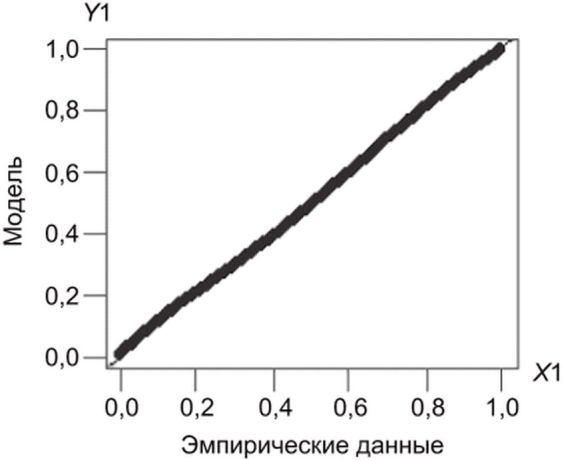
3) Диагностика модели GP
Для диагностики пригодности параметров оцененной модели GP в теории экстремальных значений, как правило, используют графики Q-Q. Пример графика QQ распределения GP и эмпирических данных для диагностики пригодности параметров оцененной модели приведен на рисунке 4.
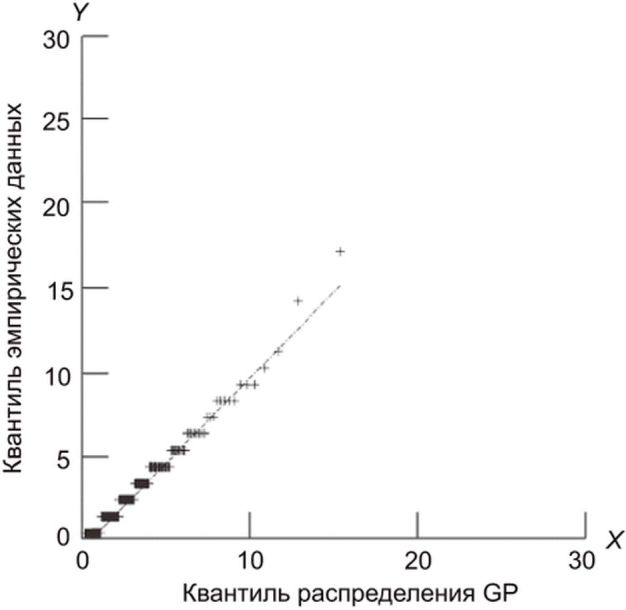
и эмпирических данных
4) Определение параметров модели GP
Если возникает проблема с диагностикой с помощью графика Q-Q, то пороговое значение выбирают повторно. Например, в некоторых таких случаях на графике Q-Q может быть четкое разделение относительно y = x.
CDF результатов непарного сравнения получают следующим образом. Значение менее порога 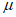 представляет собой распределение, полученное на основе эмпирических значений, а значение более порога
представляет собой распределение, полученное на основе эмпирических значений, а значение более порога 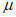 представляет собой GP. GP экстраполируют до степени, в которой фактические измерения отсутствуют. Каждое распределение масштабируют на основе соотношения количества результатов сравнения в измеренном значении, а CDF объединяют для получения CDF результатов непарного сравнения.
представляет собой GP. GP экстраполируют до степени, в которой фактические измерения отсутствуют. Каждое распределение масштабируют на основе соотношения количества результатов сравнения в измеренном значении, а CDF объединяют для получения CDF результатов непарного сравнения.
Далее выполняют расчет функции распределения вероятностей с использованием данных параметров и экстраполяцию диапазона без значений.
6) Получение экстраполированной ВЛС
Экстраполированную ВЛС получают из расчетной кривой 1-CDF (см. приложение Б).
Выбирают интересующую точку на графике, полученном на этапе 5), и протоколируют параметры 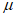 ,
,  ,
,  экстраполированной ВЛС и верхнее значение 95% доверительного интервала для экстраполированной ВЛС.
экстраполированной ВЛС и верхнее значение 95% доверительного интервала для экстраполированной ВЛС.
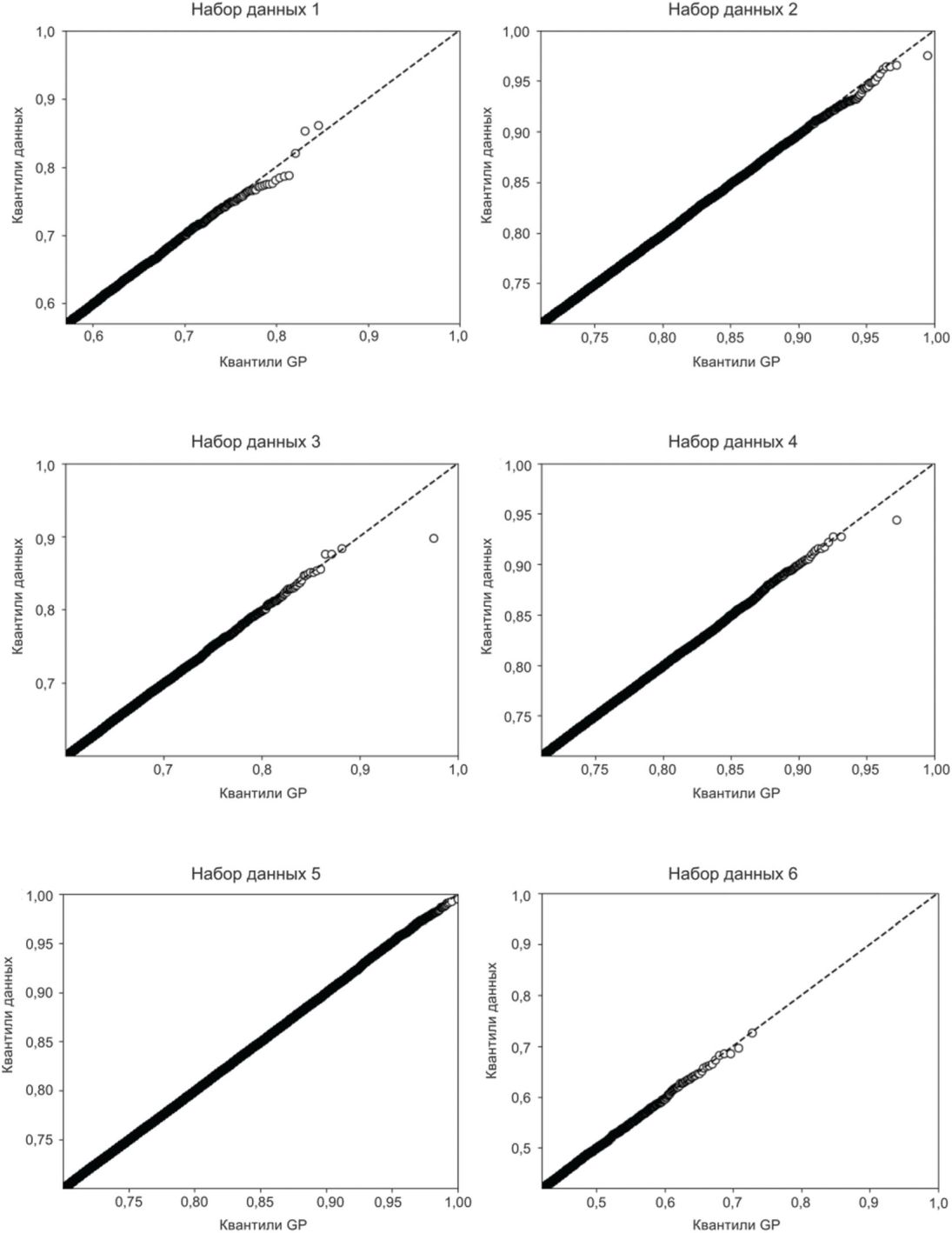
Пригодность модели оценивают с использованием графика Q-Q. График Q-Q представляет собой сравнение квантиль-квантиль между двумя распределениями, т.е. между расчетными и эмпирическими данными. Как следствие, нанесенные на график значения всегда монотонно увеличиваются. Если два распределения идентичны, то график Q-Q следует прямой Y = X, расположенной под углом 45°. Поскольку колебания нескольких верхних результатов сравнения существенно велики, графики этих оценок имеют тенденцию отклоняться от прямой Y = X. Поэтому требуется внимательно следить за отклонением между моделью оценки и эмпирическими данными, особенно в правом верхнем углу графика Q-Q. На рисунке 5 показаны два примера графиков Q-Q: для моделей с высоким и низким уровнем пригодности.
и низкой пригодности модели
Горизонтальная и вертикальная оси предназначены для расчетных и эмпирических результатов сравнения соответственно. Если график Q-Q почти совпадает с прямой Y = X во всем диапазоне результатов сравнения [см. рисунок 5, а)], то пригодность модели считают адекватной. Если график Q-Q не находится на линии Y = X [см. рисунок 5, б)], то пригодность модели недостаточно высока и, следовательно, результаты такой оценки не могут быть приняты. В этом случае следует пересмотреть параметры модели оценки или экспериментатор должен подтвердить, что набор данных не содержит ошибок (например, неправильную разметку).
5.6 Выбор между моделями rGEV и GP
5.6.1 Различия моделей rGEV и GP
Помимо математических моделей основное различие между двумя моделями rGEV и GP заключается в политике выбора образцов для оценки. В модели rGEV используют r наибольших результатов сравнения каждого блока и не применяют явный нижний предел для используемых значений. Число образцов определяют по параметрам r и m. В модели GP используют все образцы, для которых результат сравнения превышает выбранное пороговое значение  , и, следовательно, число образцов зависит от набора данных.
, и, следовательно, число образцов зависит от набора данных.
На рисунке 6 показаны образцы, используемые в моделях rGEV [см. рисунок 6, а)] и GP [см. рисунок 6, б)].
rGEV и GP
5.6.2 Особенности моделей rGEV и GP
Распределение исходных данных влияет на результат оценки, поэтому для конкретных данных одна модель может оказаться предпочтительнее другой.
Поскольку оценка rGEV основана на упорядоченной статистике, она более устойчива к постепенному изменению условий. Например, для некоторых биометрических модальностей свойственно увеличение степени схожести по мере повышения уровня ознакомления пользователя с биометрической системой. Модель rGEV основана на экстремальных значениях, выбранных по порядку в каждом блоке, а не на пороговом значении, поэтому число значений, используемых для оценки, остается неизменным. Модель GP зависит от всех значений, превышающих фиксированный порог, поэтому число значений, используемых для оценки, будет различным. Если набор данных представляет собой объединение подмножеств, созданных в разное время, например, 1-е посещение + 2-е посещение + 3-е посещение, то рекомендуется применять модель rGEV, поскольку в ней учитывают экстремальные значения каждого подмножества. Данная функция не работает, если порядок образцов в таком наборе данных рандомизирован.
Экспериментатор должен использовать одну модель или обе модели rGEV и GP и протоколировать результаты вместе с другой информацией, определенной в разделе 7.
Экстраполированную ВЛС определяют следующим образом:
1) Выполняют построение экстраполированной ВЛС на графике с показателем схожести по оси X в линейном масштабе и экстраполированной ВЛС по оси Y в логарифмическом масштабе.
2) Выполняют построение линии доверительного интервала 95% с обеих сторон графика экстраполированной ВЛС.
3) Доверительный интервал 95% рассчитывают по методу Монте-Карло. Осуществляют подготовку не менее 100 моделей, применив случайно сгенерированные параметры модели к выбранной модели экстремальных значений (т.е. 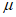 ,
, 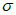 ,
, 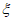 для rGEV и
для rGEV и 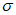 ,
, 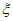 для GP). Случайные числа должны быть сгенерированы с помощью алгоритмов, разработанных для отражения распределения профиля правдоподобия каждого параметра. На график наносят верхнюю и нижнюю точки 2,5% процентиля с обеих сторон каждой экстраполированной ВЛС.
для GP). Случайные числа должны быть сгенерированы с помощью алгоритмов, разработанных для отражения распределения профиля правдоподобия каждого параметра. На график наносят верхнюю и нижнюю точки 2,5% процентиля с обеих сторон каждой экстраполированной ВЛС.
Примечание - Протоколирование наихудшего значения в доверительном интервале соответствует правилу трех.
4) Если экстраполированная ВЛС должна быть представлена в виде единой характеристики, то ее записывают в одном из следующих форматов:
а) верхнее 2,5% процентильное значение экстраполированной ВЛС при выбранном экспериментатором пороговом значении.
Пример - Экстраполированная ВЛС = 2,4 x 10-6 или менее с уровнем достоверности 95%;
б) экстраполированная ВЛС при выбранном экспериментатором пороговом значении с доверительным интервалом 95% для обеих сторон.
Пример - Экстраполированная ВЛС = 2,1 x 10-6 +/- 0,3 x 10-6 с уровнем достоверности 95%. Экстраполированная ВЛС = 2,1 x 10-6 [1,9 x 10-6; 2,2 x 10-6] при 95% доверительном интервале.
5) Если выбраны уровни достоверности, отличные от 95%, то соответствующая информация должна быть задокументирована.
Методы, использованные для получения эксплуатационных характеристик биометрической системы, должны быть зафиксированы в протоколе, включая статистические модели, параметры, диагностические диаграммы. Хранимой информации должно быть достаточно для воспроизведения оценки в условиях, максимально приближенных к оригиналу.
8.1 Протокол по результатам сравнения "один к одному"
Протокол должен содержать эксплуатационные характеристики, указанные в таблице 1.
Таблица 1
Эксплуатационная характеристика | Порог | Протоколирование | Содержание протокола |
Экстраполированная ВЛС | Соответствующий порог | Обязательно | См. раздел 6 |
ВЛНС | Соответствующий порог | Опционально | См. ГОСТ Р 71414.1 |
Примечание - Протоколирование ВЛНС осуществляют опционально, поскольку настоящий стандарт относится к применению теории экстремальных значений к ВЛС. | |||
8.2 Протокол по результатам оценки
Протокол должен содержать результаты оценки, указанные в таблице 2.
Таблица 2
Содержание оценки | Протоколирование | Содержание протокола |
Статистическая модель | Обязательно | Включая статистическую модель (rGEV, GP и т.п.), используемую для оценки |
Параметры | Обязательно | Включая параметры статистической модели: - в случае rGEV: - в случае GP: порог |
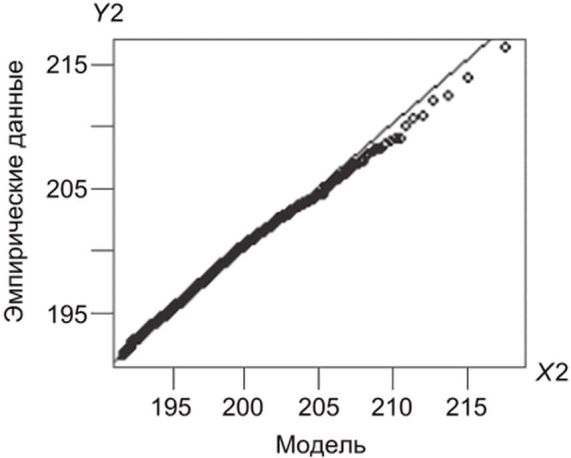
Диагностические графики | Обязательно | Включая графики Q-Q и другие релевантные графики, отражающие пригодность полученных результатов оценки. Примеры таких графиков показаны на рисунке 7 |
а) график вероятности
б) квантильный график
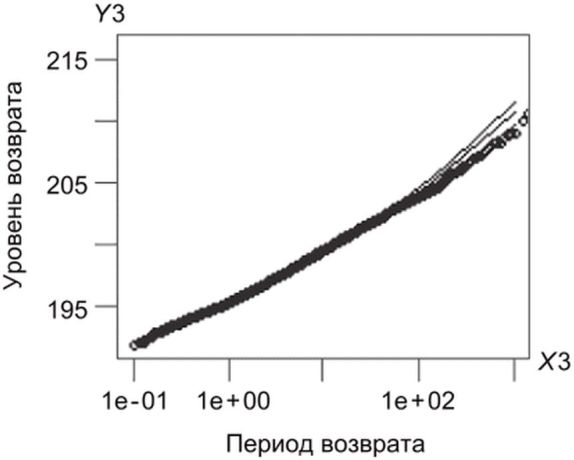
в) график уровня возврата
г) график плотности
8.3 Форма протокола
Результаты оценки должны быть задокументированы в соответствии с формой протокола, приведенной в таблице 3.
Таблица 3
Эксплуатационная характеристика | Порог | Протоколирование |
Экстраполированная ВЛС | Соответствующий порог | Обязательно |
Эмпирическая ВЛС | Соответствующий порог | Обязательно |
Эмпирическая ВЛНС | Соответствующий порог | Опционально |
Максимальный наблюдаемый результат непарного сравнения | - | Опционально |
Максимальный результат сравнения при более 30 случаев ложного совпадения | - | Опционально |
(обязательное)
А.1 Фундаментальные предпосылки
Теория экстремальных значений основана на следующих трех фундаментальных предпосылках:
1) Функция распределения вероятностей F(x) целевой выборки является невырожденным распределением.
В контексте экстраполированной оценки ВЛС биометрические системы, которые всегда возвращают постоянное значение результата сравнения, считают вырожденными, а распределение результатов сравнения для таких систем называют вырожденным распределением. В теории экстремальных значений требуется, чтобы целевая выборка имела невырожденное распределение, и поэтому экстраполированную ВЛС можно рассчитать только для невырожденных биометрических систем.
Вырожденное распределение в n-мерном евклидовом пространстве - это любое распределение вероятностей, имеющее опору на некотором (линейном) многообразии размерности менее n. В противном случае распределение называют невырожденным.
Пример одномерного вырожденного распределения показан на рисунке А.1.

2) Функция распределения вероятностей F(x) принадлежит области притяжения распределения экстремальных значений G(z), т.е. 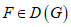 .
.
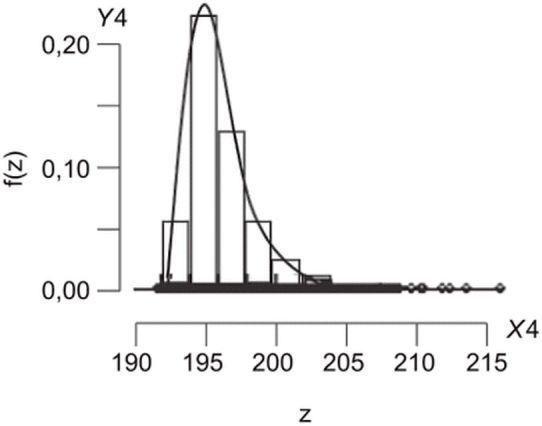
.В контексте оценки экстраполированной ВЛС, если правый конец гистограммы степеней схожести асимптотически приближается к нулю, то функцию распределения вероятностей, которой следует гистограмма, считают приблизительно принадлежащей к области притяжения. На рисунке А.2 показан пример функции распределения вероятностей, которая принадлежит области притяжения.
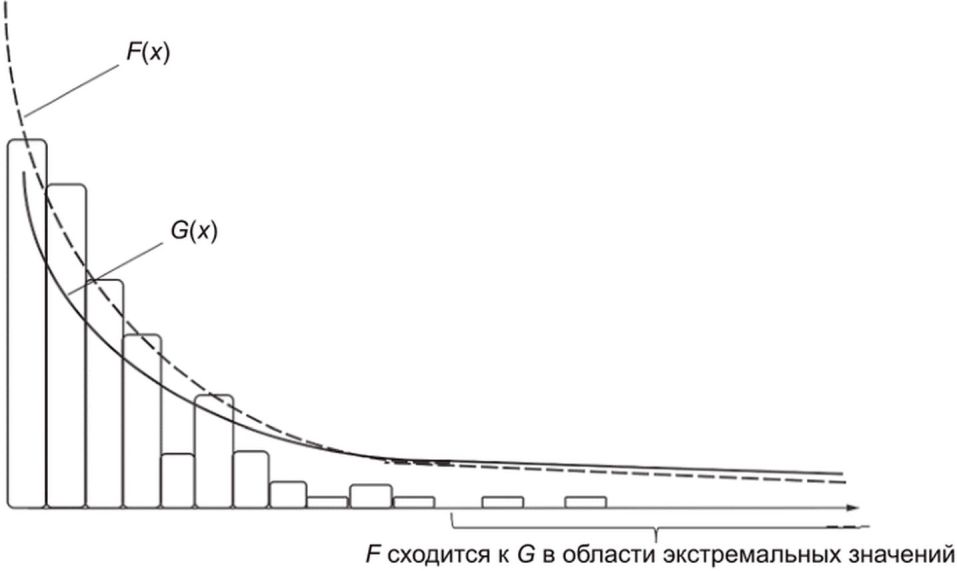
относящейся к области притяжения
Пусть X1, X2, ... Xn - независимые одинаково распределенные случайные величины, P - распределение вероятностей, F(x) = P(Xi <= x), i = 1, 2, ... - его идентичное распределение, а zn - экстремальная статистика, определенная по формуле
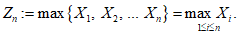 (А.1)
(А.1)Предположим, что случайная величина Z подчиняется невырожденному распределению G, и если существуют константы an > 0 и 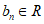 такие, что удовлетворяют формулам:
такие, что удовлетворяют формулам:
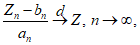 (А.2)
(А.2)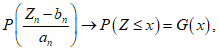 (А.3)
(А.3)где 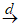 - сходимость в распределении;
- сходимость в распределении;
G(x) - распределение экстремальных значений.
Xi и Z имеют функции распределения F и G соответственно, поэтому утверждают, что F притягивается к G. Также утверждают, что F принадлежит области притяжения G, которую обозначают как 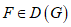 .
.
.3) Каждую попытку рассматривают как независимую и одинаково распределенную.
Независимые и одинаково распределенные случайные переменные - это независимые переменные, имеющие одинаковое распределение. Наиболее распространенная ситуация, связанная с независимыми одинаково распределенными случайными переменными, возникает, когда случайная выборка наблюдений представлена из одной совокупности.
Если распределение результатов сравнения целевой биометрической системы не удовлетворяет вышеуказанным фундаментальным предпосылкам, то методологию, установленную в настоящем стандарте, не применяют.
А.2.1 Подготовка
Обобщенное распределение экстремальных значений, также известное как GEV, представляет собой модель распределения экстремальных значений, используемую для оценки максимального значения, ожидаемого в определенный период времени в будущем. Для статистической оценки ВЛС в качестве экстремальных значений используют r наибольших значений за единицу периода (или "блока"). Такую статистическую модель называют моделью rGEV.
Каждая из попыток непарного сравнения независима и одинаково распределена, а x1, x2, ... xn обозначают результаты сравнения для попыток 1 ... n. Тогда xi для положительного целого числа i(1 <= i <= n) является вероятностной переменной, и следовательно идентичное распределение F(x) вычисляют по формуле
F(x) = P(Xi <= z), i = 1, 2, ... n, (А.4)
где P() - функция распределения вероятностей для распределения результатов непарного сравнения.
Набор экстремальных значений Zn является набором максимумов блока, который вычисляют по формуле
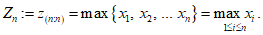 (А.5)
(А.5)Порядковую статистику Znr, состоящую из r наибольших значений, вычисляют по формуле
Znr := {z(n:n), z(n-1:n), z(n-2:n), ..., z(n-r+1:n)}. (А.6)
Максимумы блока Zn являются частным случаем Znr, когда r = 1, т.е. Zn1.
А.2.2 Модель rGEV
Для оценки ВЛС доступны n0 результатов непарного сравнения. Выбирают положительные целые числа m и n, такие что mn = n0, где m - число блоков, а n - число образцов в каждом блоке.
Набор результатов сравнения Znr, который состоит из лучших r степеней схожести из каждого блока, вычисляют по формуле
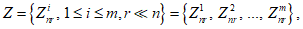 (А.7)
(А.7)где 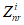 - набор результатов непарного сравнения Znr из i-го блока.
- набор результатов непарного сравнения Znr из i-го блока.
Размер блока m должен быть достаточно большим, чтобы в каждый блок были включены экстремальные значения. Значение r должно быть значительно меньше, чем n, поскольку r наибольших результатов сравнения в блоке считают экстремальными значениями. И m, и r (и следовательно n) необходимо выбирать исходя из диагностических графиков, описанных в 5.3. На рисунке А.3 показан пример блоков для оценки rGEV.
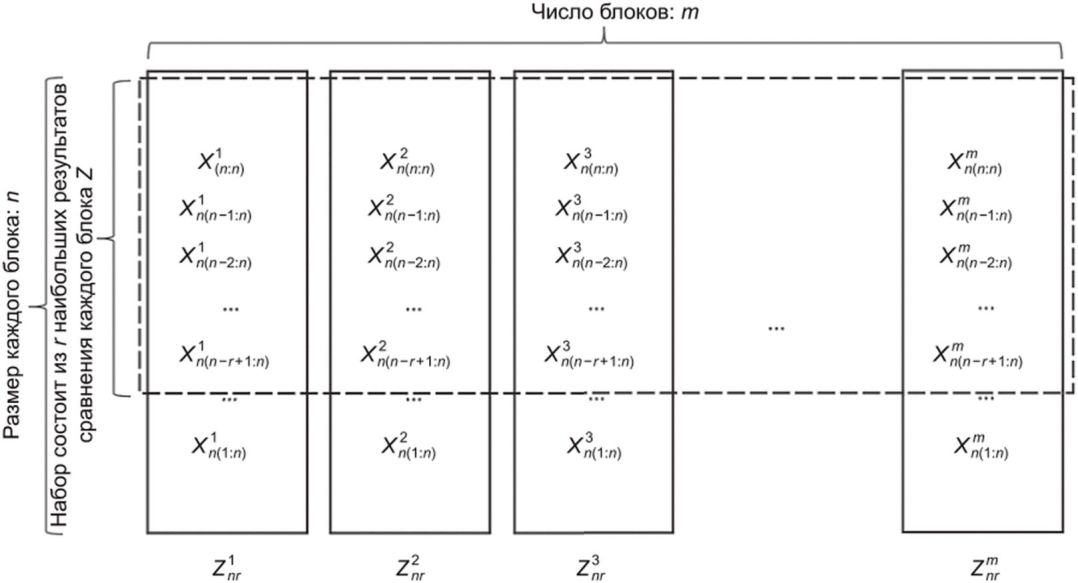
Модель rGEV адаптируют к экстремальным значениям оценок 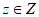 , а параметры модели, как правило, оценивают с использованием MLE. Обобщенное распределение экстремальных значений
, а параметры модели, как правило, оценивают с использованием MLE. Обобщенное распределение экстремальных значений 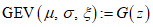 вычисляют по формуле
вычисляют по формуле
вычисляют по формуле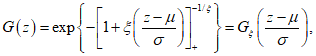 (А.8)
(А.8)где
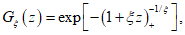 (А.9)
(А.9)(a)+ = max{a, 0}. (А.10)
Параметры 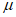 ,
, 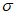 ,
, 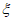 и являются параметрами местоположения, масштаба и формы соответственно. Эти параметры определяют расчетную функцию распределения вероятностей G(z), которую следует использовать для получения экстраполированной ВЛС в области экстремальных значений. Поиск G(z), которая наилучшим образом описывает реальную функцию распределения вероятностей в области экстремальных значений, сводят к оценке оптимизированных параметров
и являются параметрами местоположения, масштаба и формы соответственно. Эти параметры определяют расчетную функцию распределения вероятностей G(z), которую следует использовать для получения экстраполированной ВЛС в области экстремальных значений. Поиск G(z), которая наилучшим образом описывает реальную функцию распределения вероятностей в области экстремальных значений, сводят к оценке оптимизированных параметров 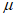 ,
, 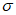 и
и 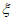 для заданных n и r.
для заданных n и r.
В контексте оценки ВЛС на основе экстраполяции результаты биометрического сравнения, которые значительно больше результатов для непарного сравнения, рассматривают как экстремальные значения, а вышеупомянутый "блок" рассматривают как единицу количества попыток непарного сравнения, которые являются взаимоисключающими подмножествами, выбранными из всего набора результатов непарного сравнения.
Распределение большого объема данных зависит от правого хвоста распределения выборки, поэтому для оценки правого хвоста распределения выборки с использованием данных, превышающих значительно большое пороговое значение, используют метод высшей надпороговой точки. В настоящем приложении приведены статистическая модель и метод анализа данных, превышающих пороговое значение.
Данные, превышающие порог {x1, x2, ... xn}, представляют собой измеренные значения случайных величин, которые следуют обобщенному распределению Парето независимо и одинаково. Обобщенное распределение Парето имеет кумулятивную функцию распределения, которую вычисляют по формуле
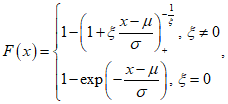 (А.11)
(А.11)где 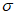 - параметр масштаба для обобщенного распределения Парето,
- параметр масштаба для обобщенного распределения Парето,
Эти параметры можно получить, используя MLE и соответствующее программное обеспечение.
Для того, чтобы с высокой точностью выполнить анализ данных в обобщенном распределении Парето, необходимо выбрать оптимальный порог 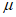 . Чем меньше порог, тем больше данных превышает порог, но тем ниже соответствие обобщенному распределению Парето. Таким образом, дисперсия оценки уменьшается, а смещение увеличивается. С другой стороны, чем больше порог, тем меньше данных, но тем выше соответствие обобщенному распределению Парето. Смещение оценки уменьшается, а дисперсия увеличивается. В данном методе возможны ошибки двух типов: ошибки, связанные с тем, что обобщенное распределение Парето является приблизительным распределением, которое следует применять к пороговым избыточным данным, и ошибки, связанные с оценкой. Порог следует выбирать с учетом этих факторов.
. Чем меньше порог, тем больше данных превышает порог, но тем ниже соответствие обобщенному распределению Парето. Таким образом, дисперсия оценки уменьшается, а смещение увеличивается. С другой стороны, чем больше порог, тем меньше данных, но тем выше соответствие обобщенному распределению Парето. Смещение оценки уменьшается, а дисперсия увеличивается. В данном методе возможны ошибки двух типов: ошибки, связанные с тем, что обобщенное распределение Парето является приблизительным распределением, которое следует применять к пороговым избыточным данным, и ошибки, связанные с оценкой. Порог следует выбирать с учетом этих факторов.
Некоторые методы выбора порога основаны на свойствах обобщенного распределения Парето, например, x обозначает данные, превышающие значение 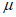 , и xmax обозначает максимальное значение данных. Для
, и xmax обозначает максимальное значение данных. Для 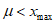 обобщенное распределение Парето аппроксимируют к данным
обобщенное распределение Парето аппроксимируют к данным 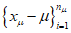 , превышающим
, превышающим 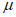 , для получения оценок максимального правдоподобия
, для получения оценок максимального правдоподобия 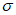 и
и 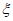 . Путем изменения порога
. Путем изменения порога 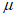 строят графики
строят графики 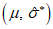 и
и 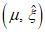 , где
, где 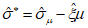 - оценка поправочного коэффициента. Если оцененные значения
- оценка поправочного коэффициента. Если оцененные значения 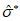 и
и 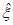 предполагают постоянными справа от определенного значения на этих двух графиках, то минимум этих значений
предполагают постоянными справа от определенного значения на этих двух графиках, то минимум этих значений 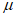 определяют как порог.
определяют как порог.
обобщенное распределение Парето аппроксимируют к данным , превышающим и - оценка поправочного коэффициента. Если оцененные значения (справочное)
К НАБОРАМ ДАННЫХ С РАЗНЫМИ МОДАЛЬНОСТЯМИ
Б.1 Общие положения
В настоящем приложении представлены примеры применения статистических моделей rGEV и GP к наборам биометрических данных, представляющих различные модальности. Целью настоящего приложения является предоставление базовой информации для использования методологии оценки с теорией экстремальных значений. В настоящем приложении приведены только примеры применения статистических моделей для наборов результатов сравнения для различных модальностей и не показаны характеристики каждой модальности.
В соответствии с ГОСТ Р 71414.1 показатели точности, такие как ВЛС или ВЛНС, рассчитывают на основе правила тридцати или правила трех. При применении правила тридцати требуется, чтобы объем испытания был достаточно большим, чтобы число ошибок при заданном пороговом значении было не менее 30. При использовании правила трех определяют минимальный объем испытания, необходимый для заданной ВЛС или ВЛНС, и обеспечивают отсутствие ошибок. Эти показатели точности представляют собой статистические оценки, основанные на всех доступных результатах сравнения с заранее определенными уровнями достоверности.
Экстраполированная ВЛС предназначена для оценки вероятности ложного совпадения, даже если доступный объем испытания незначительный, чтобы удовлетворить вышеупомянутым правилам. Экстраполированная ВЛС - это статистическая оценка, основанная только на результатах сравнения, выходящих за пределы определенного порогового значения, или на результатах сравнения, находящихся в пределах r наибольших результатов сравнения в блоке. Уровень достоверности оценки должен быть задокументирован вместе с соответствующими доверительными интервалами.
Б.2 Наборы данных и протокол испытаний
В таблице Б.1 приведена информация о наборах данных результатов непарного сравнения, используемых при применении метода оценки. Набор данных для испытания получен путем случайного извлечения данных в небольших количествах (10% или 20%) из всех данных результатов сравнения. К этим данным применены модели rGEV и GP, а оценка соответствия rGEV и GP выполнена с помощью графика Q-Q. Если оцененная модель является пригодной, то рассчитывают экстраполированную ВЛС. Экстраполированную ВЛС сравнивали с ВЛС, измеренной на основе всех результатов сравнения. Если аппроксимация с использованием rGEV или GP не подходила для 10% испытуемых данных, то оценку выполняли путем увеличения числа значений до 20%.
Таблица Б.1
Биометрическая модальность | Набор данных результатов сравнения | Число сравнений |
Лицо | Idiap BIOSCOTE 2014, Face Recognition Grand Challenge v2.0 | 4 000 000 |
Походка | Osaka University, Gait Energy Image (GEI) 13.73 million | 13 730 000 |
Искусственно сгенерированные данные | 4 000 000 | |
Б.3 Примеры применения статистических моделей к наборам данных
На рисунках Б.1 - Б.15 показаны результаты применения моделей rGEV и GP к набору данных FRGC. 20% результатов сравнения (приблизительно 800 000 значений) были случайным образом извлечены из всех данных, и к ним были применены модели rGEV и GP. На рисунке Б.1 показана гистограмма результатов непарного сравнения набора данных FRGC.
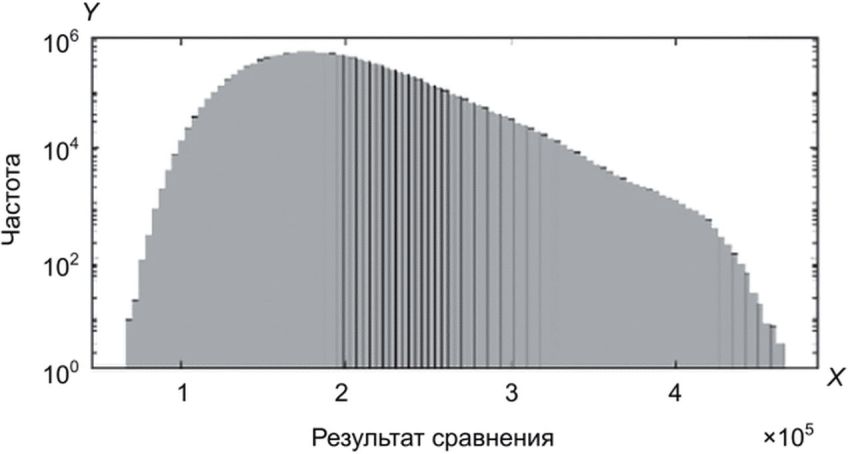
данных FRGC
На рисунке Б.2 показан график Q-Q при аппроксимации с помощью модели rGEV.
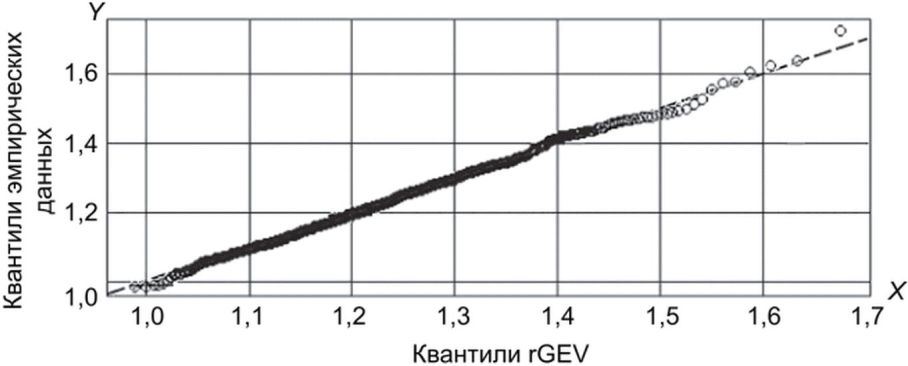
модели rGEV
На рисунке Б.3 показано сравнение экстраполированной ВЛС, оцененной с помощью модели rGEV, и эмпирической ВЛС.
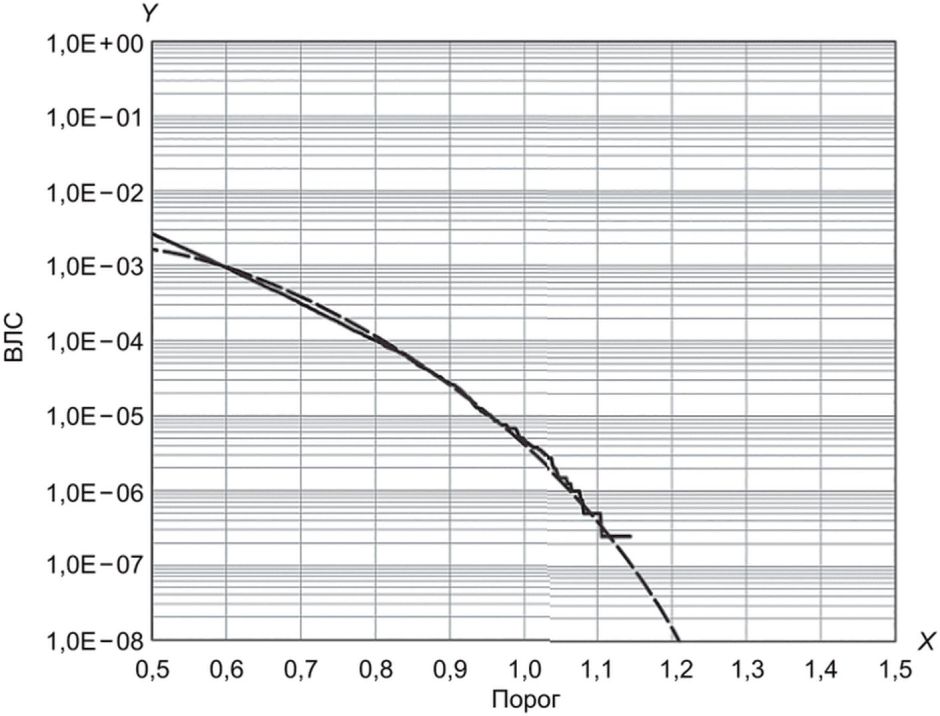
с помощью модели rGEV, и эмпирической ВЛС
На рисунках Б.4 и Б.5 показаны аналогичные результаты с применением модели GP.
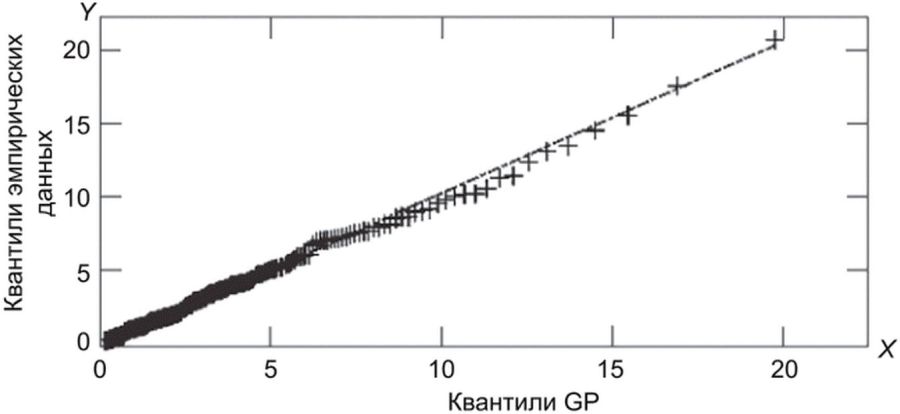
модели GP
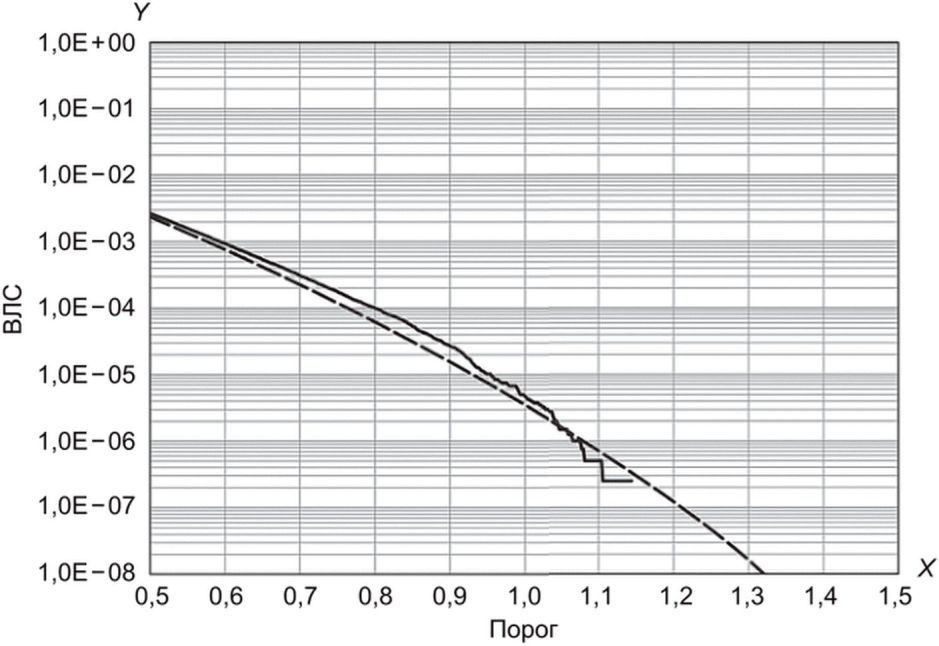
с помощью модели GP, и эмпирической ВЛС
В таблице Б.2 приведены параметры моделей rGEV и GP для данных FRGC. Графики Q-Q расположены рядом с прямой Y = X, и правый конец распределения результатов сравнения может быть аппроксимирован с помощью моделей rGEV и GP. Для набора данных FRGC ВЛС для всех данных можно оценить по 20% значений.
Таблица Б.2
Модель | Параметр | Значение |
rGEV | 59,5576 | |
4,6540 | ||
-0,0727 | ||
n | 500 | |
r | 1 | |
GP | 66,5 | |
4,4605 | ||
-0,1018 |
На рисунках Б.6 - Б.10 показаны результаты, полученные с применением моделей rGEV и GP, для набора данных GEI. 10% результатов сравнения (приблизительно 1 370 000) извлечены случайным образом. Графики Q-Q расположены вблизи прямой Y = X, а правый хвост распределения результатов сравнения аппроксимирован с применением моделей rGEV и GP. Для данных GEI ВЛС для всех результатов сравнения можно оценить по 10% результатов. На рисунке Б.6 показана гистограмма результатов непарного сравнения данных GEI.
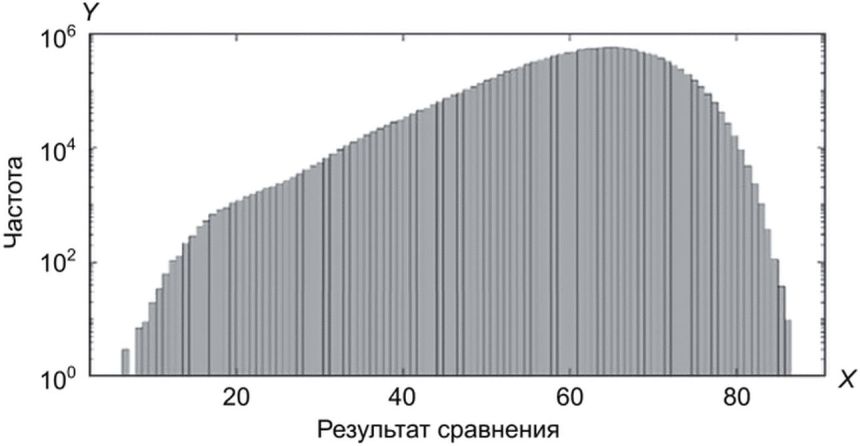
данных GEI
На рисунке Б.7 показан график Q-Q при аппроксимации с помощью модели rGEV.
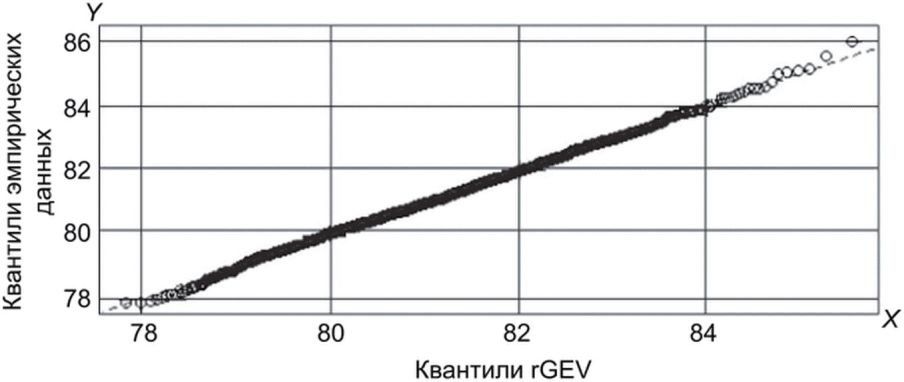
модели rGEV
На рисунке Б.8 показано сравнение экстраполированной ВЛС, оцененной с помощью модели rGEV, и эмпирической ВЛС.
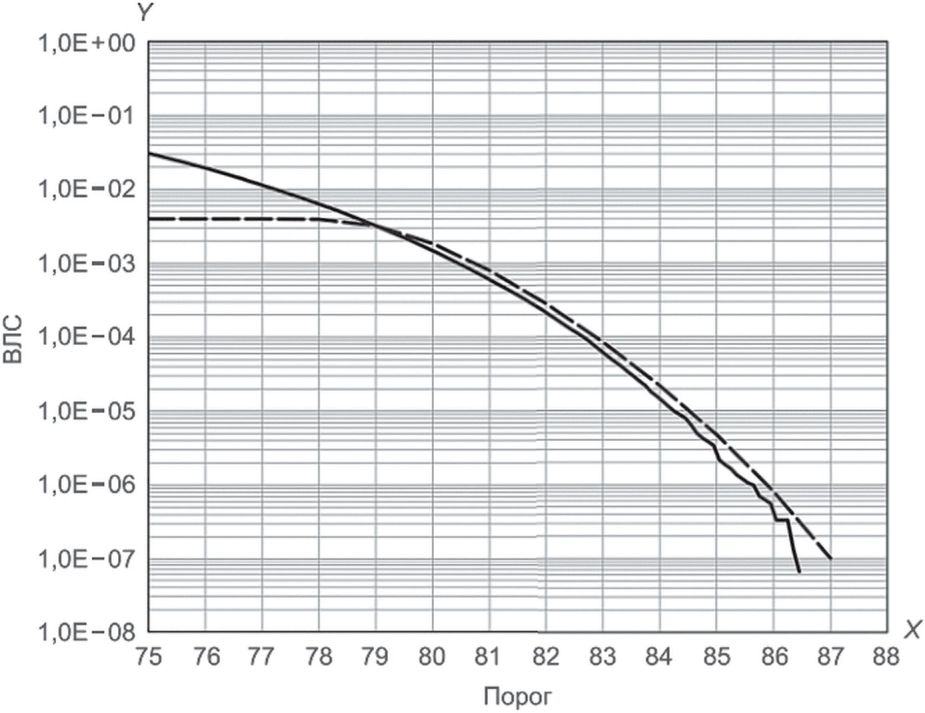
с помощью модели rGEV, и эмпирической ВЛС
На рисунках Б.9 и Б.10 показаны аналогичные результаты с применением модели GP.
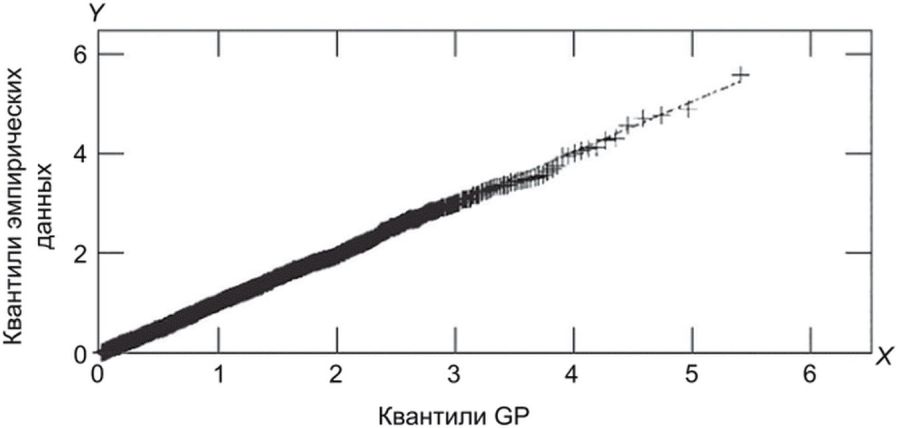
модели GP
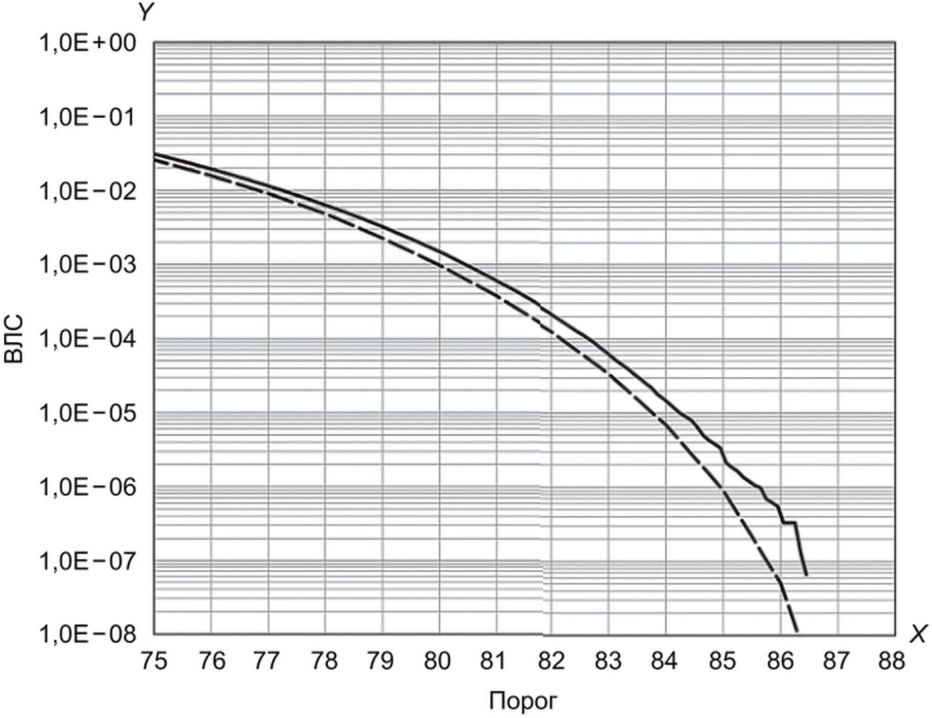
с помощью модели GP, и эмпирической ВЛС
На рисунке Б.10 пунктирная линия находится немного ниже сплошной линии, поскольку подмножество, случайно извлеченное для испытания, находится ниже всего набора.
В таблице Б.3 приведены параметры моделей rGEV и GP для данных GEI.
Таблица Б.3
Модель | Параметр | Значение |
rGEV | 80,5140 | |
1,1534 | ||
-0,1544 | ||
n | 1000 | |
r | 1 | |
GP | 80,5 | |
1,0941 | ||
-0,1159 |
На рисунках Б.11 - Б.15 показаны результаты, полученные с применением моделей rGEV и GP, для 6 наборов искусственно сгенерированных данных. 20% степеней схожести (800 000 значений) извлечены случайным образом. Для всех наборов данных графики Q-Q расположены вблизи прямой Y = X, а правый хвост распределения результатов сравнения аппроксимирован с применением моделей rGEV и GP. На рисунке Б.11 показаны гистограммы результатов непарного сравнения искусственно сгенерированных данных.
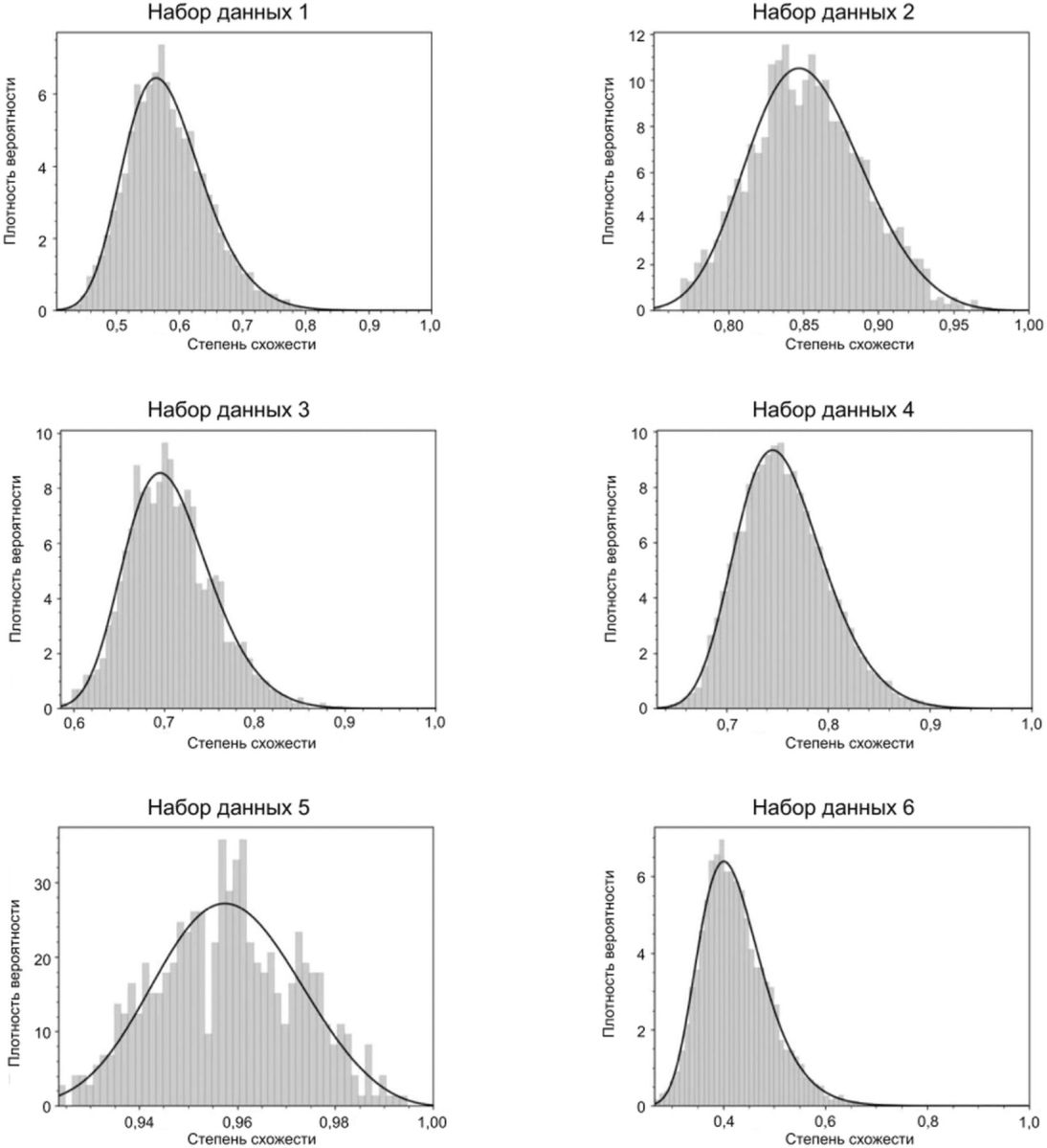
искусственно сгенерированных данных
На рисунке Б.12 показаны графики Q-Q при аппроксимации с помощью модели rGEV.
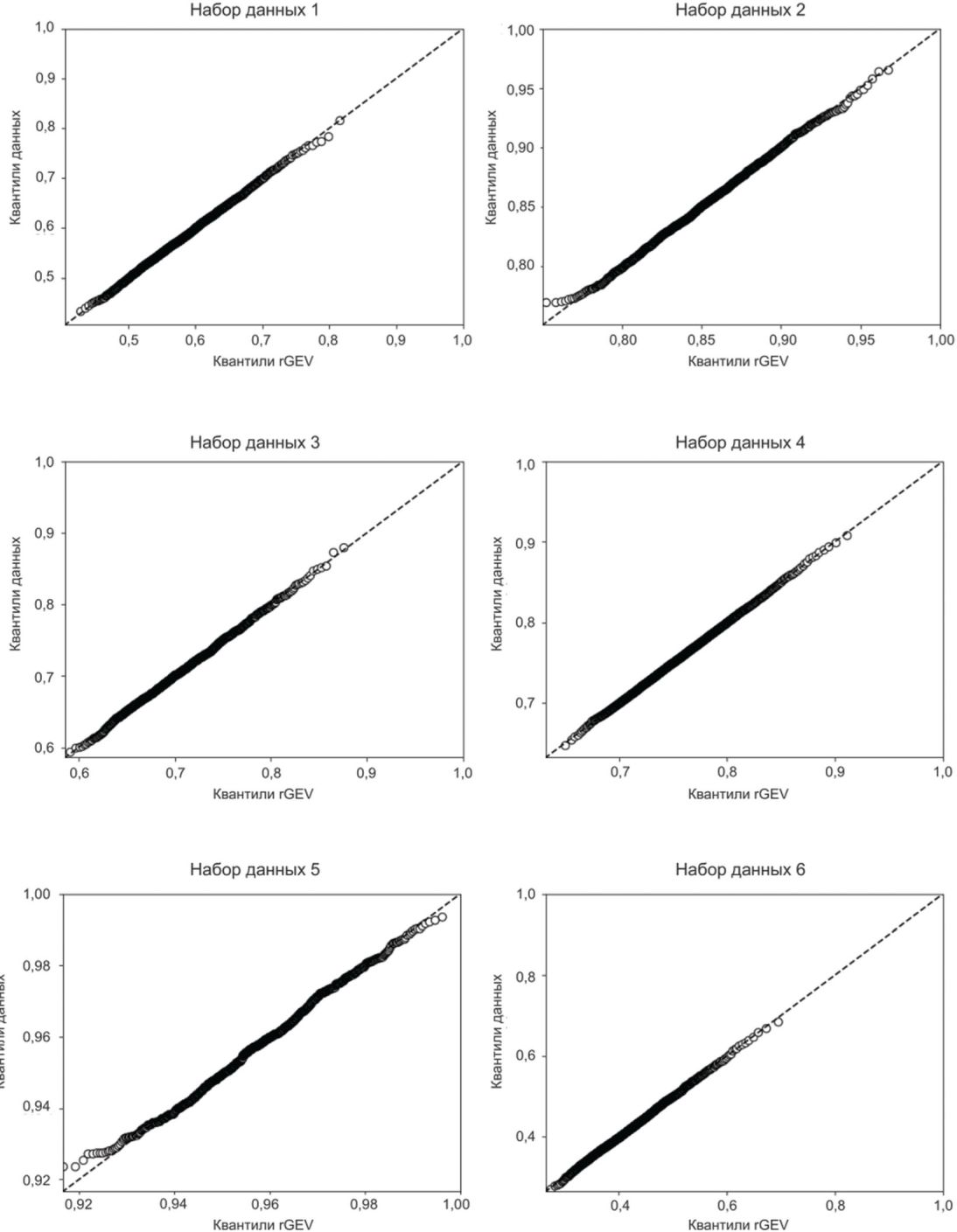
модели rGEV
На рисунке Б.13 показано сравнение экстраполированной ВЛС, оцененной с помощью модели rGEV, и эмпирической ВЛС для набора данных с 800 000 значений и исходного набора данных с 4 000 000 значений.
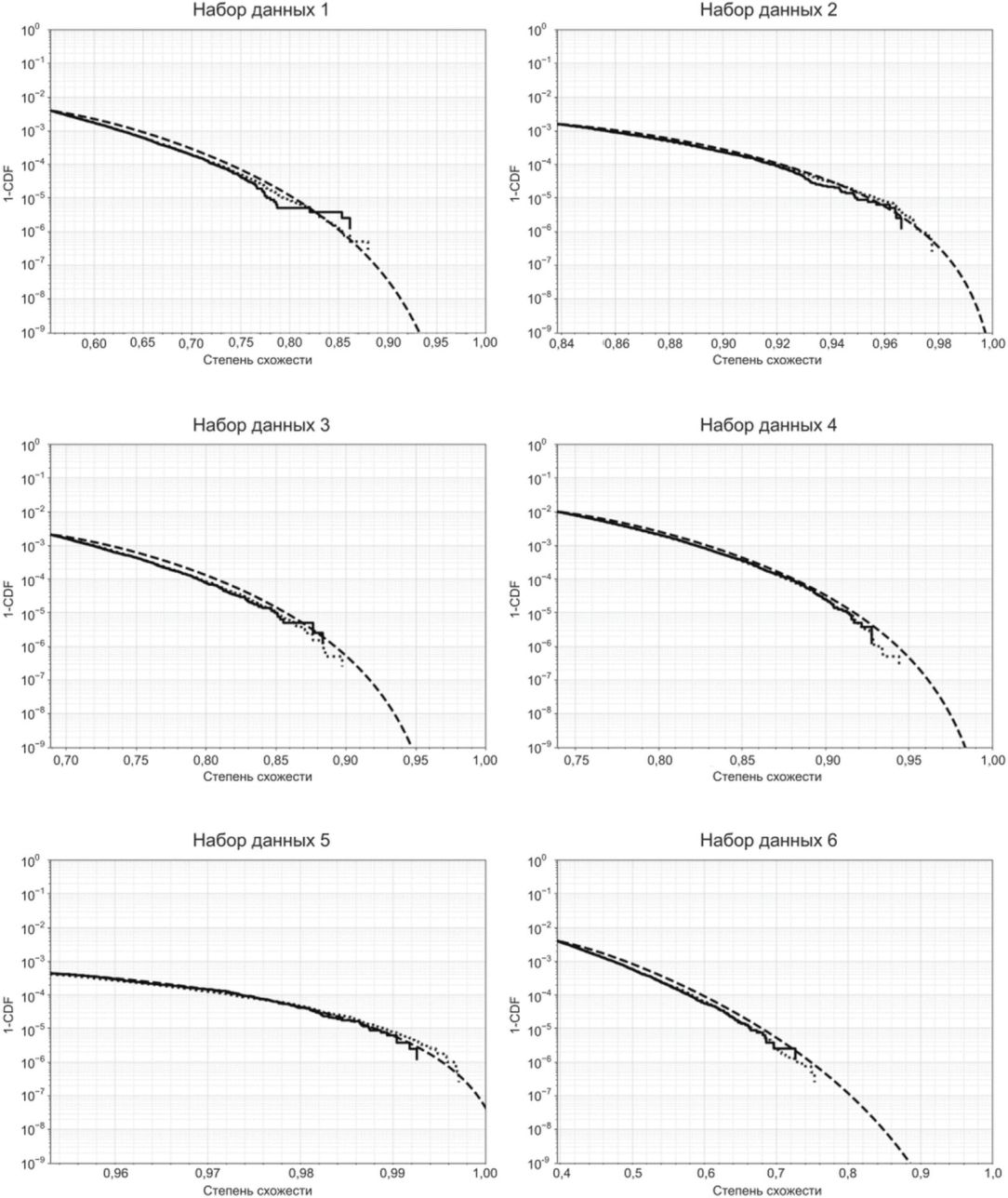
с помощью модели rGEV (штриховая линия), и эмпирической ВЛС
для набора данных с 800 000 значений (сплошная линия)
и исходного набора данных с 4 000 000 значений
(пунктирная линия)
На рисунках Б.14 и Б.15 показаны аналогичные результаты с применением модели GP.
модели GP
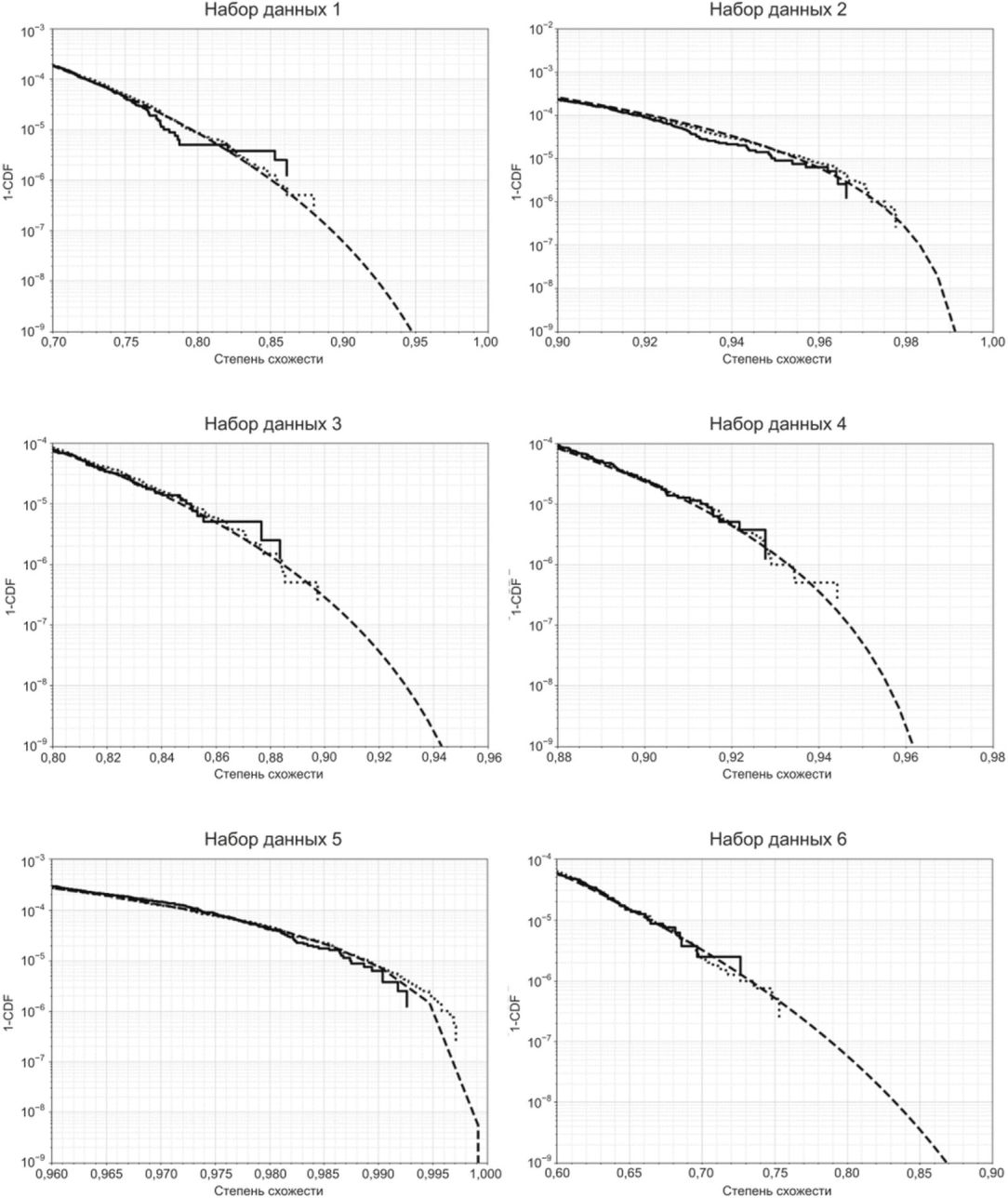
с помощью модели GP (штриховая линия), и эмпирической ВЛС
для набора данных с 800 000 значений (сплошная линия)
и исходного набора данных с 4 000 000 значений
(пунктирная линия)
В таблице Б.4 приведены параметры моделей rGEV и GP для искусственно сгенерированных данных.
Таблица Б.4
сгенерированных данных
Модель | Параметр | Значение | |||||
Набор данных 1 | Набор данных 2 | Набор данных 3 | Набор данных 4 | Набор данных 5 | Набор данных 6 | ||
rGEV | 0,5556 | 0,8386 | 0,6887 | 0,7393 | 0,9530 | 0,3958 | |
0,0577 | 0,0359 | 0,0436 | 0,0399 | 0,0142 | 0,0579 | ||
0,1344 | 0,2167 | 0,1513 | 0,1493 | 0,2813 | 0,0887 | ||
n | 256 | 1000 | 500 | 160 | 6250 | 250 | |
r | 1 | 2 | 1 | 2 | 4 | 1 | |
GP | 0,57 | 0,71 | 0,6 | 0,71 | 0,7 | 0,42 | |
0,0549 | 0,0765 | 0,0567 | 0,0509 | 0,1191 | 0,0566 | ||
-0,1216 | -0,2689 | -0,1513 | -0,1944 | -0,3976 | -0,0954 | ||
УДК 004.738:006.354 | ОКС 35.240.15 |
Ключевые слова: биометрия, статистическая модель, эксплуатационные характеристики биометрических систем, распределение обобщенных экстремальных значений, обобщенное распределение Парето | |