СПРАВКА
Источник публикации
М.: Стандартинформ, 2015
Примечание к документу
Документ введен в действие с 1 февраля 2016 года.
Название документа
"ГОСТ Р ИСО/МЭК 18004-2015. Национальный стандарт Российской Федерации. Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code"
(утв. и введен в действие Приказом Росстандарта от 03.06.2015 N 544-ст)
"ГОСТ Р ИСО/МЭК 18004-2015. Национальный стандарт Российской Федерации. Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code"
(утв. и введен в действие Приказом Росстандарта от 03.06.2015 N 544-ст)
Содержание
Приказом Федерального
агентства по техническому
регулированию и метрологии
от 3 июня 2015 г. N 544-ст
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
ТЕХНОЛОГИИ АВТОМАТИЧЕСКОЙ ИДЕНТИФИКАЦИИ И СБОРА ДАННЫХ
СПЕЦИФИКАЦИЯ СИМВОЛИКИ ШТРИХОВОГО КОДА QR CODE
Information technology. Automatic identification and data
capture techniques. QR Code bar code symbology specification
ISO/IEC 18004:2015
Information technology - Automatic identification and data
capture techniques - QR Code bar code
symbology specification
(IDT)
ГОСТ Р ИСО/МЭК 18004-2015
ОКС 35.040
Дата введения
1 февраля 2016 года
1 ПОДГОТОВЛЕН Ассоциацией автоматической идентификации "ЮНИСКАН/ГС1 РУС" совместно с Обществом с ограниченной ответственностью (ООО) НПЦ "Интелком" на основе аутентичного перевода стандарта, указанного в пункте 4, выполненного ООО НПЦ "Интелком"
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 355 "Технологии автоматической идентификации и сбора данных"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 3 июня 2015 г. N 544-ст
4 Настоящий стандарт идентичен международному стандарту ИСО/МЭК 18004:2015 "Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code" (ISO/IEC 18004:2015 "Information technology - Automatic identification and data capture techniques - QR Code bar code symbology specification"), за исключением приложения ДА, содержащего сведения о наборах знаков по ИСО/МЭК 646, ИСО/МЭК 8859-1 и ИСО/МЭК 8859-5 и приложения ДБ, содержащего сведения о соответствии ссылочных международных стандартов ссылочным национальным стандартам.
ИС МЕГАНОРМ: примечание. В официальном тексте документа, видимо, допущена опечатка: приложение ДВ отсутствует. Возможно, имеется в виду приложение ДБ. |
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных стандартов соответствующие им национальные стандарты, сведения о которых приведены в дополнительном приложении ДВ
5 Некоторые положения международного стандарта, указанного в пункте 4, могут являться объектами получения патентных прав. Международная организация по стандартизации (ИСО) не несет ответственности за идентификацию некоторых или всех подобных прав
6 ВВЕДЕН ВПЕРВЫЕ
Правила применения настоящего стандарта установлены в ГОСТ Р 1.0-2012 (раздел 8). Информация об изменениях к настоящему стандарту публикуется в ежегодном (по состоянию на 1 января текущего года) информационном указателе "Национальные стандарты", а официальный текст изменений и поправок - в ежемесячном информационном указателе "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ближайшем выпуске информационного указателя "Национальные стандарты". Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте национального органа Российской Федерации по стандартизации в сети Интернет (www.gost.ru)
Необходимо различать четыре различных с технической точки зрения представителя семейства символики QR Code, которые, однако, тесно связаны друг с другом и представляют собой следующую эволюционную последовательность:
- QR Code Model 1 - первоначальная спецификация QR Code, описание которой приведено в AIM ITS 97-001 Международная спецификация символики. QR Code (International Symbology Specification - QR Code);
- QR Code Model 2 - расширенная форма символики с дополнительными свойствами (прежде всего дополнение символа направляющими шаблонами для более точной навигации по большим символам), которая стала основой для первой версии ИСО/МЭК 18004 <*>;
- QR Code (основа для второй версии ИСО/МЭК 18004 <**> символика, в значительной степени соответствующая QR Code Model 2; отличающаяся от этого формата QR Code дополнительными параметрами для символов, представленных в зеркальном отображении инвертированного изображения (светлые символы на темном фоне), а также опциями, используемыми для определения альтернативных наборов знаков, отличающихся от набора знаков по умолчанию;
- формат Micro QR Code (установленный во второй версии ИСО/МЭК 18004), являющийся вариантом QR Code с уменьшенным числом служебных модулей и ограниченным диапазоном размеров, позволяющим представлять малые объемы данных в символах небольшого размера, особенно подходящих для прямого маркирования деталей и компонентов и для применений с ограниченным пространством для размещения символа.
--------------------------------
QR Code - матричная символика. Символ состоит из массива номинально квадратных модулей, структурированных в регулярную квадратную матрицу, включая уникальные шаблоны поиска, размещенные в трех углах символа (в Micro QR Code - только в одном углу) и предназначенные для упрощения определения места нахождения, размера и наклона символа. Предусмотрен широкий диапазон размеров и четыре уровня исправления ошибок. Размер символа в модулях устанавливает пользователь для обеспечения производства символов различными методами.
Символы QR Code Model 2 полностью совместимы с системами, считывающими символы QR Code.
Символы QR Code Model 1 рекомендуется использовать только в замкнутых применениях, и нет необходимости в поддержке формата QR Code Model 1 для оборудования, соответствующего настоящему стандарту. Поскольку символы QR Code рекомендуется в качестве образца для использования во вновь создаваемых и открытых системах применения QR Code, в настоящем стандарте приведено полное описание символов QR Code, также в приложении N приведен перечень отличий символов QR Code Model 1 от символов QR Code.
Сноски в тексте стандарта, выделенные курсивом, приведены для пояснения текста оригинала.
Настоящий стандарт устанавливает требования к символике QR Code <1>, а также параметры символики, методы кодирования знаков данных, форматы символов, требования к размерам, правила исправления ошибок, рекомендуемый алгоритм декодирования, требования к качеству производства, выбираемые пользователем параметры применения.
--------------------------------
<1> Наименование символики произносится как Кюар Код; аббревиатура QR расшифровывается как quick response, что в переводе на русский язык означает быстрый отклик.
Символы QR Code (и оборудование, предназначенное для создания или считывания символов QR Code) соответствуют требованиям настоящего стандарта, если они обеспечивают или поддерживают параметры, приведенные в настоящем стандарте.
Символы, созданные в соответствии с требованиями QR Code Model 1 по ИСО/МЭК 18004:2006, не могут быть считаны с помощью оборудования, соответствующего настоящему стандарту.
Символы, созданные в соответствии с требованиями QR Code Model 2 по ИСО/МЭК 18004:2000, считывают с помощью оборудования, соответствующего настоящему стандарту.
Символы, созданные в соответствии с требованиями настоящего стандарта, не могут быть считаны с помощью оборудования по ИСО/МЭК 18004:2000. Символы, которые используют дополнительные параметры QR Code, также не могут быть считаны с помощью такого оборудования.
Символы, созданные в соответствии с требованиями настоящего стандарта, не могут быть напечатаны с помощью оборудования, соответствующего требованиям предыдущей версии ИСО/МЭК 18004:2000. Символы, которые используют дополнительные параметры QR Code, также не могут быть напечатаны с помощью такого оборудования.
Разновидности символики QR Code Model 2 и Micro QR Code рекомендуется использовать для открытых систем и вновь создаваемых применений.
В настоящем стандарте использованы нормативные ссылки на следующие стандарты и другие нормативные документы, которые необходимо учитывать при использовании настоящего стандарта. В случае ссылок на документы, у которых указана дата утверждения, необходимо пользоваться только указанной редакцией. В случае, когда дата утверждения не приведена, следует пользоваться последней редакцией ссылочных документов, включая любые поправки и изменения к ним:
ИСО/МЭК 8859-1:1998 <2> Информационные технологии. 8-битовые однобайтовые наборы кодированных графических знаков. Часть 1. Латинский алфавит N 1 (Information technology - 8-bit single-byte coded graphic character sets - Part 1: Latin alphabet No. 1)
--------------------------------
<2> Набор знаков приведен в приложении ДА.
ИСО/МЭК 15415 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация испытаний символов штрихового кода для оценки качества печати. Двумерные символы (Information technology - Automatic identification and data capture techniques - Bar code print quality test specification - Two-dimensional symbols)
ИСО/МЭК 19762-1 Информационные технологии. Технологии автоматической идентификации и сбора данных (АИСД). Гармонизированный словарь. Часть 1. Общие термины, связанные с автоматической идентификацией и сбором данных (Information technology - Automatic identification and data capture (AIDC) techniques - Harmonized vocabulary - Part 1: General terms relating to AIDC)
ИСО/МЭК 19762-2 Информационные технологии. Технологии автоматической идентификации и сбора данных (АИСД). Гармонизированный словарь. Часть 2. Оптические носители данных (ОНД) (Information technology - Automatic identification and data capture (AIDC) techniques - Harmonized vocabulary - Part 2: Optically readable media (ORM))
JIS X 0201 7-битовые и 8-битовые наборы знаков для обмена информацией (7-bit and 8-bit coded character sets for information interchange)
В настоящем стандарте применяются термины, определенные в ИСО/МЭК 19762-1, ИСО/МЭК 19762-2, а также следующие:
4.1 индикатор числа знаков (character count indicator): Битовая последовательность, определяющая длину строки данных в текущем режиме кодирования.
4.2 маскирование данных (data masking): Процесс применения операции XOR к комбинациям битов в области кодирования с использованием шаблонов маски, с целью образования символа со сбалансированным числом темных и светлых модулей и уменьшения вероятности присутствия комбинаций, которые могут помешать быстрой обработке изображения.
4.3 указатель шаблона маски данных (data mask pattern reference): Трехбитовый идентификатор, указывающий шаблон маски данных, используемый в символе.
4.4 область кодирования (encoding region): Область символа, свободная от функциональных шаблонов и предназначенная для кодирования данных и кодовых слов исправления ошибок и информации о версии и формате символа.
4.5 исключительный поднабор (exclusive subset): Подмножество знаков в наборе знаков режима, которые не пересекаются с более ограниченным набором знаков другого режима.
4.6 шаблон расширения (extension pattern): Функциональный шаблон в символах Model 1, не кодирующий данные.
4.7 информация о формате (format information): Шаблон, в котором закодирована информация об основных параметрах, необходимых для обеспечения декодирования оставшейся части области кодирования.
4.8 QR Code (QR Code): Обозначение всех символов QR Code от версии 1 до версии 40 для обеспечения возможности их отличия от символов Micro QR Code.
4.9 функциональный шаблон (function pattern): Дополнительные компоненты символа (шаблоны поиска, разделитель, шаблоны синхронизации, направляющие шаблоны), которые требуются для уточнения места нахождения символа или определения его параметров с целью обеспечения декодирования.
4.10 маскирование (masking): Процесс применения операции XOR к комбинации битов в какой-либо области символа с использованием шаблона маски для уменьшения комбинаций, которые могут препятствовать быстрой обработке изображения.
4.11 микро (micro): Обозначение всех символов Micro QR Code от версии M1 до версии M4 для обеспечения возможности их отличия от символов QR Code.
4.12 режим (mode): Способ преобразования последовательности кодируемых знаков в двоичную строку.
4.13 индикатор режима (mode indicator): Идентификатор, состоящий из четырех битов, указывающий режим, в котором закодирована следующая за ним последовательность данных.
4.14 бит-заполнитель (padding bit): Нулевой бит, не представляющий данные, предназначенный для заполнения оставшихся незаполненными позиций последнего кодового слова после ограничителя <1> в двоичной строке данных.
--------------------------------
<1> Кодируемые данные пакуются в двоичный поток с точностью до бита, а алгоритмы размещения данных в символе и расчета исправления ошибок используют 8-битовые кодовые слова. Если последнее кодовое слово остается заполненным не до конца, используют биты-заполнители.
4.15 остаточный бит (remainder bit): Нулевой бит, не представляющий данные, используемый для заполнения оставшихся незаполненными позиций в области кодирования после последнего знака символа в случае, если область кодирования, предназначенная для знаков символа, не полностью распределена для размещения 8-битовых знаков символа.
4.16 остаточное кодовое слово (remainder codeword): Кодовое слово - заполнитель, размещаемое после кодовых слов исправления ошибок, используемое для заполнения оставшихся незаполненными позиций кодовых слов с целью доукомплектования символа, если общее число кодовых слов данных и исправления ошибок не достаточно для полного заполнения его номинальной емкости <1>.
--------------------------------
<1> Остаточные кодовые слова добавляют после кодовых слов исправления ошибок.
4.17 сегмент (segment): Последовательность данных, закодированная согласно правилам одной интерпретации в расширенном канале (ECI) или режима кодирования.
4.18 разделитель (separator): Функциональный шаблон, состоящий из светлых модулей, шириной один модуль, отделяющий шаблоны поиска от остального содержимого символа.
4.19 номер символа (symbol number): Поле из трех битов, указывающее версию символа и уровень исправления ошибок, используемое как часть информации о формате в символах Micro QR Code.
4.20 ограничитель (terminator): Битовый шаблон, состоящий из некоторого числа (зависящего от символа) нулевых битов, используемый для индикации окончания двоичной строки, представляющей данные.
4.21 шаблон синхронизации (timing pattern): Чередующаяся последовательность темных и светлых модулей, предназначенная для определения координат модулей в символе.
4.22 версия (version): Размер символа в соответствии с его позицией в последовательности допустимых размеров символов; символы Micro QR Code имеют размеры (в модулях) от 11 x 11 (версия M1) до 17 x 17 (версия M4), а символы QR Code - от 21 x 21 (версия 1) до 177 x 177 (версия 40).
Примечание - Уровень исправления ошибок, применимый к символу, может быть добавлен к обозначению версии, например, версия 4-L или версия M3-Q.
4.23 информация о версии (version information): Шаблон, закодированный в некоторых символах QR Code, содержащий информацию о версии символа вместе с битами исправления ошибок для этих данных.
и соглашения об обозначениях
Определения математических символов, используемых в формулах и уравнениях, приведены после соответствующих формул и уравнений.
Кроме того, в настоящем стандарте применяются следующие математические и логические операторы:
div - оператор деления на целое число;
mod - оператор вычисления остатка от деления на целое число;
XOR - исключающее ИЛИ (exclusive-or) - логическая функция или операция, результатом которой является единица только в случае неэквивалентности двух входов; обозначается знаком  .
.
BCH - код Боуза-Чоудхури-Хоквингема (Bose-Chaudhuri-Hocquenghem);
ECI - интерпретация в расширенном канале (Extended Channel Interpretation);
RS - код Рида-Соломона (Reed-Solomon).
5.3.1 Позиции модулей
Для упрощения ссылок позиции модулей определяют через координаты строки и столбца символа в форме (i, j), где i определяет строку (отсчет производят сверху вниз) и j - столбец (отсчет производят слева направо); отсчет начинают с 0. Таким образом, модуль (0, 0) расположен в верхнем левом углу символа.
5.3.2 Представление байтов
Содержимое байта представляют в его шестнадцатеричном значении.
5.3.3 Ссылки на версии
Для символов QR Code версию символа представляют в форме V-E, где V - обозначает номер версии (от 1 до 40), а E указывает уровень исправления ошибок (L, M, Q, H).
Для символов Micro QR Code версию символа представляют в форме MV-E, где M указывает на символ формата Micro QR Code, а V (со значениями от 1 до 4) и E (со значениями L, M, Q) соответствуют вышеуказанному.
QR Code - это матричная символика, имеющая следующие параметры:
a) форматы:
1) QR Code, который обладает полным набором возможностей и максимальной емкостью для данных;
2) Micro QR Code, который обладает уменьшенным набором возможностей, рядом ограниченных возможностей и уменьшенной емкостью для данных (по сравнению с символами QR Code);
b) кодируемые наборы знаков:
1) числовые данные (цифры от 0 до 9);
2) алфавитно-цифровые данные (цифры от 0 до 9; прописные буквы от A до Z и девять специальных графических знаков: пробел, $, %, *, +, -, ., /, :);
3) байтовые данные (по умолчанию - в соответствии с ИСО/МЭК 8859-1 или другой набор знаков <1>, если это специально указано (см. 7.3.5));
4) знаки кандзи <2>. Один знак кандзи в QR Code может быть уплотнен в 13 битов;
--------------------------------
<1> В приложении ДА приведен набор знаков кирилловского алфавита по ИСО/МЭК 8859-5.
<2> Кандзи (японское наименование -  , английское наименование - Kanji) - иероглифическое письмо, являющееся составной частью японской письменности.
, английское наименование - Kanji) - иероглифическое письмо, являющееся составной частью японской письменности.
c) представление данных:
темный модуль, как правило, является двоичной единицей, а светлый модуль - двоичным нулем. В случаях обратимого изображения - см. 6.2;
d) размеры символа (не включая свободную зону):
1) символы Micro QR Code: размеры (в модулях) от 11 x 11 до 17 x 17 (версии от M1 до M4 с шагом два модуля для каждой стороны);
2) символы QR Code: размеры (в модулях) от 21 x 21 до 177 x 177 (версии от 1 до 40 с шагом четыре модуля для каждой стороны);
e) число знаков данных в символе:
1) символ Micro QR Code максимального размера, версия M4-L:
- числовые данные: 35 знаков;
- алфавитно-цифровые данные: 21 знак;
- данные в байтах: 15 знаков;
- знаки кандзи: 9 знаков;
2) символ QR Code максимального размера, версия 40-L:
- числовые данные: 7089 знаков;
- алфавитно-цифровые данные: 4296 знаков;
- данные в байтах: 2953 знака;
- знаки кандзи: 1817 знаков;
f) выбираемый уровень исправления ошибок:
Используют четыре уровня исправления ошибок Рида-Соломона (обозначаемые L, M, Q и H в порядке увеличения занимаемой емкости):
- L - 7%;
- M - 15%;
- Q - 25%;
- H - 30% от числа кодовых слов символа.
Для символов Micro QR Code уровень исправления ошибок H не используют. Для Micro QR Code версии M1 алгоритм Рида-Соломона обеспечивает только возможность обнаружения ошибок;
g) тип кода:
- матричный;
h) независимость от ориентации:
- обеспечивается (допускается поворот на любой угол и зеркальное отображение).
На рисунке 1 представлен символ QR Code версии 1 с типовым цветовым сочетанием, символ с инвертированным изображением представлен в 6.2, на рисунках символы приведены в обычной ориентации и в зеркальном отображении.

a)

b)

c)

d)
a) обычная ориентация и типовые значения коэффициентов отражения;
b) обычная ориентация и инвертированные значения коэффициентов отражения;
c) зеркальная ориентация изображения и типовые значения коэффициентов отражения;
d) зеркальная ориентация изображения и инвертированные значения коэффициентов отражения
"QR Code Symbol"
На рисунке 2 представлен символ Micro QR Code версии M2 с типовым цветовым сочетанием и символ с инвертированными коэффициентами отражения (см. 6.2), на рисунках символы приведены в обычной ориентации и в зеркальном отображении.

a)

b)

c)

d)
a) обычная ориентация и типовые значения коэффициентов отражения;
b) обычная ориентация и инвертированные значения коэффициентов отражения;
c) зеркальная ориентация изображения и типовые значения коэффициентов отражения;
d) зеркальная ориентация изображения и инвертированные значения коэффициентов отражения
кодирующих текст "01234567"
Примечание - Угловые метки на рисунках 1 и 2 указывают границы свободной зоны.
В QR Code используются следующие дополнительные свойства, устанавливаемые по выбору:
- структурированное соединение
Эта опция обеспечивает возможность представления одного длинного сообщения в виде нескольких (до 16) логически связанных символов QR Code, которые могут быть отсканированы в любой последовательности с возможностью корректного восстановления исходных данных. В символах Micro QR Code структурированное соединение не допускается;
- интерпретация в расширенном канале (ECI)
Эта опция обеспечивает возможность использования наборов знаков, отличающихся от набора знаков по умолчанию (например, арабского, кириллицы, греческого), и иных интерпретаций данных (например, уплотнение данных с использованием определенных схем уплотнения) или соответствия другим международным отраслевым требованиям к кодированию. В символах Micro QR Code не допускается использование ECI, отличающейся от интерпретации по умолчанию;
- инверсия значений коэффициента отражения
Символы, предназначенные для считывания, могут быть напечатаны так, что изображение представлено темными модулями на светлом фоне, или светлыми модулями на темном фоне (см. рисунок 1 и 2). В настоящем стандарте рассматриваются символы QR Code, представляющие собой темные модули, расположенные на светлом фоне, следовательно в случае производства символов с инвертированными значениями коэффициента отражения, положения, относящиеся к темным или светлым модулям, следует применять соответственно к светлым или темным модулям;
- зеркальное отображение
Расположение модулей, определенных в настоящем стандарте, представляет "нормальную" ориентацию символа. Допускается декодировать символ, в котором модули размещены в обратном порядке по горизонтали. При рассмотрении шаблонов поиска в левом верхнем, правом верхнем и левом нижнем углах символа действие зеркального отображения заключается в обмене позициями строк и столбцов модулей.
6.3.1 Общие положения
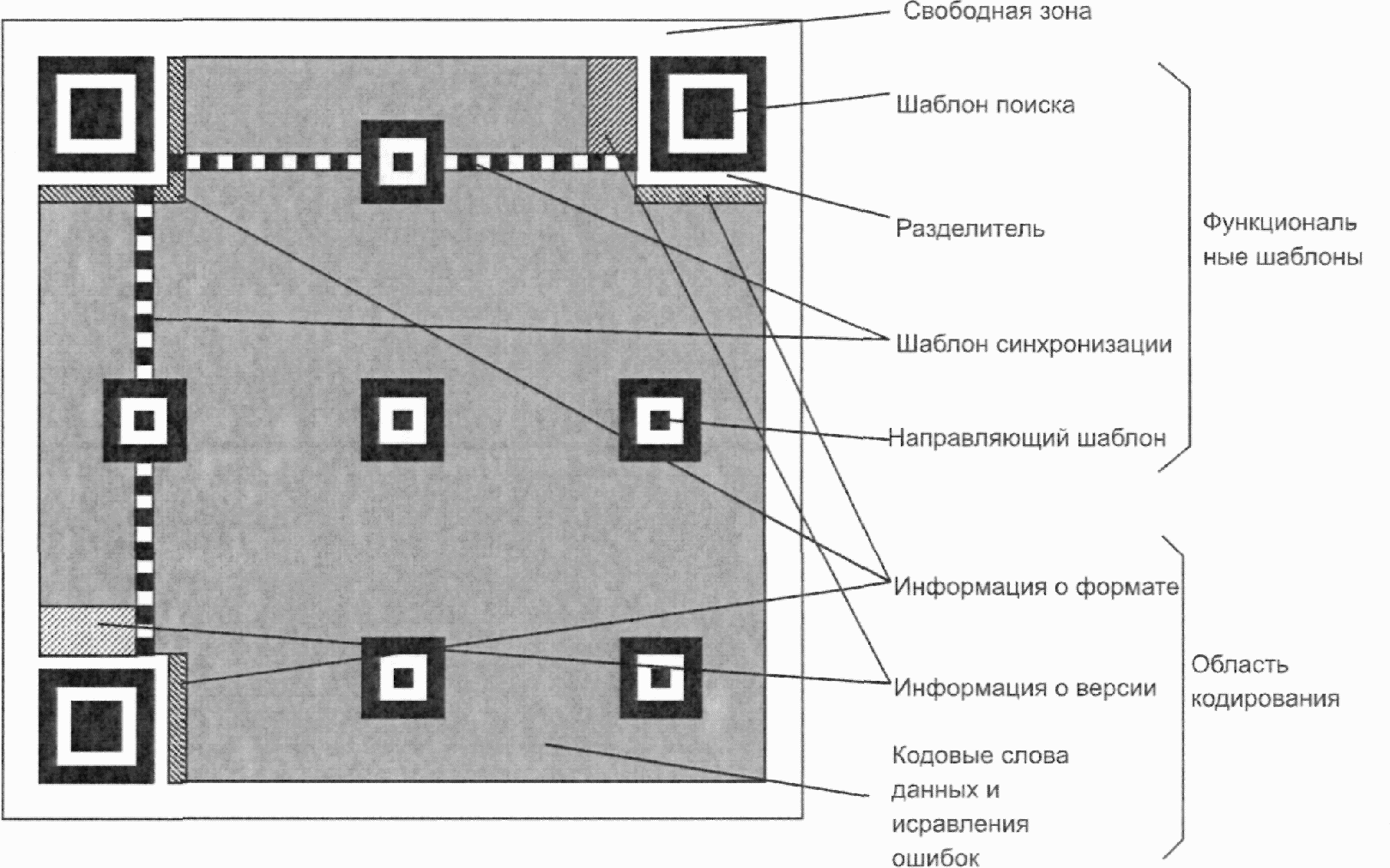
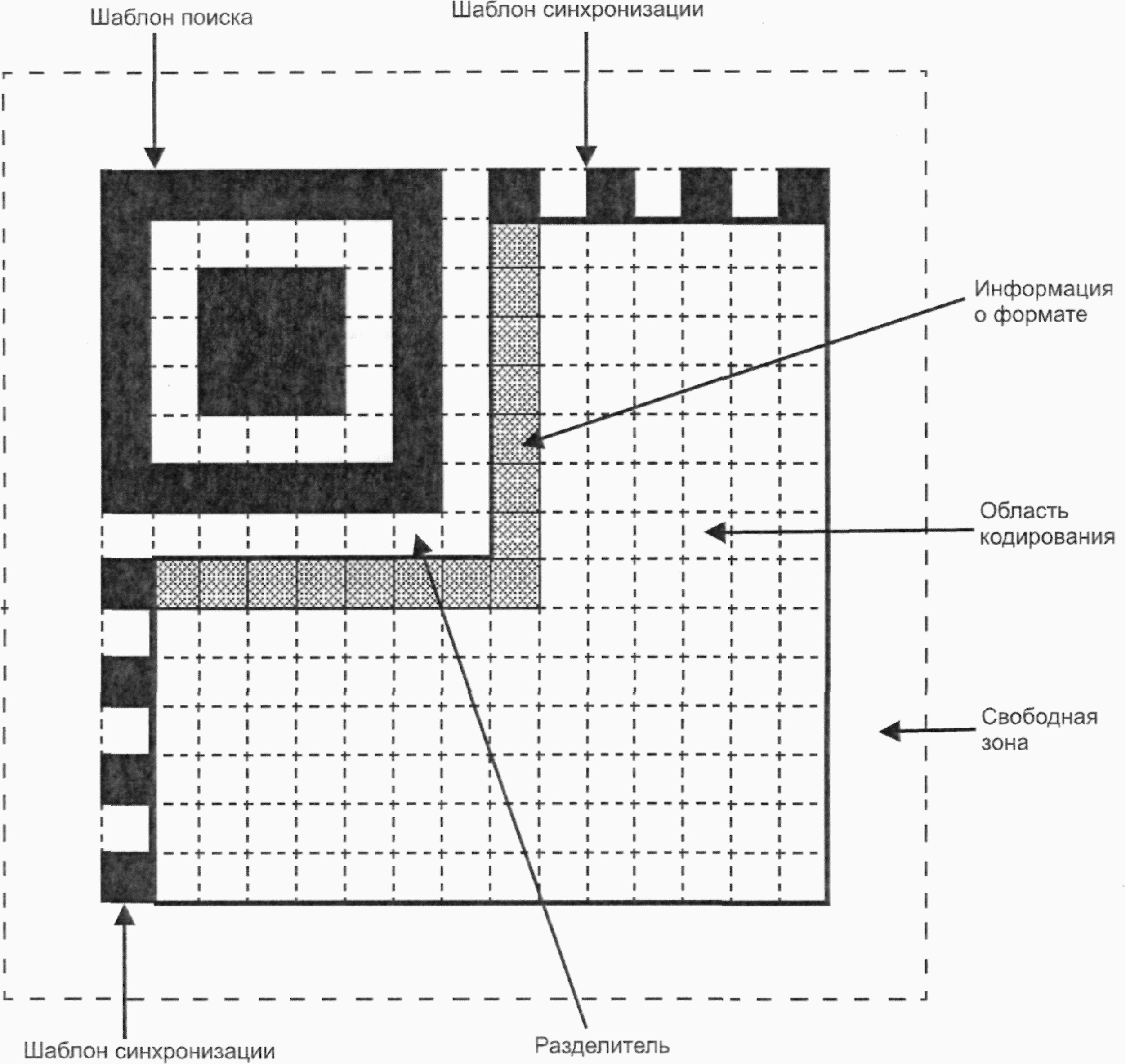
Каждый символ QR Code состоит из номинально квадратных модулей, структурированных в регулярную матрицу, и включает область кодирования и функциональные шаблоны, называемые шаблонами поиска, разделителями, шаблонами синхронизации и направляющими шаблонами. Функциональные шаблоны не содержат данных. Символ должен быть окружен со всех четырех сторон свободной зоной. На рисунке 3 представлена структура символа версии 7. На рисунке 4 представлена структура символа версии M3.
6.3.2.1 Символы QR Code
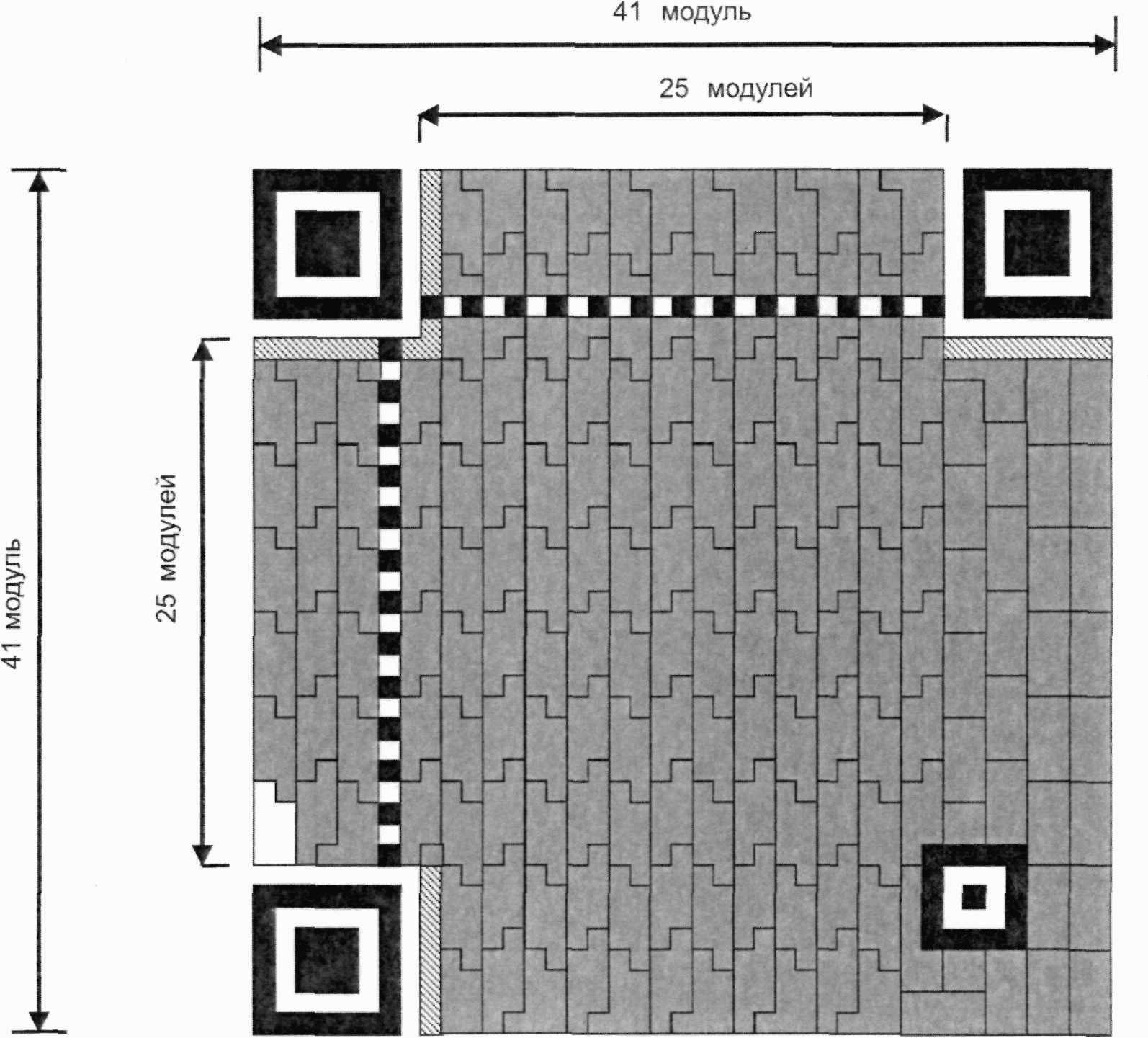
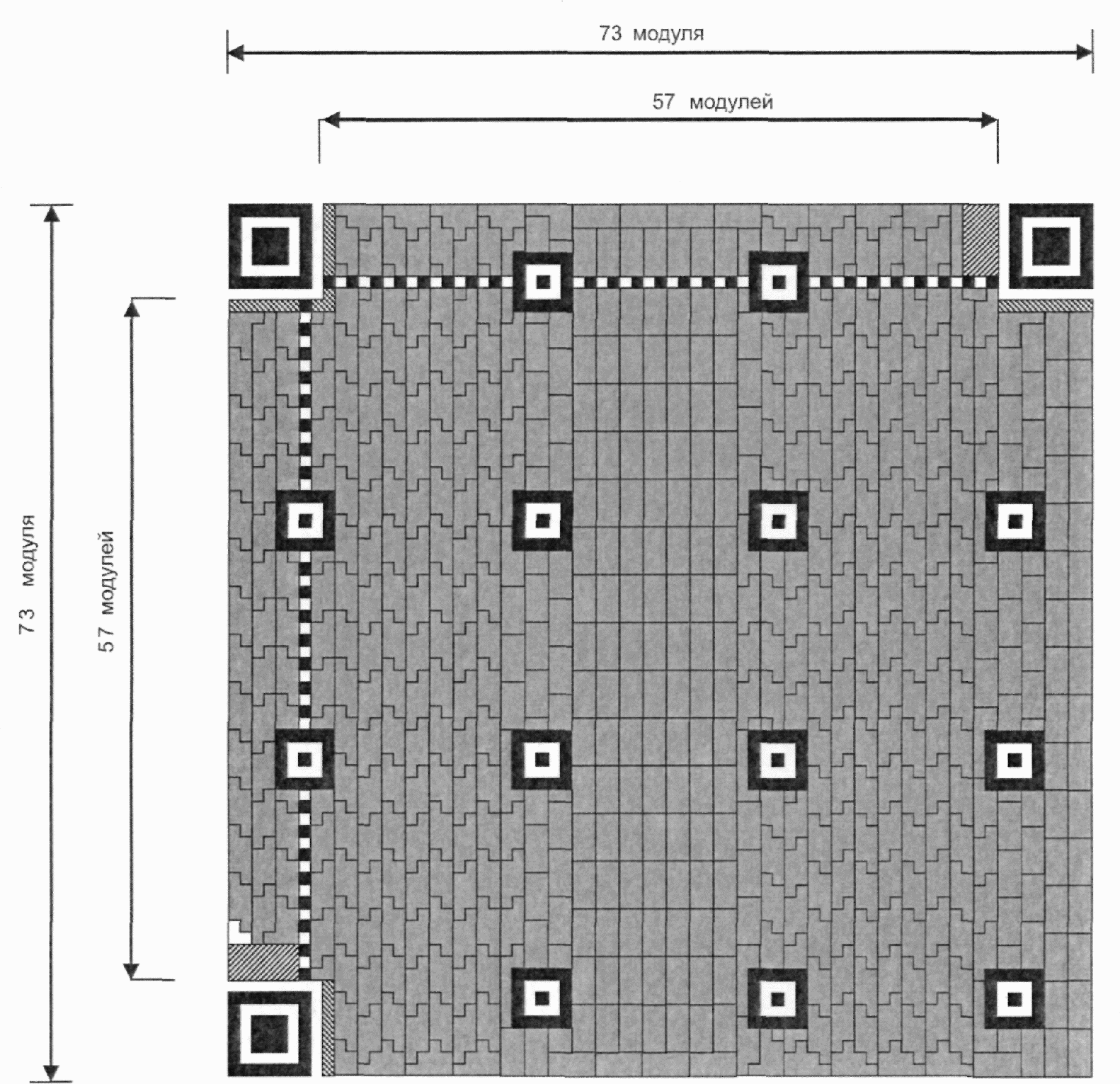
Существует 40 возможных вариантов размера символа QR Code, обозначаемых как версия 1, версия 2, ..., версия 40. Версия 1 имеет размеры (в модулях) 21 x 21, версия 2 - 25 x 25 и так далее с шагом 4 модуля вплоть до версии 40, которая имеет размер (в модулях) 177 x 177. На рисунках 5 - 10 представлены структуры символов версий 1, 2, 6, 7, 14, 21 и 40.
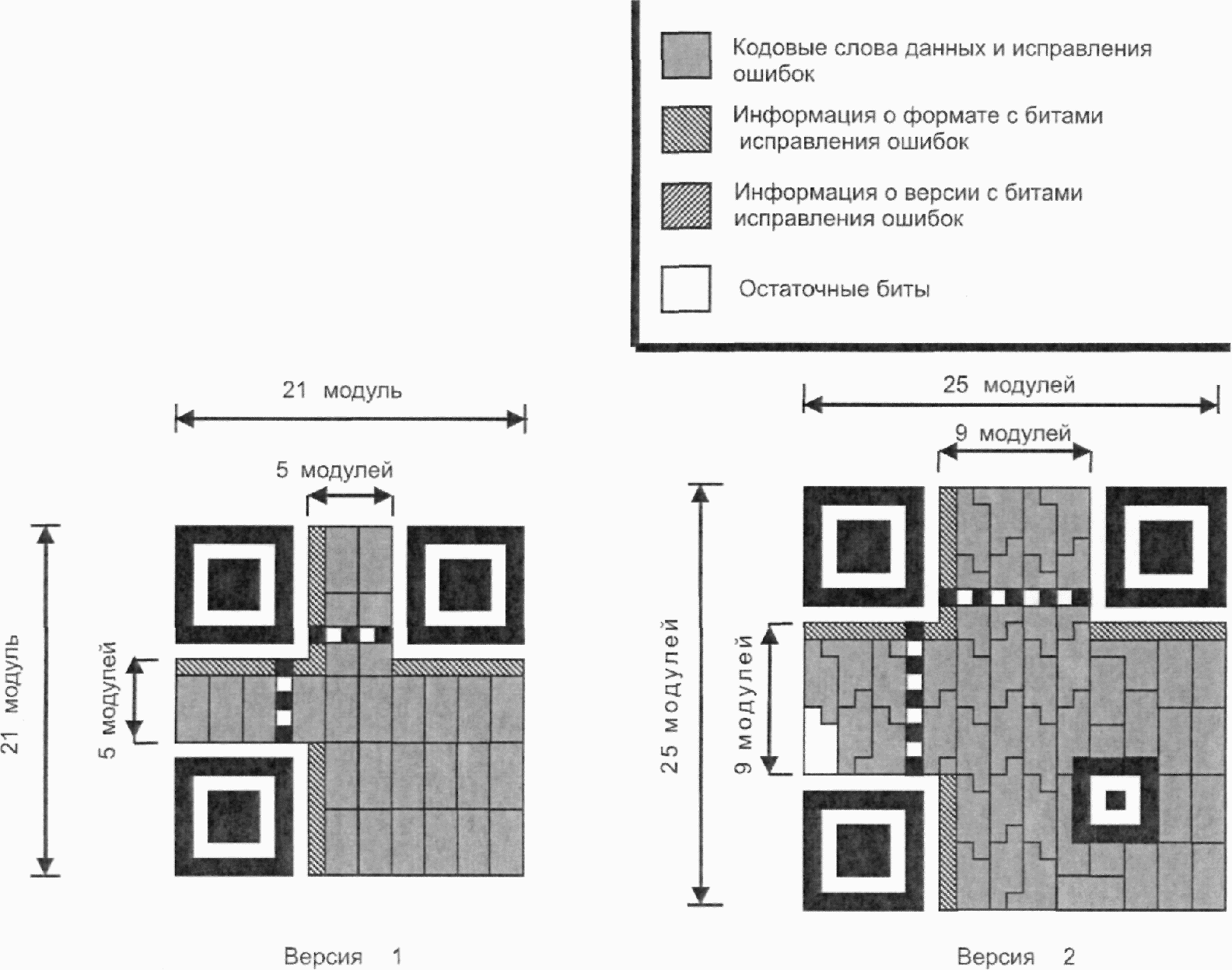
Рисунок 5 - Символы версий 1 и 2
Версия 6
Рисунок 6 - Символ версии 6
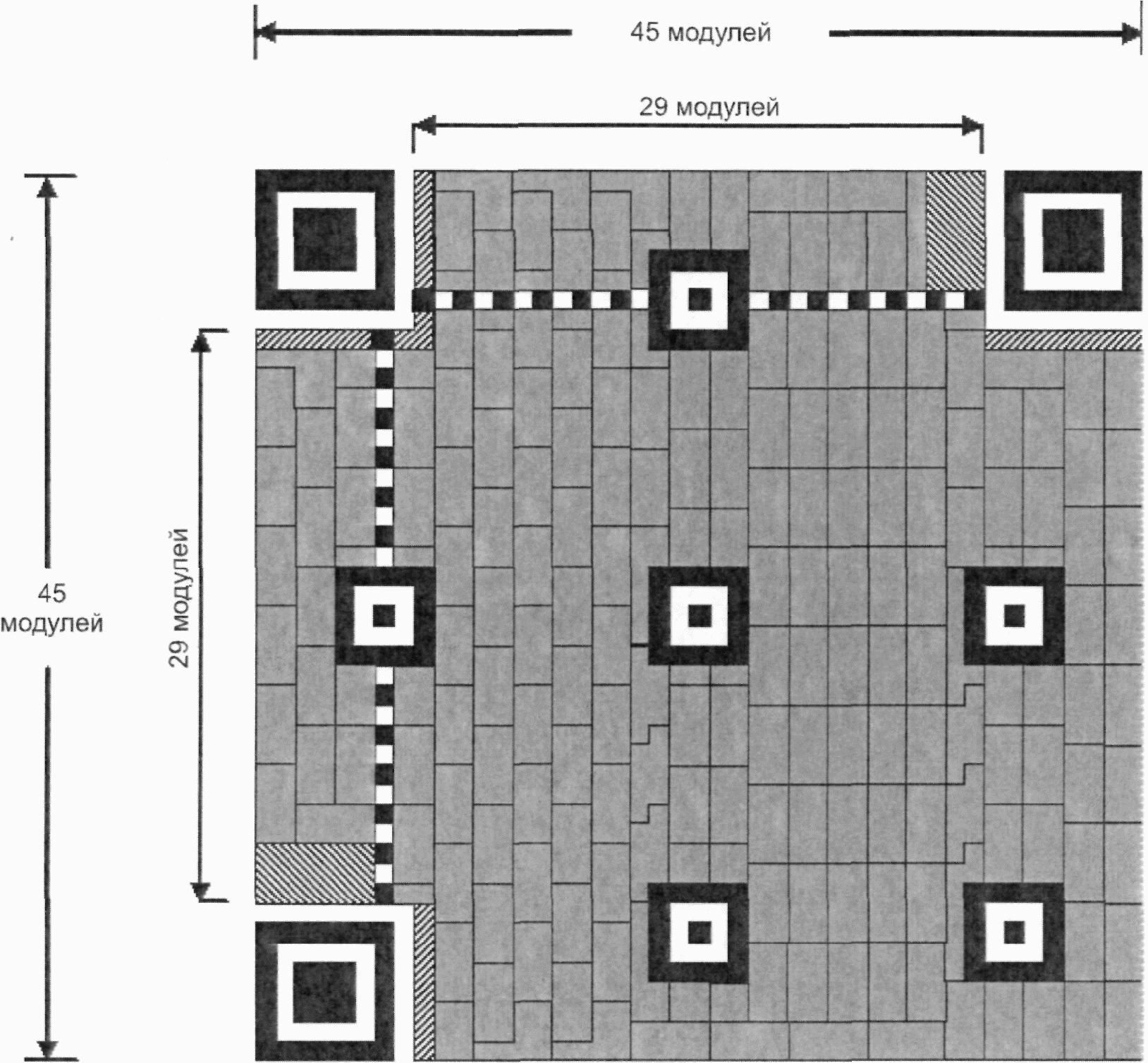
Рисунок 7 - Символ версии 7
Версия 14
Рисунок 8 - Символ версии 14

Версия 21
Рисунок 9 - Символ версии 21
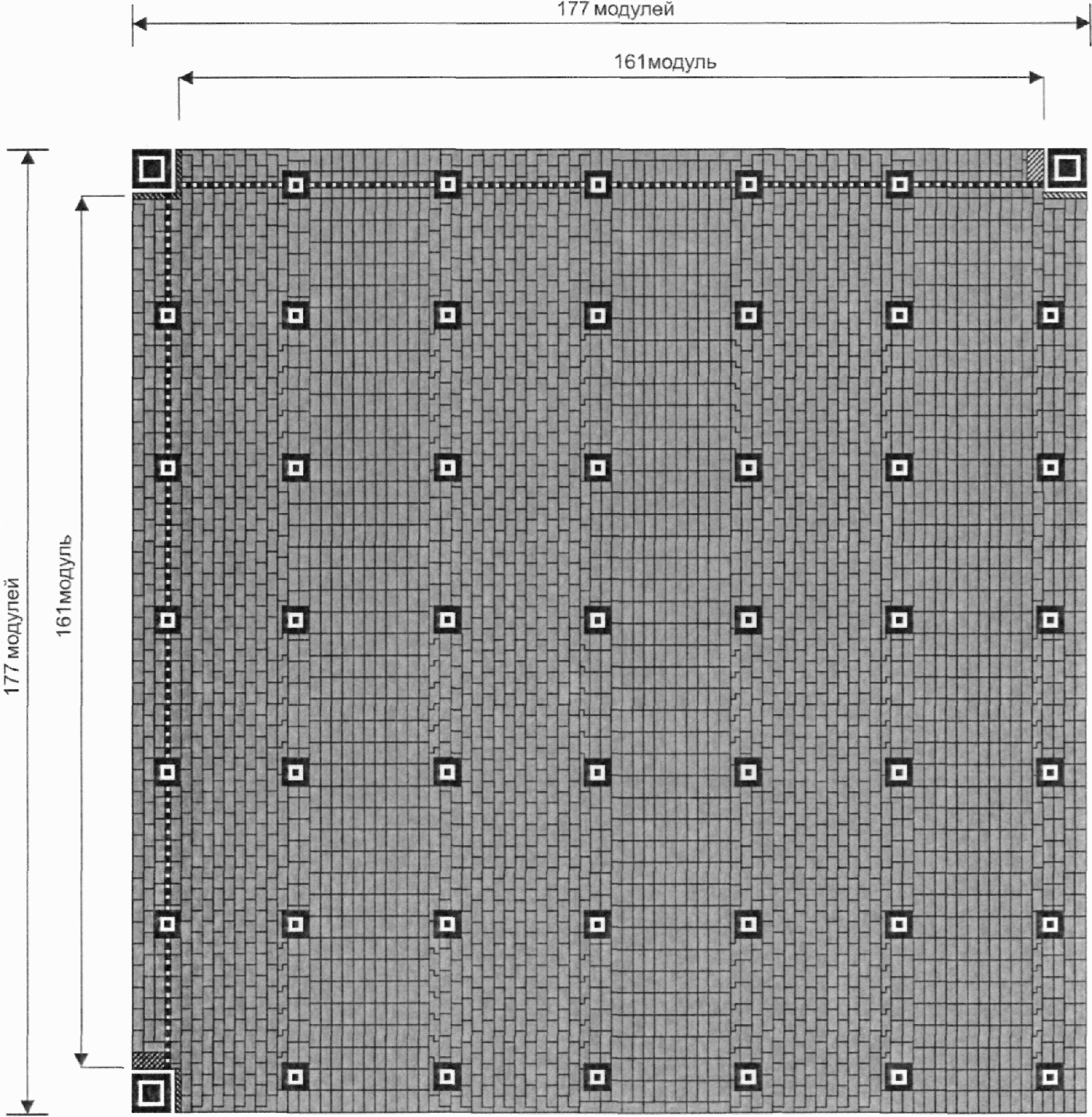
Версия 40
6.3.2.2 Символы Micro QR Code
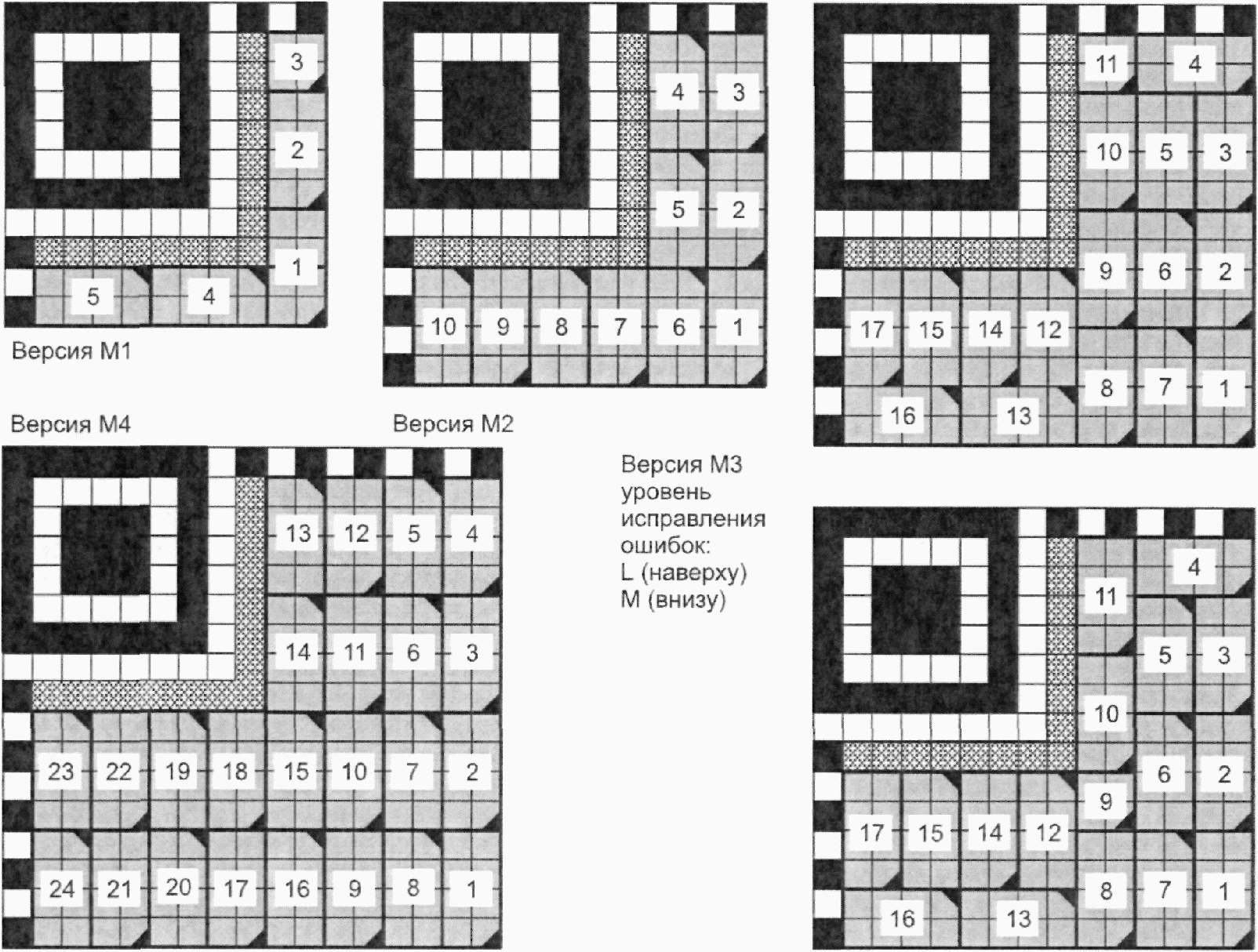
Символы Micro QR Code могут иметь четыре размера, обозначаемые как версии с M1 по M4. Версия M1 имеет размеры (в модулях) 11 x 11, версия M2 (в модулях) - 13 x 13, версия M3 (в модулях) - 15 x 15, версия M4 (в модулях) - 17 x 17, т.е. с шагом 2 модуля по каждой стороне. На рисунке 11 представлена структура символов Micro QR Code версий с M1 по M4.
Примечание - Представлены два формата символа M3, отличающиеся только размещением кодовых слов согласно уровню исправления ошибок.
Имеются три одинаковых шаблона поиска, размещенных в левом верхнем, правом верхнем и левом нижнем углах символа, как показано на рисунке 3. Каждый шаблон поиска выглядит как три вложенных друг в друга квадрата: темного размерами (в модулях) 7 x 7, светлого размерами (в модулях) 5 x 5 и темного размерами (в модулях) 3 x 3. Размеры в модулях в любом шаблоне поиска находятся в соотношении 1:1:3:1:1, как показано на рисунке 12. Представление кодируемых данных должно быть таким чтобы, что вероятность встретить такой шаблон среди кодируемых данных была очень мала, что позволяет быстро определить присутствие символа QR Code в поле обзора. Идентификация трех шаблонов, составляющих шаблон поиска, позволяет определить место нахождения и угловую ориентацию символа в поле обзора.
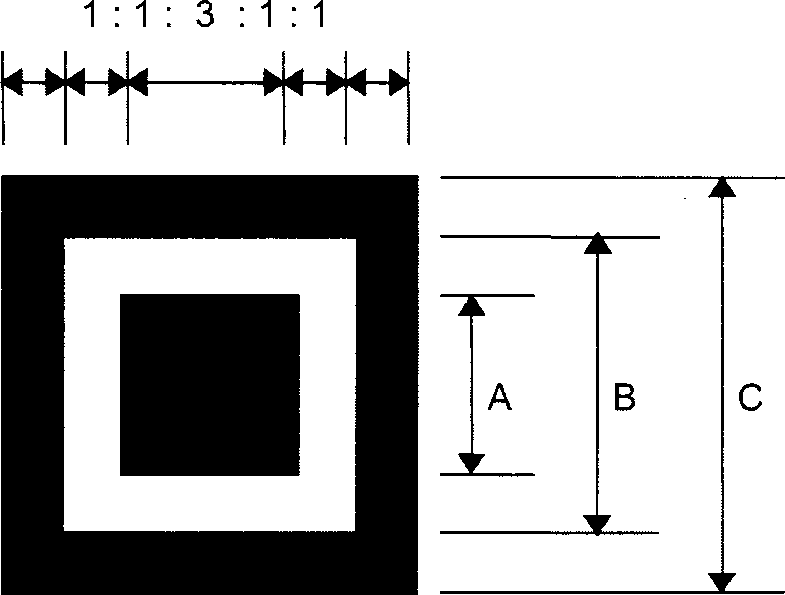
A - 3 модуля
B - 5 модулей
C - 7 модулей
Рисунок 12 - Структура шаблона поиска
6.3.3.2 Символы Micro QR Code
Единственный шаблон поиска по 6.3.3.1 расположен в верхнем левом углу символа, как показано на рисунке 4. Идентификация шаблона поиска вместе с шаблонами синхронизации однозначно определяет размер, положение и угловую ориентацию символа в поле обзора.
6.3.4 Разделитель
Разделитель, шириной один модуль, состоящий только из светлых модулей, располагается между каждым из шаблонов поиска и областью кодирования, как показано на рисунках 3 и 4.
6.3.5 Шаблон синхронизации
Горизонтальный и вертикальный шаблоны синхронизации представляют собой соответственно строку или столбец шириной один модуль, состоящих из чередующихся темных и светлых модулей, начинающихся и заканчивающихся темным модулем. С помощью этих шаблонов определяют размер и версию символа, а также позиции для нахождения координат модулей.
В символах QR Code горизонтальный шаблон синхронизации проходит по шестой строке символа между разделителями верхнего левого и верхнего правого шаблона поиска символа; вертикальный шаблон синхронизации проходит по шестому столбцу между разделителями верхнего левого и нижнего левого шаблона поиска символа, как показано на рисунке 3.
В символах Micro QR Code горизонтальный шаблон синхронизации проходит по нулевой строке символа от правого разделителя до правого края символа; вертикальный шаблон синхронизации проходит по нулевому столбцу символа от нижнего разделителя до нижнего края символа, как показано на рисунке 4.
Направляющие шаблоны присутствуют только в символах QR Code версии 2 или версии с большим номером. Каждый шаблон представляет собой суперпозицию трех вложенных друг в друга квадратов и состоит из темного квадрата размерами (в модулях) 5 x 5, светлого размерами (в модулях) 3 x 3 и единственного темного модуля в центре. Число направляющих шаблонов зависит от версии символа и шаблоны должны присутствовать во всех символах, начиная с версии 2 и версии с большим номером, в позициях, установленных в приложении E.
6.3.7 Область кодирования
Эта область содержит знаки символа, представляющие данные, кодовые слова исправления ошибок, информацию о формате и версии. Подробные требования к знакам символа приведены в 7.7.1, к информации о формате - в 7.9, к информации о версии - в 7.10.
6.3.8 Свободная зона
Это область должна быть свободной от всех других маркировок и окружать символ со всех четырех сторон. Коэффициент отражения свободной зоны должен соответствовать коэффициенту отражения светлых модулей.
Для символов QR Code ширина свободной зоны должна быть равна 4X.
Для символов Micro QR Code ширина свободной зоны должна быть равна 2X.
В настоящем разделе описан процесс преобразования входных данных в символ QR Code.
Этап 1. Анализ данных
Анализируют входной поток данных, чтобы установить различия входящих в него знаков, которые нужно закодировать. Формат QR Code (не Micro QR Code) поддерживает интерпретацию в расширенном канале, допуская для кодирования данные, отличающиеся от заданного по умолчанию набора знаков. QR Code может включать в себя несколько режимов (см. 7.3), которые позволяют эффективно преобразовывать различные поднаборы знаков в знаки символа. По мере необходимости между режимами вставляют переключения для достижения наиболее эффективного преобразования данных в двоичную строку. Выбирают требуемый уровень обнаружения и исправления ошибок. Если пользователь не определил версию символа, которую нужно использовать, выбирают версию символа с наименьшим значением, которая допускает размещение данных. Полный перечень версий символа и соответствующих им емкостей приведен в таблице 1.
Таблица 1
Версия | Число модулей/сторона (A) | Число модулей в функциональных шаблонах (B) | Число модулей в информации о версии (C) | Оставшиеся модули для данных (D) <1> (D = A2 - B - C) | Объем данных (кодовых слов <a>) (E) | Остаточные биты |
M1 | 11 | 70 | 15 | 36 | 5 | 0 |
M2 | 13 | 74 | 15 | 80 | 10 | 0 |
M3 | 15 | 78 | 15 | 132 | 17 | 0 |
M4 | 17 | 82 | 15 | 192 | 24 | 0 |
1 | 21 | 202 | 31 | 208 | 26 | 0 |
2 | 25 | 235 | 31 | 359 | 44 | 7 |
3 | 29 | 243 | 31 | 567 | 70 | 7 |
4 | 33 | 251 | 31 | 807 | 100 | 7 |
5 | 37 | 259 | 31 | 1 079 | 134 | 7 |
6 | 41 | 267 | 31 | 1 383 | 172 | 7 |
7 | 45 | 390 | 67 | 1 568 | 196 | 0 |
8 | 49 | 398 | 67 | 1 936 | 242 | 0 |
9 | 53 | 406 | 67 | 2 336 | 292 | 0 |
10 | 57 | 414 | 67 | 2 768 | 346 | 0 |
11 | 61 | 422 | 67 | 3 232 | 404 | 0 |
12 | 65 | 430 | 67 | 3 728 | 466 | 0 |
13 | 69 | 438 | 67 | 4 256 | 532 | 0 |
14 | 73 | 611 | 67 | 4 651 | 581 | 3 |
15 | 77 | 619 | 67 | 5 243 | 655 | 3 |
16 | 81 | 627 | 67 | 5 867 | 733 | 3 |
17 | 85 | 635 | 67 | 6 523 | 815 | 3 |
18 | 89 | 643 | 67 | 7 211 | 901 | 3 |
19 | 93 | 651 | 67 | 7 931 | 991 | 3 |
20 | 97 | 659 | 67 | 8 683 | 1 085 | 3 |
21 | 101 | 882 | 67 | 9 252 | 1 156 | 4 |
22 | 105 | 890 | 67 | 10 068 | 1 258 | 4 |
23 | 109 | 898 | 67 | 10 916 | 1 364 | 4 |
24 | 113 | 906 | 67 | 11 796 | 1 474 | 4 |
25 | 117 | 914 | 67 | 12 708 | 1 588 | 4 |
26 | 121 | 922 | 67 | 13 652 | 1 706 | 4 |
27 | 125 | 930 | 67 | 14 628 | 1 828 | 4 |
28 | 129 | 1 203 | 67 | 15 371 | 1 921 | 3 |
29 | 133 | 1 211 | 67 | 16 411 | 2 051 | 3 |
30 | 137 | 1 219 | 67 | 17 483 | 2 185 | 3 |
31 | 141 | 1 227 | 67 | 18 587 | 2 323 | 3 |
32 | 145 | 1 235 | 67 | 19 723 | 2 465 | 3 |
33 | 149 | 1 243 | 67 | 20 891 | 2 611 | 3 |
34 | 153 | 1 251 | 67 | 22 091 | 2 761 | 3 |
35 | 157 | 1 574 | 67 | 23 008 | 2 876 | 0 |
36 | 161 | 1 582 | 67 | 24 272 | 3 034 | 0 |
37 | 165 | 1 590 | 67 | 25 568 | 3 196 | 0 |
38 | 169 | 1 598 | 67 | 26 896 | 3 362 | 0 |
39 | 173 | 1 606 | 67 | 28 256 | 3 532 | 0 |
40 | 177 | 1 614 | 67 | 29 648 | 3 706 | 0 |
Этап 2. Кодирование данных
Знаки данных преобразуют в двоичный поток в соответствии с правилами, установленными для действующего режима по 7.4.2 - 7.4.6. При необходимости смены режима вставляют индикаторы режима в начале каждого нового сегмента, а в конце данных вставляют ограничитель. Преобразуют результирующий двоичный поток в последовательность 8-битовых кодовых слов. Добавляют необходимое число знаков-заполнителей для образования требуемого числа кодовых слов в соответствии с выбранной версией символа.
Этап 3. Кодирование исправления ошибок
Последовательность кодовых слов делят на требуемое число блоков (согласно таблице 9), чтобы обеспечить возможность обработки алгоритмами исправления ошибок. Для каждого блока формируют кодовые слова исправления ошибок, добавляя кодовые слова исправления ошибок в конец последовательности кодовых слов данных.
Этап 4. Структура завершенного сообщения
Кодовые слова данных чередуют с кодовыми словами исправления ошибок от каждого блока согласно в 7.6 (этап 3) и добавляют остаточные биты, если это необходимо.
Этап 5. Размещение модулей в матрице
Модули кодовых слов размещают в матрице вместе с шаблоном поиска, разделителями, шаблонами синхронизации и направляющими шаблонами.
Этап 6. Маскирование данных
К области закодированных данных подбирают маскирующий шаблон, после чего оценивают результаты и выбирают шаблон маски, который оптимизирует баланс темных/светлых модулей и скрывает возникновение нежелательных комбинаций.
Этап 7. Информация о формате и версии
Формируют информацию о формате и, при необходимости, о версии, после чего завершают создание символа.
Анализируют строку входных данных с целью определения ее содержания и выбирают установленную по умолчанию или другую соответствующую ECI и соответствующий режим, чтобы закодировать каждую последовательность знаков в соответствии с 7.4. Каждый режим последовательно от числового до режима кандзи требует большего числа битов на знак. Допускается переключение с режима на другой в пределах символа с целью уменьшить длину выходного потока данных, некоторые части которых могут более эффективно кодироваться в одном режиме, в отличие от других частей, например числовые последовательности, сопровождаемые алфавитно-цифровыми последовательностями. Теоретически наиболее эффективно кодировать данные в режиме, требующем наименьшего числа битов на знак входных данных, но так как есть некоторая избыточность в виде индикатора режима и индикатора числа знаков, связанного с каждым изменением режима, то в результате не всегда может получиться самый короткий двоичный поток, если изменить режимы для нескольких знаков. Кроме того, так как емкость символов увеличивается дискретным ступенчатым образом от одной версии до следующей, не всегда требуется обеспечивать максимальную эффективность. Руководство по уменьшению длины двоичного потока приведено в приложении J. В символах Micro QR Code есть ограничения на использование режимов, доступных в версиях с меньшими номерами. В J.2 приведены версии символов Micro QR Code, соответствующим различным комбинациям двух режимов.
7.3.1 Общие положения
Режимы, представленные в настоящем разделе, основаны на значениях знаков и представлениях, связанных со значением ECI по умолчанию. Когда задействована любая другая ECI (только в символах QR Code), для определения оптимального режима рекомендуется использовать значения байта, а не определенные представления знаков. Например, числовой режим следует использовать, если встречается последовательность байтов данных, значения которых находятся в пределах диапазона от 30HEX до 39HEX включ. В этом случае лучшее уплотнение достигается при использовании заданных по умолчанию числовых или алфавитно-цифровых эквивалентов значений байта.
Протокол интерпретации в расширенном канале (ECI), определенный в Международных технических спецификациях организации AIM Inc. "Интерпретации в расширенном канале" (International Technical Specification Extended Channel Interpretations) <1>, допускает интерпретацию выходного потока данных, отличающегося от набора знаков по умолчанию. Протокол ECI определен одинаковым образом во множестве символик. Протокол ECI предусматривает метод интерпретации специфических значений байта после декодирования и перед выводом на печать (или монитор). Символика Micro QR Code не поддерживает протокол ECI.
--------------------------------
<1> См. спецификацию [22].
Для QR Code по умолчанию принята интерпретация ECI 000003, соответствующая набору знаков в ИСО/МЭК 8859-1.
В международных применениях могут быть использованы другие наборы знаков с помощью протокола ECI <2>. Например, интерпретация ECI 000020, соответствующая набору знаков JIS8 и Shift JIS.
--------------------------------
<2> ИСО/МЭК 8859-5 устанавливает набор знаков с буквами кирилловского алфавита. Указанный набор приведен в приложении ДА. Этому набору соответствует ECI 000007.
Эффективность применения режима ECI заключается во вставке в данные управляющей последовательности ECI. Непосредственно за ней должен стоять индикатор другого режима (например, для эффективного кодирования); режим ECI действует до конца сообщения или до следующего индикатора режима ECI.
Числовой режим кодирует данные, состоящие из десятичных цифр (0 - 9) (байтовые значения от 30HEX до 39HEX). Три знака данных обычно кодируются десятью битами.
7.3.4 Алфавитно-цифровой режим
Алфавитно-цифровой режим позволяет закодировать входные данные из набора 45 знаков: 10 десятичных цифр (0 - 9) (байтовые значения от 30HEX до 39HEX), 26 латинских букв (A - Z) (байтовые значения от 41HEX до 5AHEX) и 9 специальных символов (SP, $, %, *, +, -, ., /, :) (байтовые значения 20HEX, 24HEX, 25HEX, 2AHEX, 2BHEX, 2D до 2FHEX, 3AHEX соответственно). Обычно два входных знака кодируются 11 битами.
В символике Micro QR Code версии M1 алфавитно-цифровой режим недоступен.
В этом режиме каждый знак входных данных кодируется 8 битами.
В замкнутых системах, национальных или специальных реализациях QR Code, в байтовом режиме могут быть закодированы альтернативные 8-битовые наборы знаков, определенные в других частях ИСО/МЭК 8859. Если установлен альтернативный набор знаков, участвующие стороны, которые считывают символы QR Code, должны быть уведомлены в спецификации по применению или в двустороннем соглашении, какой именно набор знаков следует использовать.
В символике Micro QR Code версий M1 и M2 байтовый режим недоступен.
7.3.6 Режим кандзи
Режим кандзи эффективно кодирует знаки кандзи в соответствии с системой Shift JIS, основанной на JIS X 0208. Значения Shift JIS получены сдвигом соответствующих значений JIS X 0208. Кодирование со сдвигом подробно описано в JIS X 0208. Каждый двухбайтовый знак кодируется в 13-битовое кодовое слово.
Когда набор знаков, указанный для 8-битового байтового режима, использует байтовые значения в диапазоне от 81HEX до 9FHEX и/или от E0HEX до EBHEX, невозможно использовать режим кандзи однозначно, поскольку считывающие системы не способны из передаваемых данных определить, являются ли такие значения байта собственно данными или ведущим байтом двухбайтового знака. Можно получить более короткий двоичный поток, используя правила уплотнения режима кандзи, когда в данных встречается соответствующая последовательность значений байтов (т.е. ведущие байты, имеющие значения в диапазоне от 81HEX до 9FHEX и/или от E0HEX до EBHEX, сопровождаемые байтом, имеющим значение от 40HEX до FCHEX, исключая 7FHEX, или EBHEX, сопровождаемые байтом, имеющим значение от 40HEX до BFHEX). Байтовые комбинации представлены на рисунке H.1.
В символике Micro QR Code версий M1 и M2 режим кандзи недоступен.
Символы QR Code могут содержать последовательности данных в любой комбинации режимов, описанных в 7.3.2 - 7.3.9. Символы Micro QR Code могут содержать последовательности данных в любой комбинации режимов, допустимых для соответствующей версии и описанных в 7.3.3 - 7.3.7.
В приложении J приведено руководство для выбора наиболее эффективного преобразования входного потока данных в символ QR Code с множеством режимов. В подразделе J.3 приведено описание получения комбинации из двух режимов для допустимых версий символа Micro QR Code.
7.3.8 Режим структурированного соединения
Режим структурированного соединения используется в том случае, когда требуется разделить одно кодируемое сообщение на несколько символов QR Code. Все эти символы должны быть считаны, чтобы корректно восстановить первоначальное сообщение. Заголовок структурированного соединения кодируется в каждом символе и содержит информацию о длине последовательности символов, позиции символа в этой последовательности и идентификатор для проверки принадлежности всех символов одному сообщению. В разделе 8 приведена более полная информация о правилах кодирования структурированного соединения.
В символике Micro QR Code режим структурированного соединения недоступен.
Режим функционального знака 1 (FNC1) используется в сообщениях, которые содержат данные специального формата. FNC1 в "первой позиции" указывает, что данные отформатированы в соответствии с Общими спецификациями GS1. FNC1 во "второй позиции" определяет данные, отформатированные в соответствии с применением, согласованными с организацией AIM Inc. Режим FNC1 воздействует на все содержимое символа, но последующие индикаторы режима на него не оказывают влияния.
Примечание - "Первая позиция" и "вторая позиция" не относятся к фактическим местоположениям, но основаны на позиции знаков аналогично символике Code 128.
В символике Micro QR Code режим FNC1 недоступен.
7.4.1 Последовательность данных
Входные данные преобразуются в двоичный поток, состоящий из одного или нескольких сегментов, каждый из которых кодируется в собственном режиме. Двоичный поток начинается с индикатора режима и в ECI по умолчанию. Если с самого начала требуется ECI, отличающаяся от ECI по умолчанию, то двоичный поток должен начинаться с заголовка ECI перед первым сегментом.
Заголовок ECI (если присутствует) состоит из:
- индикатора режима ECI (4 бита)
- обозначения ECI (8, 16 или 24 бита).
Заголовок ECI начинается с первого (старшего) бита индикатора режима ECI и завершается последним (младшим) битом обозначения ECI.
Остальной двоичный поток может состоять из нескольких сегментов, каждый из которых состоит из:
- индикатора режима;
- индикатора числа знаков;
- двоичного потока данных.
Каждый сегмент режима начинается с первого (старшего) бита индикатора режима и заканчивается последним (младшего) битом двоичного потока данных. Между сегментами нет явного разделителя, поскольку их длина однозначно определяется правилами действующего режима и числом входных знаков данных.
Чтобы закодировать последовательность входных данных в текущем режиме, следует повторно использовать этапы в 7.4.2 - 7.4.7. В таблице 2 указаны индикаторы для каждого режима. В таблице 3 приведен размер индикатора числа знаков, который может иметь различные значения в зависимости от используемого режима и версии символа.
Таблица 2
Режим | Символы QR Code | Символы Micro QR Code | |||
версия | любой версии | M1 | M2 | M3 | M4 |
Длина индикатора режима, биты | 4 | 0 | 1 | 2 | 3 |
ECI | 0111 | n/a | n/a | n/a | n/a |
Числовой | 0001 | n/a | 0 | 00 | 000 |
Алфавитно-цифровой | 0010 | n/a | 1 | 01 | 001 |
Байтовый | 0100 | n/a | n/a | 10 | 010 |
Кандзи | 1000 | n/a | n/a | 11 | 011 |
Структурированное соединение | 0011 | n/a | n/a | n/a | n/a |
FNC1 <a> | 0101 (1-я позиция) 1001 (2-я позиция) | n/a | n/a | n/a | n/a |
Ограничитель (конец сообщения) <b> | 0000 | 000 | 00000 | 0000000 | 000000000 |
<b> Ограничитель по сути не является индикатором режима. | |||||
Таблица 3
Версия | Числовой режим | Алфавитно-цифровой режим | Байтовый режим | Режим кандзи |
M1 | 3 | n/a | n/a | n/a |
M2 | 4 | 3 | n/a | n/a |
M3 | 5 | 4 | 4 | 3 |
M4 | 6 | 5 | 5 | 4 |
1 - 9 | 10 | 9 | 8 | 8 |
10 - 26 | 12 | 11 | 16 | 10 |
27 - 40 | 14 | 13 | 16 | 12 |
Поток данных в законченном символе завершается ограничителем, который состоит от 3 до 9 нулевых битов (см. таблицу 2), но который может отсутствовать, если после данных оставшаяся емкость символа меньше, чем необходимая длина ограничителя в битах. Ограничитель не является индикатором режима.
7.4.2.1 Общие положения
Этот режим используется для кодированных данных, подчиненных альтернативным интерпретациям значений байтов (например, альтернативные наборы знаков) в соответствии со спецификацией организации AIM, устанавливающей интерпретации в расширенном канале (ECI) <1>, которая определяет предварительную обработку этого типа данных, и включается с помощью индикатора режима 0111.
--------------------------------
<1> См. спецификацию [22].
Интерпретации в расширенном канале могут быть использованы только с устройствами считывания, позволяющими передавать идентификатор символики. Устройства считывания, которые не могут передавать идентификатор символики, не обеспечивают передачу данных из любого символа, содержащего ECI.
Входные данные ECI должны быть обработаны в системе кодирования как ряд байтовых значений.
Данные в последовательности ECI могут кодироваться в любом режиме или режимах, допускающих наиболее эффективное кодирование значений байта данных, независимо от их графического представления. Например, последовательность байтов со значениями в диапазоне от 30HEX до 39HEX может кодироваться в числовом режиме (см. 7.4.3), как если бы это была последовательность цифр от 0 до 9, даже при том, что это фактически может представлять нечисловые данные. Для определения значения индикатора числа знаков следует использовать несколько байтов (в режиме кандзи - пар байтов).
Каждая интерпретация в расширенном канале обозначается шестизначным номером представления, который кодируется в символе QR Code как первое одно, два или три кодовых слова после индикатора режима ECI. Правила кодирования приведены в таблице 4. Обозначение ECI в данных кодируется как знак со значением 5CHEX или знак "\" "обратная дробная черта" по ИСО/МЭК 8859-1, знак  или "иена" в наборе JIS8, сопровождаемый шестизначным десятичным номером представления ECI. Там, где знак со значением 5CHEX встречается в кодируемых данных, должны быть переданы два байта с этим же значением в строке знаков перед кодированием в символе, к которому применяют протокол ECI.
или "иена" в наборе JIS8, сопровождаемый шестизначным десятичным номером представления ECI. Там, где знак со значением 5CHEX встречается в кодируемых данных, должны быть переданы два байта с этим же значением в строке знаков перед кодированием в символе, к которому применяют протокол ECI.
В случае одиночного применения знак 5CHEX действует как управляющий знак индикатора ECI, за которым должно следовать обозначение ECI. Появление сдвоенных знаков 5CHEX свидетельствует о наличии знака данных.
При декодировании двоичный шаблон первого кодового слова обозначения ECI (то есть кодового слова сразу после индикатора режима ECI), определяет длину последовательности обозначения ECI. Число битов, имеющих значение 1, перед первым битом, имеющим значение 0, определяет число дополнительных кодовых слов после первого используемого слова, чтобы указать номер представления ECI. Битовая последовательность после первого нулевого бита - двоичная запись номера представления ECI. Меньшие номера представления ECI могут быть закодированы несколькими способами, но рекомендуется использовать самый короткий.
Таблица 4
Значение представления ECI | Число кодовых слов | Значения кодовых слов |
От 000000 до 000127 | 1 | 0bbbbbbb |
От 000000 до 016383 | 2 | 10bbbbbb bbbbbbbb |
От 000000 до 999999 | 3 | 110bbbbb bbbbbbbb bbbbbbbb |
Примечание - b ... b - двоичное значение номера представления ECI. | ||
Пример - Кодирование букв греческого алфавита с использованием набора знаков ИСО/МЭК 8859-7 (ECI 000009) в символ версии 1-H.
Данные для кодирования: | 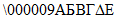 (значения знаков A1HEX, A2HEX, A3HEX, A4HEX, A5HEX) |
Последовательность битов в символе: | |
Индикатор ECI: | 0111 |
Номер представления ECI (000009): | 0 0001001 |
Индикатор режима (байты) | 0100 |
Индикатор числа знаков (5) | 00000101 |
Данные: | 10100001 10100010 10100011 10100100 10100101 |
Завершенный двоичный поток: | |
0111 00001001 0100 00000101 10100001 10100010 10100011 10100100 10100101 | |
Пример декодирования таких данных приведен в 14.3.
7.4.2.3 Множественные ECI
В спецификации организации AIM, устанавливающей интерпретации в расширенном канале (ECI) <1>, содержатся правила, определяющие влияние последующих обозначений ECI в сегменте данных ECI. Например данные, к которым применили набор знаков ECI, могут также быть зашифрованы или уплотнены путем использования преобразования ECI, которое сосуществует с начальным ECI, или второй набор знаков ECI будет результатом завершения первого ECI и начала нового сегмента ECI. Если в данных появляется какой-либо присвоенный номер ECI, то он должен быть закодирован в символе QR Code в соответствии с 7.4.2.2 и сразу же за ним должен начинаться новый сегмент режима.
--------------------------------
<1> См. спецификацию [22].
7.4.2.4 ECI и структурированное соединение
Любую(ые) ECI следует применять по правилам, приведенным выше и в спецификации организации AIM, устанавливающей ECI, до окончания кодируемых данных или другой ECI (указанной индикатором режима 0111). Если кодируемые данные в режиме ECI должны быть размещены в двух или более символах в режиме структурированного соединения, необходимо предусмотреть заголовок ECI, состоящий из индикатора режима ECI и присвоенного номера ECI для каждого символа, для которого действует режим ECI, сразу после заголовка структурированного соединения.
Входную строку данных разделяют на группы по три цифры, а каждую группу преобразуют в 10-битовое двоичное число. Если число цифр не делится на три без остатка, последние одна или две цифры должны быть преобразованы в 4 или 7 битов соответственно. Двоичные данные объединяют и добавляют префикс индикатора режима и индикатора числа знаков. Размер в битах и битовое представление индикатора цифрового режима указаны в таблице 2, размер в битах индикатора числа знаков - в таблице 3. Число знаков входных данных преобразуют в двоичный эквивалент и добавляют как индикатор числа знаков после индикатора режима и перед кодируемыми данными.
Пример 1 - Преобразование для символа версии 1-H
Входные данные: | 01234567 | |
1 Разделяют на группы по три цифры: | 012 345 67 | |
2 Преобразуют каждую группу в ее двоичное представление: | ||
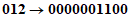 | ||
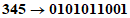 | ||
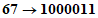 | ||
3 Соединяют в последовательность: 0000001100 0101011001 1000011 | ||
4 Преобразуют индикатор числа знаков в двоичный вид (10 бит для версии 1-H): | ||
Число знаков входных данных: | 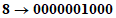 | |
5 Добавляют индикатор режима 0001 и индикатор числа знаков к двоичным данным: | ||
0001 0000001000 0000001100 0101011001 1000011 | ||
Пример 2 - Преобразование для символа Micro QR Code версии M3-M
Входные данные: 0123456789012345 | |
1 Разделяют на группы по три цифры: | 012 345 678 901 234 5 |
2 Преобразуют каждую группу в ее двоичное представление: | |
012 = 0000001100 | |
345 = 0101011001 | |
678 = 1010100110 | |
901 = 1110000101 | |
234 = 0011101010 | |
5 = 0101 | |
3 Соединяют вместе в последовательность: | |
0000001100 0101011001 1010100110 1110000101 0011101010 0101 | |
4 Преобразуют число знаков в индикатор числа знаков (5 битов для версии M3-M): | |
Число знаков входных данных: 16 = 10000 | |
5 Добавляют индикатор режима (00 для версии M3-M) и индикатор числа знаков к двоичным данным: | |
00 10000 0000001100 0101011001 1010100110 1110000101 0011101010 0101 | |
Для всех знаков входных данных длину двоичного потока для числового режима вычисляют по следующей формуле
B = M + C + 10(D DIV 3) + R,
где B - число битов в двоичном потоке;
M - размер индикатора режима в битах (4 - для символов QR Code или значение, указанное в таблице 2 для символов Micro QR Code);
C - размер индикатора числа знаков в битах (см. таблицу 3);
D - число знаков входных данных;
R = 0, если (D MOD 3) = 0;
R = 4, если (D MOD 3) = 1;
R = 7, если (D MOD 3) = 2.
7.4.4 Алфавитно-цифровой режим
Каждому знаку входных данных должно быть присвоено значение от 0 до 44 в соответствии с таблицей 5.
Таблица 5
Знак | Значение | Знак | Значение | Знак | Значение | Знак | Значение | Знак | Значение | Знак | Значение | Знак | Значение | Знак | Значение |
0 | 0 | 6 | 6 | C | 12 | I | 18 | O | 24 | U | 30 | SP | 36 | . | 42 |
1 | 1 | 7 | 7 | D | 13 | J | 19 | P | 25 | V | 31 | $ | 37 | / | 43 |
2 | 2 | 8 | 8 | E | 14 | K | 20 | Q | 26 | W | 32 | % | 38 | : | 44 |
3 | 3 | 9 | 9 | F | 15 | L | 21 | R | 27 | X | 33 | * | 39 | ||
4 | 4 | A | 10 | G | 16 | M | 22 | S | 28 | Y | 34 | + | 40 | ||
5 | 5 | B | 11 | H | 17 | N | 23 | T | 29 | Z | 35 | - | 41 |
Знаки входных данных разбивают на группы по два знака, и каждую группу преобразуют в 11-битовый двоичный код. Значение для первого знака умножают на 45 и к нему прибавляют значение для второго знака. Сумму преобразуют в 11-битовое двоичное число. Если во входных данных находится нечетное число знаков, последний знак кодируют 6-битовым двоичным числом. Двоичные данные объединяют, и перед ними вставляют индикатор режима и индикатор числа знаков. Размер и числовое значение индикатора режима для алфавитно-цифрового режима указаны в таблице 2; размер индикатора числа знаков в битах определяют в соответствии с таблицей 3. Число знаков входных данных преобразуют в двоичный эквивалент и добавляют как индикатор числа знаков после индикатора режима и перед кодируемыми данными.
В режиме FNC1 знак FNC1 может содержаться в передаваемых данных. В этом случае он должен быть представлен в алфавитно-цифровом режиме как знак "%". В 7.4.8.2, 7.4.8.3 и 14.4 приведено подробное описание кодирования и передачи FNC1 и %.
Пример - Преобразование для символа версии 1-H:
Входные данные: AC-42 | |
1 Определяют значения знаков в соответствии с таблицей 5: | |
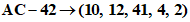 | |
2 Разделяют на группы по два десятичных значения: (10, 12) (41, 4) (2) | |
3 Преобразуют каждую группу в 11-битовый эквивалент: | |
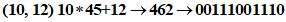 | |
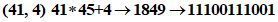 | |
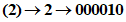 | |
4 Соединяют двоичные данные в последовательность: | |
00111001110 11100111001 000010 | |
5 Преобразуют число знаков в индикатор числа знаков (9 битов для версии 1-H): | |
Число знаков входных данных | 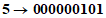 |
6 Добавляют индикатор режима 0010 и индикатор числа знаков: | |
0010 000000101 00111001110 11100111001 000010 | |
Для любого числа знаков входных данных размер двоичного потока для алфавитно-цифрового режима можно вычислить по формуле
B = M + C + 11(D DIV 2) + 6(D MOD 2),
где B - число битов в двоичном потоке;
M - размер индикатора режима в битах (4 для символов QR Code, или значение, указанное в таблице 2 для символов Micro QR Code);
C - размер индикатора числа знаков в битах (см. таблицу 3);
D - число знаков входных данных.
7.4.5 Байтовый режим
В этом режиме одно 8-битовое кодовое слово непосредственно представляет значение байтов входных данных, т.е. плотность кодирования 8 битов/знаков.
Таблица 6
Примечания
ИС МЕГАНОРМ: примечание. В официальном тексте документа, видимо, допущена опечатка: таблица H.2 отсутствует. |
1 В наборе знаков JIS8 (см. таблицу H.1) байтам со значениями с 80HEX по 9FHEX и с E0HEX по FFHEX не присвоены графические знаки, но сохранены значения. Некоторые из этих значений используют как первый байт в наборе знаков Shift JIS (см. таблицу H.2), а также для различения наборов знаков JIS8 и Shift JIS или для выполнения уплотнения в режиме кандзи. В JIS X 0208 приведены подробные сведения о кодированном представлении Shift.
2 Значения байтов с 00HEX по 7FHEX в наборе знаков JIS8 соответствуют ИСО/МЭК 8859-1 и ИСО/МЭК 646 версии IRV <1>, кроме значений 5CHEX и 7EHEX.
--------------------------------
<1> IRV - международная ссылочная версия 7-битового набора знаков (International Reference Version).
Перед двоичными данными вставляют индикатор режима и индикатор числа знаков. Размер и числовое значение индикатора режима для байтового режима указаны в таблице 2; размер индикатора числа символов в битах определяют в соответствии с таблицей 3. Число знаков входных данных преобразуют в двоичный эквивалент и добавляют как индикатор числа знаков после индикатора режима и перед кодируемыми данными.
Для любого числа входных знаков размер двоичного потока для байтового режима можно вычислить по формуле
B = M + C + 8D,
где B - число битов в двоичном потоке;
M - число битов в индикаторе режима (4 - для символов QR Code или значение, указанное в таблице 2 для Micro QR Code);
C - число битов в индикаторе числа знаков (см. таблицу 3);
D - число знаков входных данных.
В системе Shift JIS знаки кандзи представлены двухбайтовой комбинацией. Эти значения байта сдвинуты относительно значений по JIS X 0208. В JIS X 0208 приведены подробные сведения о кодированном представлении Shift. Входные знаки данных в режиме кандзи уплотнены из двойных кодовых слов в 13 битов в соответствии с требованиями, приведенными далее. Перед двоичными данными добавляют индикатор режима и индикатор числа знаков. Индикатор режима в режиме кандзи состоит или из 4 битов для символов QR Code или из числа битов, указанных в таблице 2, для символов Micro QR Code; индикатор числа знаков представлен числом битов в соответствии с таблицей 3. Число входных знаков данных преобразуют к его двоичному эквиваленту и добавляют как индикатор числа знаков после индикатора режима и перед последовательностью двоичных данных.
1 Для знаков со значениями Shift JIS от 8140HEX до 9FFCHEX:
a) вычитают 8140HEX из значения Shift JIS;
b) умножают старший байт значения, полученного на этапе a) на C0HEX;
c) прибавляют младший байт значения, вычисленного на этапе a) к значению, определенному на этапе b);
d) преобразуют значение в 13-битовую двоичную строку.
2 Для знаков со значениями Shift JIS от E040HEX до EBBFHEX:
a) вычитают C140HEX из значения Shift JIS;
b) умножают старший байт значения, полученного на этапе a) на C0HEX;
c) прибавляют младший байт значения, вычисленному на этапе a) к значению, определенному на этапе b);
d) преобразуют значение в 13-битовую двоичную строку.
Пример
Входной знак | ||
(значение Shift JIS): | 935F | E4AA |
1 Вычитают 8140 или C140 | 935F - 8140 = 121F | E4AA - C140 = 236A |
2 Умножают старший байт на C0 | 12 x 'C0 = D80 | 23 ... 'C0 = 1A40 |
3 Складывают с младшим байтом | D80 + 1F = D9F | 1A40 + 6A = 1AAA |
4 Преобразуют в 13-битовую строку | 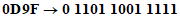 | 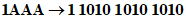 |
3 Для всех знаков:
e) перед двоичной последовательностью, представляющей входные знаки данных, вставляют индикатор режима (см. таблицу 2) и индикатор числа знаков (число битов приведено в таблице 3) в двоичном виде.
Для любого числа входных знаков данных размер двоичного потока для режима кандзи вычисляют по формуле
B = M + C + 13D,
где B - число битов в двоичном потоке;
M - число битов в индикаторе режима (4 - для символов QR Code или значение, приведенное в таблице 2 для символов Micro QR Code);
C - число битов в индикаторе числа знаков (см. таблицу 3);
D - число знаков входных данных.
Для символа допускается начать кодирование последовательности данных в одном режиме и затем изменить режим, если этого требует содержание данных или для увеличения плотности кодирования. Подробное руководство приведено в приложении J. Каждый сегмент данных кодируется в соответствующем режиме как указано в разделах с 7.4.2 по 7.4.6 на базе структуры индикатор режима/индикатор числа знаков/данные и сопровождается индикатором режима, начинающим следующий сегмент. На рисунке 13 представлена структура данных, содержащих n сегментов.
Сегмент 1 | Сегмент 2 | ... | Сегмент n | Ограничитель | ||||||
Индикатор режима 1 | Индикатор числа знаков | Данные | Индикатор режима 2 | Индикатор числа знаков | Данные | ... | Индикатор режима n | Индикатор числа знаков | Данные | |
Рисунок 13 - Формат данных в смешанном режиме
7.4.8 Режимы FNC1
7.4.8.1 Общие положения
В символах QR Code предусмотрены два индикатора режима, описание использования которых приведено в 7.3.2 - 7.3.9 и 7.4.2 - 7.4.7 для обозначения символов, которые закодированы по специальным международным отраслевым стандартам или стандартам по применению. Вместе с соответствующими данными они должны быть расположены перед обычными индикаторами режима, которые используют для эффективного кодирования данных. В случае использования таких индикаторов в декодерах должна быть предусмотрена возможность получения идентификатора символики, как определено в 14.2 и приложении F.
Примечание - "Первая позиция" фактически такой не является, но исторически соотносится с положением знака символа FNC1 в символах Code 128.
Указанный индикатор режима предназначен для обозначения символов, кодирующих данные в формате стандарта GS1, устанавливающего идентификаторы применения (Application Identifiers, AI). Для этой цели данный индикатор следует использовать в символе только один раз, и он должен быть расположен перед самым первым индикатором режима, используемым для эффективного кодирования данных (в числовом, алфавитно-цифровом, байтовом режиме или режиме кандзи), а также после заголовков ECI и/или структурированного соединения, если они присутствуют. Если спецификации GS1 требуют применения знака FNC1 (в других символиках, которые используют этот специальный знак) в качестве разделителя полей данных (то есть в конце поля данных переменной длины), в символах QR Code следует использовать знак % в алфавитно-цифровом режиме или знак GS (шестнадцатеричное значение байта 1DHEX) в байтовом режиме для выполнения этой функции. Если знак % встречается как часть данных, он должен быть закодирован как %%. Если на вход декодера поступает знак %, то его следует интерпретировать как знак набора ASCII/JIS8 с шестнадцатеричным значением 1DHEX, а если %%, то как единственный знак %.
Пример 1
Входные данные: | 0104912345123459 (идентификатор применения 01, указывающий глобальный номер предмета торговли GS1, поле фиксированной длины; данные: 04912345123459); 15970331 (идентификатор применения 15, указывающий дату реализации в формате ГГММДД, поле фиксированной длины; данные: 31 марта 1997); 30128 (идентификатор применения 30, указывающий число предметов, поле переменной длины; данные: 128) (требуется знак-разделитель); 10ABC123 (идентификатор применения 10, указывающий номер партии, поле переменной длины; данные: ABC123). |
Данные для кодирования: | 01049123451234591597033130128%1ABC123 |
Битовая последовательность в символе: | 0101 (индикатор режима, знак FNC1 в 1-й позиции); 0001 (индикатор режима, цифровой режим); 0000011101 (индикатор числа знаков, 29) <двоичные данные для 01049123451234591597033130128> 0010 (индикатор режима, алфавитно-цифровой режим) 000001001 (индикатор числа знаков, 9) < двоичные данные для %10ABC123> |
Передаваемые данные (см. 14.2 и приложение F) | ]Q301049123451234591597033130128<1DHEX>10ABC123 |
Пример 2 - Кодирование/декодирование знака % в данных:
Входные данные: | 123%; |
Кодируют: | 123%%; |
Передают: | 123%. |
Примечание - "Вторая позиция" фактически такой не является, но исторически соотносится с положением знака символа FNC1 в символах Code 128.
Данный индикатор режима указывает, что данные соответствуют определенным отраслевым спецификациям или спецификациям по применению, предварительно согласованным с организацией AIM International. Сразу после него следует однобайтовое кодовое слово, значение которого соответствует номеру прикладного индикатора (Application Indicator), присвоенному организацией AIM International, для указания этой спецификации. Для этой цели индикатор следует использовать в символе только один раз; и он должен быть расположен перед самым первым индикатором режима, используемым для эффективного кодирования данных (в числовом, алфавитно-цифровом, байтовом режиме или режиме кандзи), а также после заголовков ECI и/или структурированного соединения, если они присутствуют. Прикладной индикатор может иметь форму любой одиночной буквы латинского алфавита из набора {a - z, A - Z} (представленной значением знака ASCII плюс 100) или двузначного числа (представленного его числовым значением) и должен быть передан декодером как первые один или два знака непосредственно перед данными. Если спецификации по применению требуют использования знака FNC1 (в других символиках, которые используют этот специальный знак) в качестве разделителя полей данных (то есть в конце поля данных переменной длины), в символах QR Code, следует использовать знак % в алфавитно-цифровом режиме или знак GS (шестнадцатеричное значение байта 1DHEX) в байтовом режиме для выполнения этой функции. Если знак % является частью данных, он должен быть закодирован как %%. Если на вход декодера поступает знак %, то его следует интерпретировать как знак ASCII/JIS8 с шестнадцатеричным значением 1DHEX, а если %%, то как одиночный знак %.
Пример
Примечание - Прикладной индикатор 37 на момент публикации настоящего стандарта не был присвоен ни одной организации, поэтому в примере приведены условные значения.
Прикладной индикатор: | 37 |
Входные данные: | AA1234BBB112text text text text<CR> <1> |
Битовая последовательность в символе: | 1001 (индикатор режима, знак FNC1 во второй позиции) 00100101 (прикладной индикатор, 37) 0010 (индикатор режима, алфавитно-цифровой режим) 000001100 (индикатор числа знаков, 12) <двоичные данные для AA1234BBB112> 0100 (индикатор режима, байтовый режим) 00010100 (индикатор числа знаков, 20) <двоичные данные для text text text text<CR>> |
Передаваемые данные: | ]Q537AA1234BBB112text text text text<CR> |
--------------------------------
Конец данных должен быть обозначен ограничителем, состоящим из последовательности нулевых битов согласно таблице 2, и добавлен к двоичному потоку данных после данных последнего сегмента режима. Ограничитель может отсутствовать, если оставшаяся после данных емкость символа меньше требуемой длины ограничителя в битах.
7.4.10 Преобразование двоичного потока в кодовые слова
Двоичные потоки, соответствующие каждому сегменту режима, должны быть соединены в порядке кодирования. Ограничитель должен быть добавлен к окончанию законченного двоичного потока согласно 7.4.9. Результирующий двоичный поток сообщения разбивают на кодовые слова. Все кодовые слова имеют размер 8 битов, кроме последнего знака символа для символов Micro QR Code версии M1 и M3, где размер должен быть равен 4 битам. Если длина двоичного потока такова, что он не заканчивается на границе кодового слова, то после последнего (младшего значащего) бита потока добавляют биты заполнители, имеющие значение 0, чтобы продлить поток до границы кодового слова. Затем, если сообщение не заполняет целиком емкость символа соответствующей версии и уровня исправления ошибок в соответствии с таблицей 8, он должен быть расширен путем поочередного добавления к его окончанию кодовых слов-заполнителей 11101100 и 00010001. В символах Micro QR Code версий M1 и M3 последнее кодовое слово имеет размер 4 бита. Кодовое слово-заполнитель, попадающее на этот заключительный знак данных символа в версиях M1 и M3 Micro QR Code, должно быть представлено как 0000. Для получения результирующей последовательности кодовых слов последовательность кодовых слов данных обрабатывают согласно 7.5 для добавления кодовых слов исправления ошибок. Кроме того, в символах некоторых версий необходимо добавить 3, 4 или 7 остаточных битов (все биты имеют значение 0) к окончанию сообщения после последнего кодового слова исправления ошибок, чтобы полностью заполнить емкость символа (см. таблицу 7).
Таблица 7
Версия | Уровень исправления ошибок | Число кодовых слов данных | Число битов для данных | Емкость данных для разных режимов | |||
Цифровой | Алфавитно-цифровой | Байтовый | Кандзи | ||||
M1 | Только обнаружение ошибок | 3 | 20 | 5 | - | - | - |
M2 | L | 5 | 40 | 10 | 6 | - | - |
M | 4 | 32 | 8 | 5 | - | - | |
M3 | L | 11 | 84 | 23 | 14 | 9 | 6 |
M | 9 | 68 | 18 | 11 | 7 | 4 | |
M4 | L | 16 | 128 | 35 | 21 | 15 | 9 |
M | 14 | 112 | 30 | 18 | 13 | 8 | |
Q | 10 | 80 | 21 | 13 | 9 | 5 | |
1 | L | 19 | 152 | 41 | 25 | 17 | 10 |
M | 16 | 128 | 34 | 20 | 14 | 8 | |
Q | 13 | 104 | 27 | 16 | 11 | 7 | |
H | 9 | 72 | 17 | 10 | 7 | 4 | |
2 | L | 34 | 272 | 77 | 47 | 32 | 20 |
M | 28 | 224 | 63 | 38 | 26 | 16 | |
Q | 22 | 176 | 48 | 29 | 20 | 12 | |
H | 16 | 128 | 34 | 20 | 14 | 8 | |
3 | L | 55 | 440 | 127 | 77 | 53 | 32 |
M | 44 | 352 | 101 | 61 | 42 | 26 | |
Q | 34 | 272 | 77 | 47 | 32 | 20 | |
H | 26 | 208 | 58 | 35 | 24 | 15 | |
4 | L | 80 | 640 | 187 | 114 | 78 | 48 |
H | 64 | 512 | 149 | 90 | 62 | 38 | |
Q | 48 | 384 | 111 | 67 | 46 | 28 | |
H | 36 | 288 | 82 | 50 | 34 | 21 | |
5 | L | 108 | 864 | 255 | 154 | 106 | 65 |
M | 86 | 688 | 202 | 122 | 84 | 52 | |
Q | 62 | 496 | 144 | 87 | 60 | 37 | |
H | 46 | 368 | 106 | 64 | 44 | 27 | |
6 | L | 136 | 1 088 | 322 | 195 | 134 | 82 |
M | 108 | 864 | 255 | 154 | 106 | 65 | |
Q | 76 | 608 | 178 | 108 | 74 | 45 | |
H | 60 | 480 | 139 | 84 | 58 | 36 | |
7 | L | 156 | 1 248 | 370 | 224 | 154 | 95 |
M | 124 | 992 | 293 | 178 | 122 | 75 | |
Q | 88 | 704 | 207 | 125 | 86 | 53 | |
H | 66 | 528 | 154 | 93 | 64 | 39 | |
8 | L | 194 | 1 552 | 461 | 279 | 192 | 118 |
M | 154 | 1 232 | 365 | 221 | 152 | 93 | |
Q | 110 | 880 | 259 | 157 | 108 | 66 | |
H | 86 | 688 | 202 | 122 | 84 | 52 | |
9 | L | 232 | 1 856 | 552 | 335 | 230 | 141 |
M | 182 | 1 456 | 432 | 262 | 180 | 111 | |
Q | 132 | 1 056 | 312 | 189 | 130 | 80 | |
H | 100 | 800 | 235 | 143 | 98 | 60 | |
10 | L | 274 | 2 192 | 652 | 395 | 271 | 167 |
M | 216 | 1 728 | 513 | 311 | 213 | 131 | |
Q | 154 | 1 232 | 364 | 221 | 151 | 93 | |
H | 122 | 976 | 288 | 174 | 119 | 74 | |
11 | L | 324 | 2 592 | 772 | 468 | 321 | 198 |
M | 254 | 2 032 | 604 | 366 | 251 | 155 | |
Q | 180 | 1 440 | 427 | 259 | 177 | 109 | |
H | 140 | 1 120 | 331 | 200 | 137 | 85 | |
12 | L | 370 | 2 960 | 883 | 535 | 367 | 226 |
M | 290 | 2 320 | 691 | 419 | 287 | 177 | |
Q | 206 | 1 648 | 489 | 296 | 203 | 125 | |
H | 158 | 1 264 | 374 | 227 | 155 | 96 | |
13 | L | 428 | 3 424 | 1 022 | 619 | 425 | 262 |
M | 334 | 2 672 | 796 | 483 | 331 | 204 | |
Q | 244 | 1 952 | 580 | 352 | 241 | 149 | |
H | 180 | 1 440 | 427 | 259 | 177 | 109 | |
14 | L | 461 | 3 688 | 1 101 | 667 | 458 | 282 |
M | 365 | 2 920 | 871 | 528 | 362 | 223 | |
Q | 261 | 2 088 | 621 | 376 | 258 | 159 | |
H | 197 | 1 576 | 468 | 283 | 194 | 120 | |
15 | L | 523 | 4 184 | 1 250 | 758 | 520 | 320 |
M | 415 | 3 320 | 991 | 600 | 412 | 254 | |
Q | 295 | 2 360 | 703 | 426 | 292 | 180 | |
H | 223 | 1 784 | 530 | 321 | 220 | 136 | |
16 | L | 589 | 4 712 | 1 408 | 854 | 586 | 361 |
M | 453 | 3 624 | 1 082 | 656 | 450 | 277 | |
Q | 325 | 2 600 | 775 | 470 | 322 | 198 | |
H | 253 | 2 024 | 602 | 365 | 250 | 154 | |
17 | L | 647 | 5 176 | 1 548 | 938 | 644 | 397 |
M | 507 | 4 056 | 1 212 | 734 | 504 | 310 | |
Q | 367 | 2 936 | 876 | 531 | 364 | 224 | |
H | 283 | 2 264 | 674 | 408 | 280 | 173 | |
18 | L | 721 | 5 768 | 1 725 | 1 046 | 718 | 442 |
M | 563 | 4 504 | 1 346 | 816 | 560 | 345 | |
Q | 397 | 3 176 | 948 | 574 | 394 | 243 | |
H | 313 | 2 504 | 746 | 452 | 310 | 191 | |
19 | L | 795 | 6 360 | 1 903 | 1 153 | 792 | 488 |
M | 627 | 5 016 | 1 500 | 909 | 624 | 384 | |
Q | 445 | 3 560 | 1 063 | 644 | 442 | 272 | |
H | 341 | 2 728 | 813 | 493 | 338 | 208 | |
20 | L | 861 | 6 888 | 2 061 | 1 249 | 858 | 528 |
M | 669 | 5 352 | 1 600 | 970 | 666 | 410 | |
Q | 485 | 3 880 | 1 159 | 702 | 482 | 297 | |
H | 385 | 3 080 | 919 | 557 | 382 | 235 | |
21 | L | 932 | 7 456 | 2 232 | 1 352 | 929 | 572 |
M | 714 | 5 712 | 1 708 | 1 035 | 711 | 438 | |
Q | 512 | 4 096 | 1 224 | 742 | 509 | 314 | |
H | 406 | 3 248 | 969 | 587 | 403 | 248 | |
22 | L | 1 006 | 8 048 | 2 409 | 1 460 | 1 003 | 618 |
M | 782 | 6 256 | 1 872 | 1 134 | 779 | 480 | |
Q | 568 | 4 544 | 1 358 | 823 | 565 | 348 | |
H | 442 | 3 536 | 1 056 | 640 | 439 | 270 | |
23 | L | 1 094 | 8 752 | 2 620 | 1 588 | 1 091 | 672 |
M | 860 | 6 880 | 2 059 | 1 248 | 857 | 528 | |
Q | 614 | 4 912 | 1 468 | 890 | 611 | 376 | |
H | 464 | 3 712 | 1 108 | 672 | 461 | 284 | |
24 | L | 1 174 | 9 392 | 2 812 | 1 704 | 1 171 | 721 |
M | 914 | 7 312 | 2 188 | 1 326 | 911 | 561 | |
Q | 664 | 5 312 | 1 588 | 963 | 661 | 407 | |
H | 514 | 4 112 | 1 228 | 744 | 511 | 315 | |
25 | L | 1 276 | 10 208 | 3 057 | 1 853 | 1 273 | 784 |
M | 1 000 | 8 000 | 2 395 | 1 451 | 997 | 614 | |
Q | 718 | 5 744 | 1 718 | 1 041 | 715 | 440 | |
H | 538 | 4 304 | 1 286 | 779 | 535 | 330 | |
26 | L | 1 370 | 10 960 | 3 283 | 1 990 | 1 367 | 842 |
M | 1 062 | 8 496 | 2 544 | 1 542 | 1 059 | 652 | |
Q | 754 | 6 032 | 1 804 | 1 094 | 751 | 462 | |
H | 596 | 4 768 | 1 425 | 864 | 593 | 365 | |
27 | L | 1 468 | 11 744 | 3 517 | 2 132 | 1 465 | 902 |
M | 1 128 | 9 024 | 2 701 | 1 637 | 1 125 | 692 | |
Q | 808 | 6 464 | 1 933 | 1 172 | 805 | 496 | |
H | 628 | 5 024 | 1 501 | 910 | 625 | 385 | |
28 | L | 1 531 | 12 248 | 3 669 | 2 223 | 1 528 | 940 |
M | 1 193 | 9 544 | 2 857 | 1 732 | 1 190 | 732 | |
Q | 871 | 6 968 | 2 085 | 1 263 | 868 | 534 | |
H | 661 | 5 288 | 1 581 | 958 | 658 | 405 | |
29 | L | 1 631 | 13 048 | 3 909 | 2 369 | 1 628 | 1 002 |
M | 1 267 | 10 136 | 3 035 | 1 839 | 1 264 | 778 | |
Q | 911 | 7 288 | 2 181 | 1 322 | 908 | 559 | |
H | 701 | 5 608 | 1 677 | 1 016 | 698 | 430 | |
30 | L | 1 735 | 13 880 | 4 158 | 2 520 | 1 732 | 1 066 |
M | 1 373 | 10 984 | 3 289 | 1 994 | 1 370 | 843 | |
Q | 985 | 7 880 | 2 358 | 1 429 | 982 | 604 | |
H | 745 | 5 960 | 1 782 | 1 080 | 742 | 457 | |
31 | L | 1 843 | 14 744 | 4 417 | 2 677 | 1 840 | 1 132 |
M | 1 455 | 11 640 | 3 486 | 2 113 | 1 452 | 894 | |
Q | 1 033 | 8 264 | 2 473 | 1 499 | 1 030 | 634 | |
H | 793 | 6 344 | 1 897 | 1 150 | 790 | 486 | |
32 | L | 1 955 | 15 640 | 4 686 | 2 840 | 1 952 | 1 201 |
M | 1 541 | 12 328 | 3 693 | 2 238 | 1 538 | 947 | |
Q | 1 115 | 8 920 | 2 670 | 1 618 | 1 112 | 684 | |
H | 845 | 6 760 | 2 022 | 1 226 | 842 | 518 | |
33 | L | 2 071 | 16 568 | 4 965 | 3 009 | 2 068 | 1 273 |
M | 1 631 | 13 048 | 3 909 | 2 369 | 1 628 | 1 002 | |
Q | 1 171 | 9 368 | 2 805 | 1 700 | 1 168 | 719 | |
H | 901 | 7 208 | 2 157 | 1 307 | 898 | 553 | |
34 | L | 2 191 | 17 528 | 5 253 | 3 183 | 2 188 | 1 347 |
M | 1 725 | 13 800 | 4 134 | 2 506 | 1 722 | 1 060 | |
Q | 1 231 | 9 848 | 2 949 | 1 787 | 1 228 | 756 | |
H | 961 | 7 688 | 2 301 | 1 394 | 958 | 590 | |
35 | L | 2 306 | 18 448 | 5 529 | 3 351 | 2 303 | 1 417 |
M | 1 812 | 14 496 | 4 343 | 2 632 | 1 809 | 1 113 | |
Q | 1 286 | 10 288 | 3 081 | 1 867 | 1 283 | 790 | |
H | 986 | 7 888 | 2 361 | 1 431 | 983 | 605 | |
36 | L | 2 434 | 19 472 | 5 836 | 3 537 | 2 431 | 1 496 |
M | 1 914 | 15 312 | 4 588 | 2 780 | 1 911 | 1 176 | |
Q | 1 354 | 10 832 | 3 244 | 1 966 | 1 351 | 832 | |
H | 1 054 | 8 432 | 2 524 | 1 530 | 1 051 | 647 | |
37 | L | 2 566 | 20 528 | 6 153 | 3 729 | 2 563 | 1 577 |
M | 1 992 | 15 936 | 4 775 | 2 894 | 1 989 | 1 224 | |
Q | 1 426 | 11 408 | 3417 | 2 071 | 1 423 | 876 | |
H | 1 096 | 8 768 | 2 625 | 1 591 | 1 093 | 673 | |
38 | L | 2 702 | 21 616 | 6 479 | 3 927 | 2 699 | 1 661 |
M | 2 102 | 16 816 | 5 039 | 3 054 | 2 099 | 1 292 | |
Q | 1 502 | 12 016 | 3 599 | 2 181 | 1 499 | 923 | |
H | 1 142 | 9 136 | 2 735 | 1 658 | 1 139 | 701 | |
39 | L | 2 812 | 22 496 | 6 743 | 4 087 | 2 809 | 1 729 |
M | 2 216 | 17 728 | 5 313 | 3 220 | 2 213 | 1 362 | |
Q | 1 582 | 12 656 | 3 791 | 2 298 | 1 579 | 972 | |
H | 1 222 | 9 776 | 2 927 | 1 774 | 1 219 | 750 | |
40 | L | 2 956 | 23 648 | 7 089 | 4 296 | 2 953 | 1 817 |
M | 2 334 | 18 672 | 5 596 | 3 391 | 2 331 | 1 435 | |
Q | 1 666 | 13 328 | 3 993 | 2 420 | 1 663 | 1 024 | |
H | 1 276 | 10 208 | 3 057 | 1 852 | 1 273 | 784 | |
Примечание 1 - Все кодовые слова имеют размер 8 битов, за исключением последнего кодового слова данных для символов версии M1 и M3, длина которого составляет 4.
Примечание 2 - В число битов данных включены биты индикатора режима и индикатора числа знаков.
7.5.1 Способность к исправлению ошибок
В символике QR Code используют коды Рида-Соломона для обнаружения и исправления ошибок. Генерируется ряд кодовых слов исправления ошибок, которые добавляются к последовательности кодовых слов данных, чтобы обеспечить считывание символа без потери данных при его повреждении. Пользователь может выбрать один из четырех уровней исправления ошибок, приведенных в таблице 8, обеспечивающих различную способность к восстановлению в зависимости от степени повреждения:
Таблица 8
Уровень исправления ошибок | Способность к восстановлению, % (прибл.) |
L | 7 |
M | 15 |
Q | 25 |
H | 30 |
В приложении K.2 приведены рекомендации по выбору уровня исправления ошибок, который следует применить к символу.
Уровень исправления ошибок H недоступен в символах Micro QR Code.
Кодовые слова исправления ошибок обеспечивают исправление двух типов поврежденных кодовых слов: стирания (ошибочные кодовые слова, которые находятся на известных позициях) и ошибки (ошибочные кодовые слова, которые находятся на неизвестных позициях). Стираниями являются неотсканированные или нераспознанные знаки символа. Ошибка замены - это неправильно декодированный знак символа. Так как QR Code - это матричная символика, несовершенство преобразования модуля из темного в светлый или наоборот приводит к тому, что в результате получается неправильно декодированный знак символа как вероятно допустимый, однако соответствующий другому кодовому слову. Такие ошибки, приводящие к изменениям данных, требуют применения двух кодовых слов исправления ошибок для исправления.
Число стираний и ошибок, которые можно исправить одновременно, вычисляют по следующей формуле
e + 2t <= d - p,
где e - число стираний;
t - число ошибок;
d - число кодовых слов исправления ошибок;
p - число кодовых слов, зарезервированных для обнаружения ошибок.
В общем случае p = 0. Если для исправления ошибок используется  часть способности к исправлению, то увеличивается вероятность необнаружения ошибки. Всякий раз, когда число стираний больше половины числа кодовых слов исправления ошибок, используют p = 3. Для небольших символов, где число кодовых слов исправления ошибок менее 8, не следует использовать исправление стираний (для исправления ошибок следует применять e = 0 и p > 0).
часть способности к исправлению, то увеличивается вероятность необнаружения ошибки. Всякий раз, когда число стираний больше половины числа кодовых слов исправления ошибок, используют p = 3. Для небольших символов, где число кодовых слов исправления ошибок менее 8, не следует использовать исправление стираний (для исправления ошибок следует применять e = 0 и p > 0).
часть способности к исправлению, то увеличивается вероятность необнаружения ошибки. Всякий раз, когда число стираний больше половины числа кодовых слов исправления ошибок, используют p = 3. Для небольших символов, где число кодовых слов исправления ошибок менее 8, не следует использовать исправление стираний (для исправления ошибок следует применять e = 0 и p > 0).Например, в символе версии 6-H всего 172 кодовых слова, из которых 112 - кодовые слова исправления ошибок, оставшиеся 60 - кодовые слова данных. 112 кодовых слов исправления ошибок позволяют исправить 56 ошибок, т.е. отношение 56/172 соответствует 32,6% емкости символа.
В вышеприведенной формуле p должно иметь следующие значения:
- p = 3 для символов версии 1-L и M2-L;
- p = 2 для символов версии 1-M, 2-L, M1, M2-M, M3-L, и M4-L;
- p = 1 для символов версии 1-Q, 1-H и 3-L;
- p = 0 для всех остальных случаев.
Если p > 0 (т.е. 1, 2 или 3), то p кодовых слов действуют как кодовые слова обнаружения неисправимых ошибок и предотвращают передачу данных от символов, где число ошибок превышает способность к исправлению ошибок, и e должно быть менее d/2. В символе версии 2-L, например, общее число кодовых слов 44; из них 34 кодовых слова данных и 10 кодовых слов исправления ошибок. В соответствии с таблицей 9 способность к исправлению ошибок равна четырем ошибкам (где e = 0). Подставляют в вышеуказанную формулу
0 + (2 x 4) = 10 - 2,
учитывая, что для исправления четырех ошибок требуется только 8 кодовых слов исправления ошибок; оставшиеся два кодовых слова могут только обнаружить (но не исправить) любую дополнительную ошибку в символе и, таким образом, если ошибок более четырех, декодирование не приводит к успеху.
В зависимости от версии и уровня исправления ошибок последовательность кодовых слов данных разбивают на один или более блоков, к каждому из которых по отдельности следует применить алгоритм исправления ошибок. В таблице 9 для каждой версии и уровня исправления ошибок приведено общее число кодовых слов, число кодовых слов данных и кодовых слов исправления ошибок, а также структура и число блоков исправления ошибок.
Таблица 9
Версия | Общее число кодовых слов | Уровень исправления ошибок | Число кодовых слов исправления ошибок | Значение p | Число блоков исправления ошибок | Код исправления ошибок в блоке (c, k, r) <a> |
M1 | 5 | Только обнаружение | 2 | 2 | 1 | (5, 3, 0) <b> |
M2 | 10 | L | 5 | 3 | 1 | (10, 5, 1) <b> |
M | 6 | 2 | 1 | (10, 4, 2) <b> | ||
M3 | 17 | L | 6 | 2 | 1 | (17, 11, 2) <b> |
M | 8 | 1 | (17, 9, 4) | |||
M4 | 24 | L | 8 | 2 | 1 | (24, 16, 3) <b> |
M | 10 | 0 | 1 | (24, 14, 5) | ||
Q | 14 | 0 | 1 | (24, 10, 7) | ||
1 | 26 | L | 7 | 3 | 1 | (26, 19, 2) <b> |
M | 10 | 2 | 1 | (26, 16, 4) <b> | ||
Q | 13 | 1 | 1 | (26, 13, 6) <b> | ||
H | 17 | 1 | 1 | (26, 9, 8) <b> | ||
2 | 44 | L | 10 | 2 | 1 | (44, 34, 4) <b> |
M | 16 | 0 | 1 | (44, 28, 8) | ||
Q | 22 | 0 | 1 | (44, 22, 11) | ||
H | 28 | 0 | 1 | (44, 16, 14) | ||
3 | 70 | L | 15 | 1 | 1 | (70, 55, 7) <b> |
M | 26 | 0 | 1 | (70, 44, 13) | ||
Q | 36 | 0 | 2 | (35, 17, 9) | ||
H | 44 | 0 | 2 | (35, 13, 11) | ||
4 | 100 | L | 20 | 0 | 1 | (100, 80, 10) |
M | 36 | 2 | (50, 32, 9) | |||
Q | 52 | 2 | (50, 24, 13) | |||
H | 64 | 4 | (25, 9, 8) | |||
5 | 134 | 0 | 1 | (134, 108, 13) | ||
L | 26 | 2 | (67, 43, 12) | |||
M | 48 | 2 | (33, 15, 9) | |||
Q | 72 | 2 | (34, 16, 9) | |||
H | 88 | 2 | (33, 11, 11) | |||
2 | (34, 12, 11) | |||||
6 | 172 | L | 36 | 0 | 2 | (86, 68, 9) |
M | 64 | 4 | (43, 27, 8) | |||
Q | 96 | 4 | (43, 19, 12) | |||
H | 112 | 4 | (43, 15, 14) | |||
7 | 196 | L | 40 | 0 | 2 | (98, 78, 10) |
M | 72 | 4 | (49, 31, 9) | |||
Q | 108 | 2 | (32, 14, 9) | |||
4 | (33, 15, 9) | |||||
H | 130 | 4 | (39, 13, 13) | |||
1 | (40, 14, 13) | |||||
8 | 242 | L | 48 | 0 | 2 | (121, 97, 12) |
M | 88 | 2 | (60, 38, 11) | |||
2 | (61, 39, 11) | |||||
Q | 132 | 4 | (40, 18, 11) | |||
2 | (41, 19, 11) | |||||
H | 156 | 4 | (40, 14, 13) | |||
2 | (41, 15, 13) | |||||
9 | 292 | L | 60 | 0 | 2 | (146, 116, 15) |
M | 110 | 3 | (58, 36, 11) | |||
2 | (59, 37, 11) | |||||
Q | 160 | 4 | (36, 16, 10) | |||
4 | (37, 17, 10) | |||||
H | 192 | 4 | (36, 12, 12) | |||
4 | (37, 13, 12) | |||||
10 | 346 | L | 72 | 0 | 2 | (86, 68, 9) |
2 | (87, 69, 9) | |||||
M | 130 | 4 | (69, 43, 13) | |||
1 | (70, 44, 13) | |||||
Q | 192 | 6 | (43, 19, 12) | |||
2 | (44, 20, 12) | |||||
H | 224 | 6 | (43, 15, 14) | |||
2 | (44, 16, 14) | |||||
11 | 404 | L | 80 | 0 | 4 | (101, 81, 10) |
M | 150 | 1 | (80, 50, 15) | |||
4 | (81, 51, 15) | |||||
Q | 224 | 4 | (50, 22, 14) | |||
4 | (51, 23, 14) | |||||
H | 264 | 3 | (36, 12, 12) | |||
8 | (37, 13, 12) | |||||
12 | 466 | L | 96 | 0 | 2 | (116, 92, 12) |
2 | (117, 93, 12) | |||||
M | 176 | 6 | (58, 36, 11) | |||
2 | (59, 37, 11) | |||||
Q | 260 | 4 | (46, 20, 13) | |||
6 | (47, 21, 13) | |||||
H | 308 | 7 | (42, 14, 14) | |||
4 | (43, 15, 14) | |||||
13 | 532 | L | 104 | 0 | 4 | (133, 107, 13) |
M | 198 | 8 | (59, 37, 11) | |||
1 | (60, 38, 11) | |||||
Q | 288 | 8 | (44, 20, 12) | |||
4 | (45, 21, 12) | |||||
H | 352 | 12 | (33, 11, 11) | |||
4 | (34, 12, 11) | |||||
14 | 581 | L | 120 | 0 | 3 | (145, 115, 15) |
1 | (146, 116, 15) | |||||
M | 216 | 4 | (64, 40, 12) | |||
5 | (65, 41, 12) | |||||
Q | 320 | 11 | (36, 16, 10) | |||
5 | (37, 17, 10) | |||||
H | 384 | 11 | (36, 12, 12) | |||
5 | (37, 13, 12) | |||||
15 | 655 | L | 132 | 0 | 5 | (109, 87, 11) |
1 | (110, 88, 11) | |||||
M | 240 | 5 | (65, 41, 12) | |||
5 | (66, 42, 12) | |||||
Q | 360 | 5 | (54, 24, 15) | |||
7 | (55, 25, 15) | |||||
H | 432 | 11 | (36, 12, 12) | |||
7 | (37, 13, 12) | |||||
16 | 733 | L | 144 | 0 | 5 | (122, 98, 12) |
1 | (123, 99, 12) | |||||
M | 280 | 7 | (73, 45, 14) | |||
3 | (74, 46, 14) | |||||
Q | 408 | 15 | (43, 19, 12) | |||
2 | (44, 20, 12) | |||||
H | 480 | 3 | (45, 15, 15) | |||
13 | (46, 16, 15) | |||||
17 | 815 | L | 168 | 0 | 1 | (135, 107, 14) |
5 | (136, 108, 14) | |||||
M | 308 | 10 | (74, 46, 14) | |||
1 | (75, 47, 14) | |||||
Q | 448 | 1 | (50, 22, 14) | |||
15 | (51, 23, 14) | |||||
H | 532 | 2 | (42, 14, 14) | |||
17 | (43, 15, 14) | |||||
18 | 901 | L | 180 | 0 | 5 | (150, 120, 15) |
1 | (151, 121, 15) | |||||
M | 338 | 9 | (69, 43, 13) | |||
4 | (70, 44, 13) | |||||
Q | 504 | 17 | (50, 22, 14) | |||
1 | (51, 23, 14) | |||||
H | 588 | 2 | (42, 14, 14) | |||
19 | (43, 15, 14) | |||||
19 | 991 | L | 196 | 0 | 3 | (141, 113, 14) |
4 | (142, 114, 14) | |||||
M | 364 | 3 | (70, 44, 13) | |||
11 | (71, 45, 13) | |||||
Q | 546 | 17 | (47, 21, 13) | |||
4 | (48, 22, 13) | |||||
H | 650 | 9 | (39, 13, 13) | |||
16 | (40, 14, 13) | |||||
20 | 1 085 | L | 224 | 0 | 3 | (135, 107, 14) |
5 | (136, 108, 14) | |||||
M | 416 | 3 | (67, 41, 13) | |||
13 | (68, 42, 13) | |||||
Q | 600 | 15 | (54, 24, 15) | |||
5 | (55, 25, 15) | |||||
H | 700 | 15 | (43, 15, 14) | |||
10 | (44, 16, 14) | |||||
21 | 1 156 | L | 224 | 0 | 4 | (144, 116, 14) |
4 | (145, 117, 14) | |||||
M | 442 | 17 | (68, 42, 13) | |||
Q | 644 | 17 | (50, 22, 14) | |||
6 | (51, 23, 14) | |||||
H | 750 | 19 | (46, 16, 15) | |||
6 | (47, 17, 15) | |||||
22 | 1 258 | L | 252 | 0 | 2 | (139, 111, 14) |
7 | (140, 112, 14) | |||||
M | 476 | 17 | (74, 46, 14) | |||
Q | 690 | 7 | (54, 24, 15) | |||
16 | (55, 25, 15) | |||||
H | 816 | 34 | (37, 13, 12) | |||
23 | 1 364 | L | 270 | 0 | 4 | (151, 121, 15) |
5 | (152, 122, 15) | |||||
M | 504 | 4 | (75, 47, 14) | |||
14 | (76, 48, 14) | |||||
Q | 750 | 11 | (54, 24, 15) | |||
14 | (55, 25, 15) | |||||
H | 900 | 16 | (45, 15, 15) | |||
14 | (46, 16, 15) | |||||
24 | 1 474 | L | 300 | 0 | 6 | (147, 117, 15) |
4 | (148, 118, 15) | |||||
M | 560 | 6 | (73, 45, 14) | |||
14 | (74, 46, 14) | |||||
Q | 810 | 11 | (54, 24, 15) | |||
16 | (55, 25, 15) | |||||
H | 960 | 30 | (46, 16, 15) | |||
2 | (47, 17, 15) | |||||
25 | 1 588 | L | 312 | 0 | 8 | (132, 106, 13) |
4 | (133, 107, 13) | |||||
M | 588 | 8 | (75, 47, 14) | |||
13 | (76, 48, 14) | |||||
Q | 870 | 7 | (54, 24, 15) | |||
22 | (55, 25, 15) | |||||
H | 1 050 | 22 | (45, 15, 15) | |||
13 | (46, 16, 15) | |||||
26 | 1 706 | L | 336 | 0 | 10 | (142, 114, 14) |
2 | (143, 115, 14) | |||||
M | 644 | 19 | (74, 46, 14) | |||
4 | (75, 47, 14) | |||||
Q | 952 | 28 | (50, 22, 14) | |||
6 | (51, 23, 14) | |||||
H | 1 110 | 33 | (46, 16, 15) | |||
4 | (47, 17, 15) | |||||
27 | 1 828 | L | 360 | 0 | 8 | (152, 122, 15) |
4 | (153, 123, 15) | |||||
M | 700 | 22 | (73, 45, 14) | |||
3 | (74, 46, 14) | |||||
Q | 1 020 | 8 | (53, 23, 15) | |||
26 | (54, 24, 15) | |||||
H | 1 200 | 12 | (45, 15, 15) | |||
28 | (46, 16, 15) | |||||
28 | 1 921 | L | 390 | 0 | 3 | (147, 117, 15) |
10 | (148, 118, 15) | |||||
M | 728 | 3 | (73, 45, 14) | |||
23 | (74, 46, 14) | |||||
Q | 1 050 | 4 | (54, 24, 15) | |||
31 | (55, 25, 15) | |||||
H | 1 260 | 11 | (45, 15, 15) | |||
31 | (46, 16, 15) | |||||
29 | 2 051 | L | 420 | 0 | 7 | (146, 116, 15) |
7 | (147, 117, 15) | |||||
M | 784 | 21 | (73, 45, 14) | |||
7 | (74, 46, 14) | |||||
Q | 1 140 | 1 | (53, 23, 15) | |||
37 | (54, 24, 15) | |||||
H | 1 350 | 19 | (45, 15, 15) | |||
26 | (46, 16, 15) | |||||
30 | 2 185 | L | 450 | 0 | 5 | (145, 115, 15) |
10 | (146, 116, 15) | |||||
M | 812 | 19 | (75, 47, 14) | |||
10 | (76, 48, 14) | |||||
Q | 1 200 | 15 | (54, 24, 15) | |||
25 | (55, 25, 15) | |||||
H | 1 440 | 23 | (45, 15, 15) | |||
25 | (46, 16, 15) | |||||
31 | 2 323 | L | 480 | 13 | (145, 115, 15) | |
3 | (146, 116, 15) | |||||
M | 868 | 2 | (74, 46, 14) | |||
29 | (75, 47, 14) | |||||
Q | 1 290 | 42 | (54, 24, 15) | |||
1 | (55, 25, 15) | |||||
H | 1 530 | 23 | (45, 15, 15) | |||
28 | (46, 16, 15) | |||||
32 | 2 465 | L | 510 | 0 | 17 | (145, 115, 15) |
M | 924 | 10 | (74, 46, 14) | |||
23 | (75, 47, 14) | |||||
Q | 1 350 | 10 | (54, 24, 15) | |||
35 | (55, 25, 15) | |||||
H | 1 620 | 19 | (45, 15, 15) | |||
35 | (46, 16, 15) | |||||
33 | 2 611 | L | 540 | 0 | 17 | (145, 115, 15) |
1 | (146, 116, 15) | |||||
M | 980 | 14 | (74, 46, 14) | |||
21 | (75, 47, 14) | |||||
Q | 1 440 | 29 | (54, 24, 15) | |||
19 | (55, 25, 15) | |||||
H | 1 710 | 11 | (45, 15, 15) | |||
46 | (46, 16, 15) | |||||
34 | 2 761 | L | 570 | 0 | 13 | (145, 115, 15) |
6 | (146, 116, 15) | |||||
M | 1 036 | 14 | (74, 46, 14) | |||
23 | (75, 47, 14) | |||||
Q | 1 530 | 44 | (54, 24, 15) | |||
7 | (55, 25, 15) | |||||
H | 1 800 | 59 | (46, 16, 15) | |||
1 | (47, 17, 15) | |||||
35 | 2 876 | L | 570 | 0 | 12 | (151, 121, 15) |
7 | (152, 122, 15) | |||||
M | 1 064 | 12 | (75, 47, 14) | |||
26 | (76, 48, 14) | |||||
Q | 1 590 | 39 | (54, 24, 15) | |||
14 | (55, 25, 15) | |||||
H | 1 890 | 22 | (45, 15, 15) | |||
41 | (46, 16, 15) | |||||
36 | 3 034 | L | 600 | 0 | 6 | (151, 121, 15) |
14 | (152, 122, 15) | |||||
M | 1 120 | 6 | (75, 47, 14) | |||
34 | (76, 48, 14) | |||||
Q | 1 680 | 46 | (54, 24, 15) | |||
10 | (55, 25, 15) | |||||
H | 1 980 | 2 | (45, 15, 15) | |||
64 | (46, 16, 15) | |||||
37 | 3 196 | L | 630 | 0 | 17 | (152, 122, 15) |
4 | (153, 123, 15) | |||||
M | 1 204 | 29 | (74, 46, 14) | |||
14 | (75, 47, 14) | |||||
Q | 1 770 | 49 | (54, 24, 15) | |||
10 | (55, 25, 15) | |||||
H | 2 100 | 24 | (45, 15, 15) | |||
46 | (46, 16, 15) | |||||
38 | 3 362 | L | 660 | 0 | 4 | (152, 122, 15) |
18 | (153, 123, 15) | |||||
M | 1 260 | 13 | (74, 46, 14) | |||
32 | (75, 47, 14) | |||||
Q | 1 860 | 48 | (54, 24, 15) | |||
14 | (55, 25, 15) | |||||
H | 2 220 | 42 | (45, 15, 15) | |||
32 | (46, 16, 15) | |||||
39 | 3 532 | L | 720 | 0 | 20 | (147, 117, 15) |
4 | (148, 118, 15) | |||||
M | 1 316 | 40 | (75, 47, 14) | |||
7 | (76, 48, 14) | |||||
Q | 1 950 | 43 | (54, 24, 15) | |||
22 | (55, 25, 15) | |||||
H | 2 310 | 10 | (45, 15, 15) | |||
67 | (46, 16, 15) | |||||
40 | 3 706 | L | 750 | 0 | 19 | (148, 118, 15) |
6 | (149, 119, 15) | |||||
M | 1 372 | 18 | (75, 47, 14) | |||
31 | (76, 48, 14) | |||||
Q | 2 040 | 34 | (54, 24, 15) | |||
34 | (55, 25, 15) | |||||
H | 2 430 | 20 | (45, 15, 15) | |||
61 | (46, 16, 15) | |||||
Если требуются биты остатка для заполнения оставшихся модулей емкости символа для некоторых версий символа, они все должны быть битами с нулевым значением.
Кодовые слова данных, включая кодовые слова-заполнители, необходимо разделить на несколько блоков по таблице 9. Кодовые слова исправления ошибок вычисляют отдельно для каждого блока и добавляют к кодовым словам данных.
Примечание - Символы Micro QR Code содержат только один блок.
Арифметические операции полиномов для QR Code для вычислений использует побитовый подсчет по модулю 2 и побайтовый подсчет по модулю 100011101. Это поле Галуа 28, где 100011101 соответствует простому минимальному полиному поля x8 + x4 + x3 + x2 + 1.
Кодовые слова данных - коэффициенты членов полинома, начиная с коэффициента при члене со старшей степенью, являющегося первым кодовым словом данных и заканчивая коэффициентом при члене с младшей степенью, являющегося последним кодовым словом данных перед первым кодовым словом исправления ошибок.
Кодовые слова исправления ошибок являются остатком от деления кодовых слов данных на полином g(x), используемый для кодов исправления ошибок (см. приложение A). Коэффициент при члене со старшей степенью полинома-остатка - первое кодовое слово исправления ошибок, а коэффициент при члене с нулевой степенью - последнее кодовое слово исправления ошибок и последнее кодовое слово в блоке.
Примечание - При этом вычислении полином данных символа сначала умножают на xk, а затем выполняют деление многочлена на многочлен.
Для генерации кодовых слов исправления ошибок в символике QR Code используют 36 различных порождающих полиномов, приведенных в приложении A.
Это может быть выполнено с помощью схемы, приведенной на рисунке 14. Регистры от b0 до bk-1 инициализируют нулями. Существуют две стадии генерации кодирования. На первой стадии при положении ключа в нижней позиции кодовые слова данных передаются как на выход, так и на вход схемы. Первая стадия завершается за n синхронизирующих импульсов. На второй стадии (n + 1 ... n + k синхронизирующих импульсов), при положении ключа в верхнем положении кодовые слова исправления ошибок  генерируются путем выдачи значений из всех регистров по порядку с сохранением нулевых данных на входе.
генерируются путем выдачи значений из всех регистров по порядку с сохранением нулевых данных на входе.
генерируются путем выдачи значений из всех регистров по порядку с сохранением нулевых данных на входе.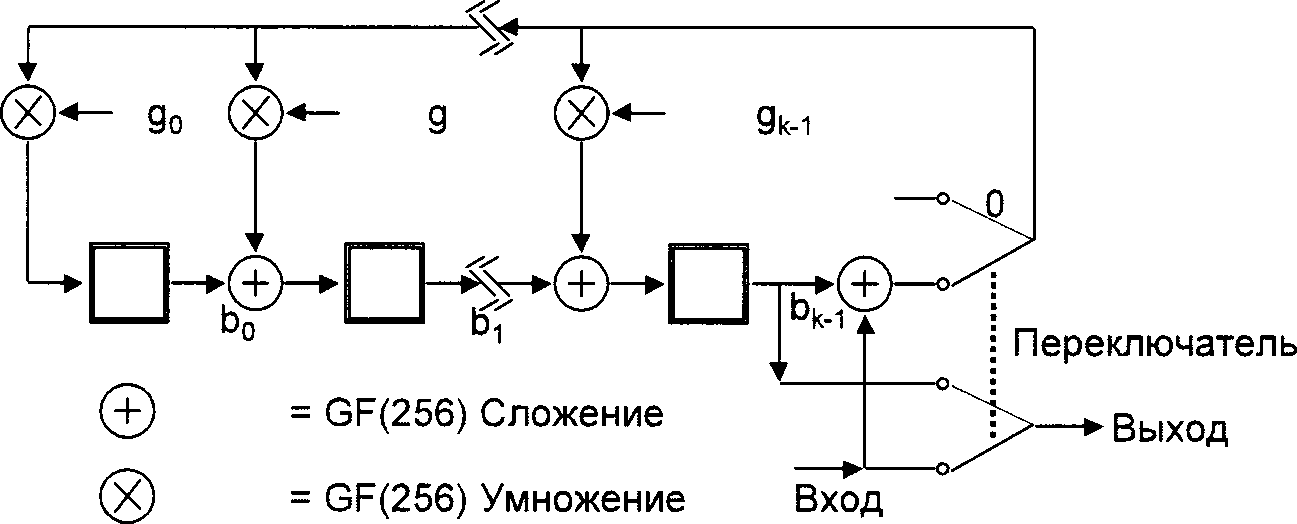
Рисунок 14 - Схема кодирования
кодовых слов исправления ошибок
Общее число кодовых слов в сообщении должно быть равно общему числу кодовых слов, способных к представлению в символе согласно таблицам 7 и 9.
Создание заключительной последовательности кодовых слов (данные плюс кодовые слова исправления ошибок плюс кодовые слова остатка, если необходимо) осуществляют путем выполнения следующих этапов:
1 Разделяют кодовые слова данных на n блоков согласно таблице 9 в соответствии с версией и уровнем исправления ошибок (для Micro QR Code - один блок).
2 Для каждого блока данных, вычисляют соответствующий блок кодовых слов исправления ошибок согласно 7.5.2 и приложению A.
3 Создают заключительную последовательность с помощью кодовых слов данных и исправления ошибок из каждого блока в следующем порядке: блок данных 1, кодовое слово 1; блок данных 2, кодовое слово 1; блок данных 3, кодовое слово 1; ... вплоть до блока данных n - 1, последнее кодовое слово; блок данных n, последнее кодовое слово; затем блок исправления ошибок 1, кодовое слово 1, блок исправления ошибок 2, кодовое слово 1 и т.д. до блока исправления ошибок n - 1, последнее кодовое слово; блок исправления ошибок n, последнее кодовое слово. Символы QR Code состоят из блоков данных и исправления ошибок, которые полностью заполняют емкость символа. Однако в некоторых версиях QR Code, где число модулей области кодирования не делится на 8 без остатка, к завершенному двоичному потоку может быть добавлено 3, 4 или 7 остаточных битов, чтобы полностью заполнить область кодирования символа.
Блоки данных могут иметь разную длину, в этом случае самый короткий блок данных (или блоки) должен быть помещен в начале в последовательности, и все кодовые слова данных должны быть помещены в символ перед первым кодовым словом исправления ошибок. Например, символ версии 5-H включает в себя четыре блока данных и четыре блока исправления ошибок, первые два из которых содержат 11 кодовых слов данных и 22 кодовых слова исправления ошибок соответственно, в то время как третья и четвертая пары блоков содержат 12 кодовых слов данных и 22 кодовых слова исправления ошибок соответственно. На рисунке 15 представлено возможное расположение знаков в этом символе. Каждая строка рисунка соответствует одному блоку кодовых слов данных (Dn), сопровождаемому блоком кодовых слов исправления ошибок (En). Последовательность размещения знаков в символе получают путем выбора столбцов рисунка при просмотре слева направо каждого столбца сверху вниз.

Рисунок 15 - Конструирование последовательности
кодовых слов завершенного сообщения
Таким образом, заключительная последовательность кодовых слов для символа версии 5-H будет следующей: D1, D12, D23, D35, D2, D13, D24, D36, ..., D11, D22, D33, D45, D34, D46, E1, E23, E45, E67, E2, E24, E46, E68, ..., E22, E44, E66, E88. Емкость символа заполняют добавлением семи нулевых остаточных битов после последнего кодового слова.
Существует два типа знаков символа в символе QR Code регулярный и нерегулярный, использование которых зависит от их позиции в символе относительно других знаков символа и функциональных шаблонов.
Большинство кодовых слов должно быть представлено в виде регулярных блоков 2 x 4 модуля в символе. Используют два вида позиционирования этих блоков - в вертикальной ориентации (2 модуля в ширину и 4 модуля в высоту) и, в случае необходимости, когда размещение изменяет направление, в горизонтальной ориентации (4 модуля в ширину и 2 модуля в высоту). Нерегулярные знаки символа используют при изменении направления или при расположении около направляющего шаблона или другого функционального шаблона. Примеры размещения битов приведены на рисунках 16 - 18.
7.7.2 Размещение функциональных шаблонов
Создают пустую квадратную матрицу с числом модулей по горизонтали и вертикали согласно используемой версии. Позиции, соответствующие шаблону поиска, разделителю, шаблону синхронизации и направляющему шаблону должны быть заполнены светлыми или темными модулями соответствующим образом. Позиции модулей для информации о формате и информации о версии временно оставляют пустыми. Пустые позиции приведены на рисунках 19 и 20 и являются общими для всех версий (хотя информация о версии не присутствует в символах версии 1 - 6). Позиционирование направляющих шаблонов приведено в приложении E.
В области кодирования символа QR Code знаки символа позиционируют в колонки шириной два модуля, начинающиеся в нижнем правом углу символа по направлению вверх и вниз справа налево. Принципы, управляющие размещением символов и битов в пределах символов, приведены далее. На рисунках 19 и 20 представлены символы версии 2 и версии 7, применяющие эти принципы.
a) Последовательность размещения битов в столбце должна быть справа налево и снизу вверх или сверху вниз в соответствии с направлением размещения знаков символа.
b) Старший бит (изображенный на рисунках как бит 7) каждого кодового слова должен быть помещен в первую доступную позицию модуля. Последующие биты должны быть размещены в следующих позициях модулей. Поэтому старший бит должен занимать левый нижний модуль регулярного знака при восходящем направлении размещения, и правый верхний модуль при нисходящем направлении размещения. Однако он может быть размещен в правом нижнем модуле нерегулярного знака, если предыдущий знак закончился в правом столбце модулей (см. рисунок 18).
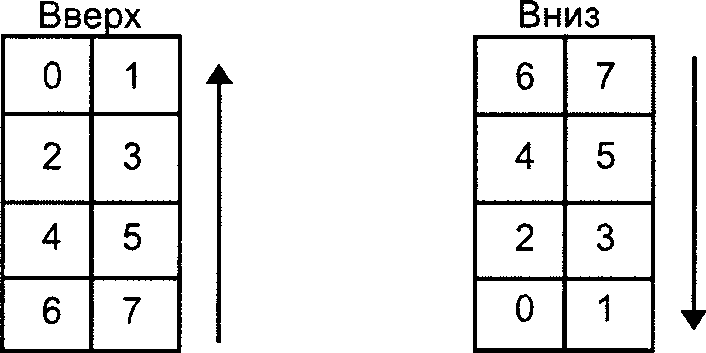
при восходящем и нисходящем направлениях
c) Когда знак символа сталкивается с горизонтальной границей направляющего шаблона или шаблона синхронизации в обоих столбцах модулей, он должен продолжиться выше или ниже шаблона так, как если бы область кодирования была непрерывной.
d) При достижении верхней или нижней границы области кодирования символа (то есть края символа, информации о формате, информации о версии, или разделителя) любые оставшиеся биты в кодовом слове должны быть размещены в следующем столбце налево. Направление размещения изменяется.
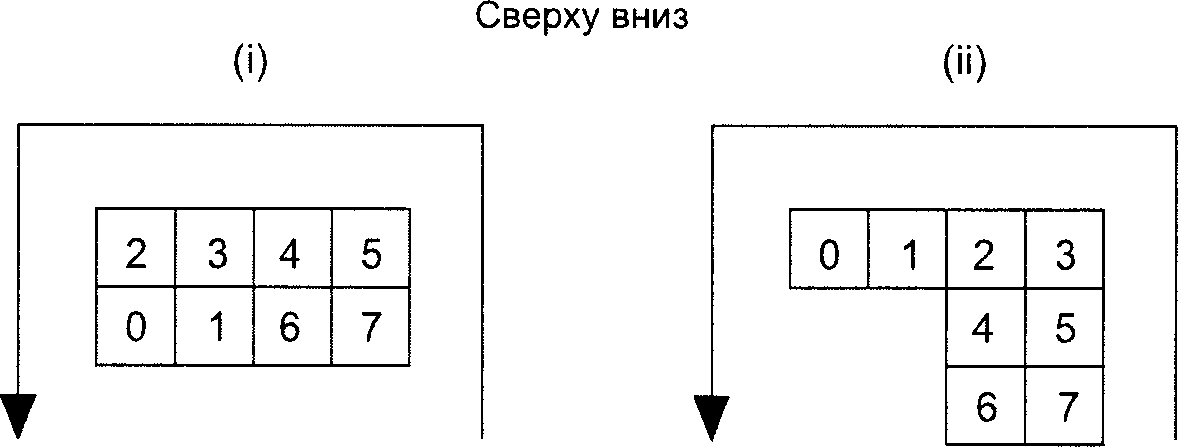
Рисунок 17 - Пример размещения битов в регулярных
(i) и нерегулярных (ii) знаках символа при изменении
направления размещения
e) Когда правый столбец модулей столбца знака символа сталкивается с направляющим шаблоном или областью, занятой информацией о версии, биты должны быть размещены так, чтобы был сформирован нерегулярный знак символа, сдвигая столбец модулей, не пересекающийся с направляющим шаблоном или информацией о версии. Если окончания знаков перед двумя столбцами доступны для следующего знака символа, старший бит следующего знака должен быть помещен в этот же столбец.
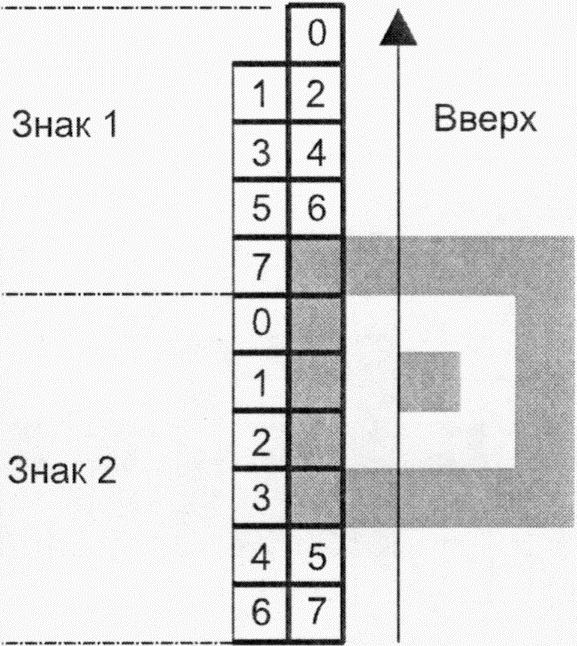
смежных направляющему шаблону
Альтернативный метод размещения битов в символе, который обеспечивает вышеуказанный результат состоит в рассмотрении перемежающейся последовательности кодовых слов как единого двоичного потока, который размещается (начиная со старшего бита) в столбцах шириной два модуля поочередно вверх и вниз и справа налево. В каждом столбце биты размещают поочередно в правых и левых модулях, перемещая вверх или вниз согласно направлению размещения и пропуская области, занятые функциональными шаблонами, изменяя направление вверху или внизу столбца. Каждый бит всегда должен быть размещен в первую доступную позицию для модуля.
Когда емкость данных символа такая, что не делится без остатка на целое число 8-битовых знаков символа, следует использовать соответствующее число остаточных битов (3, 4 или 7 согласно таблице 1), чтобы заполнить емкость символа. Эти остаточные биты должны всегда иметь значение 0 перед маскированием данных согласно 7.8.
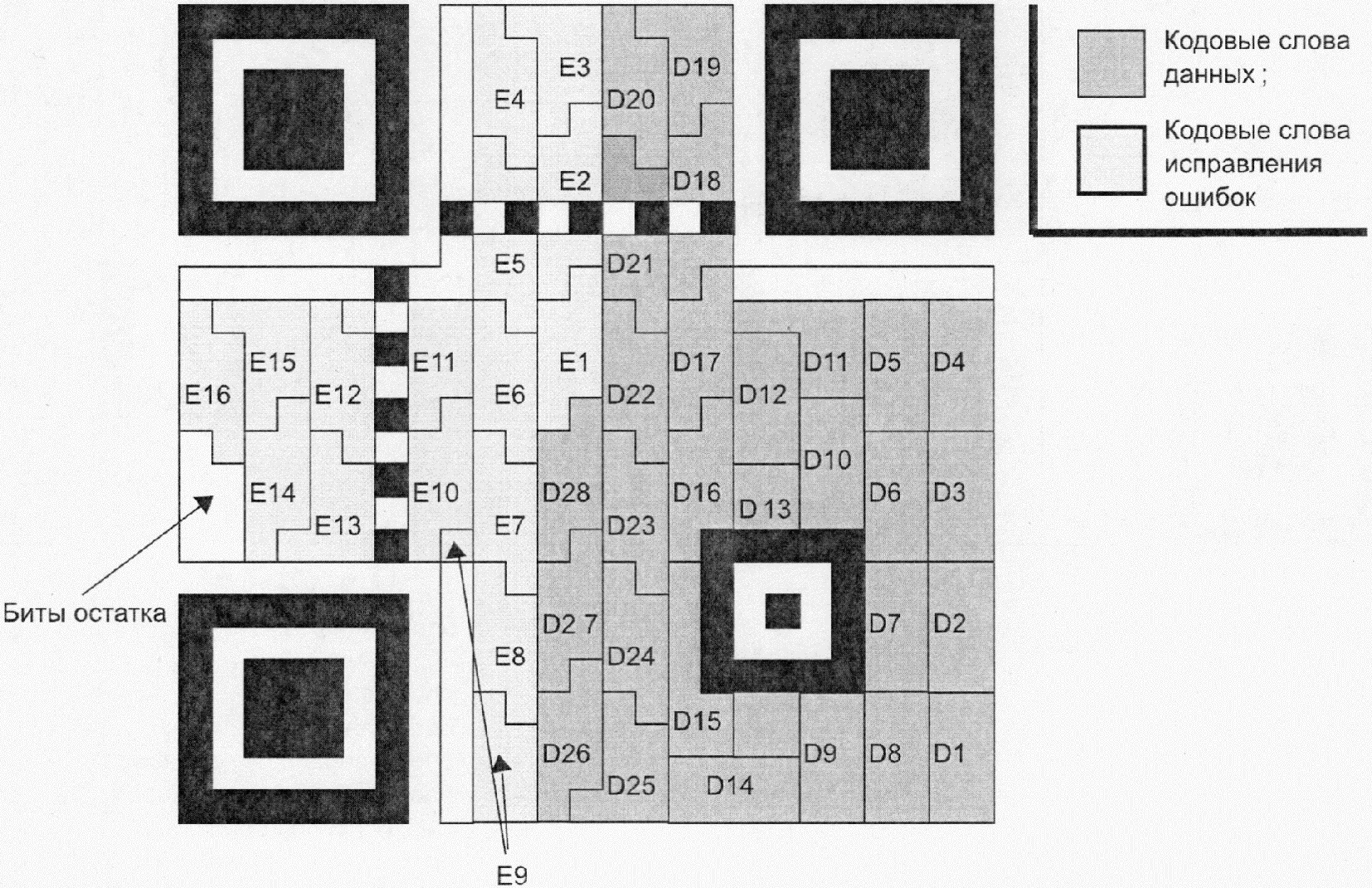
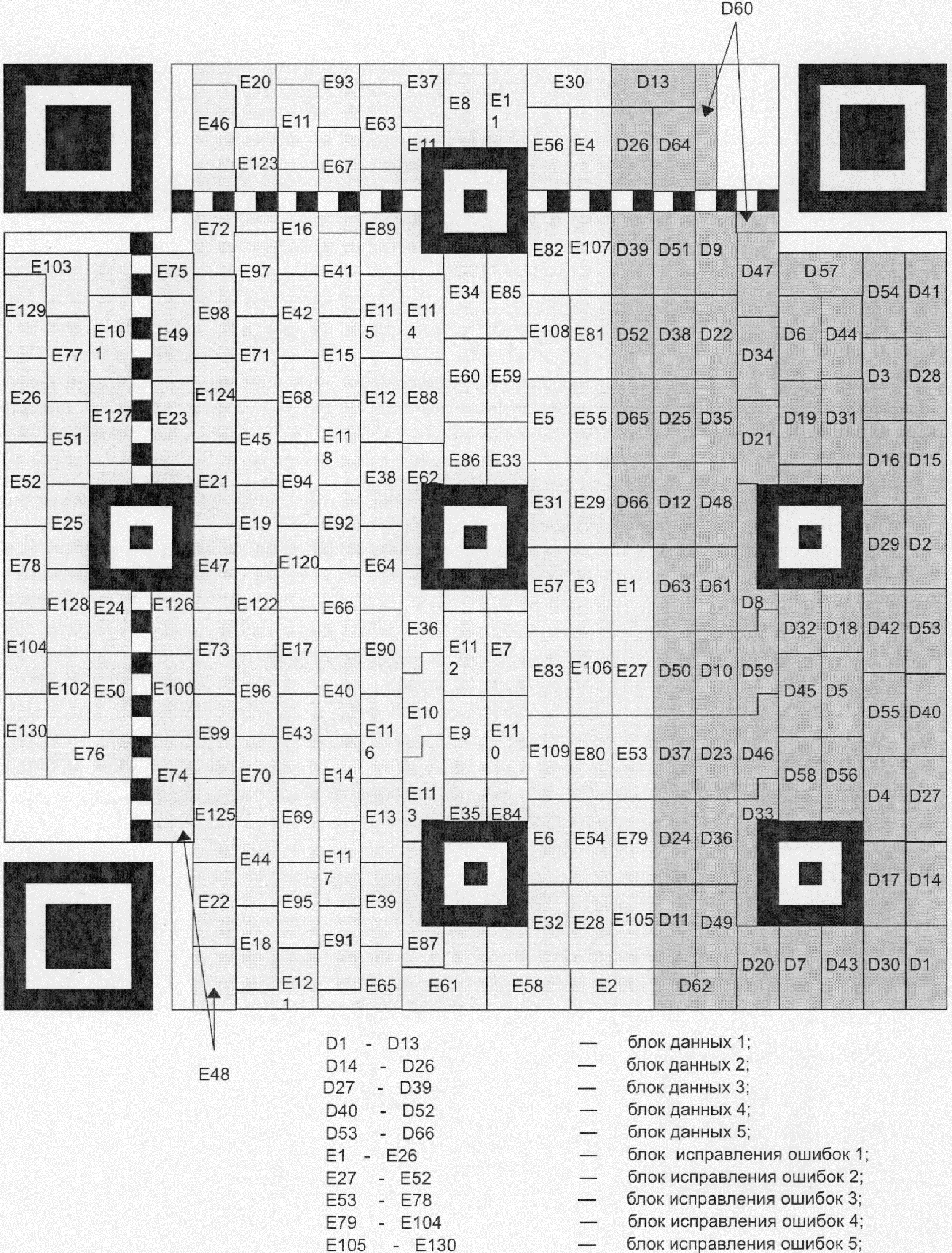
Такие же принципы применяют к символам Micro QR Code, в которых нет нерегулярных знаков, за исключением того, что D3 в символе версии M1, D11 в символе версии M3-L и D9 в символе версии M3-M имеют форму квадратных блоков 2 x 2 из 4 модулей.
7.8.1 Общие положения
Для надежного считывания QR Code предпочтительно, чтобы темные и светлые модули были размещены в символе рациональным способом. Применение битового шаблона 1011101, используемого в шаблонах поиска, нужно избегать в других областях символа в максимально возможной степени. Для выполнения этих условий следует применять маскирование данных с использованием следующих этапов:
1 К функциональным шаблонам не применяют маскирование данных.
2 Преобразуют данную комбинацию модулей в области кодирования (исключая информацию о формате и информацию о версии) с многократными матричными шаблонами последовательно через операцию XOR. Для операции XOR совмещают модули такого шаблона с соответствующими модулями шаблона маски и полностью изменяют модули данных (со светлого на темный или наоборот), которые соответствуют темным модулям шаблона маски.
3 Обрабатывают результаты применения всех шаблонов маски, назначая штрафные очки за нежелательные особенности на каждом результате преобразования.
4 Выбирают шаблон с наименьшим числом штрафных очков.
В таблице 10 приведены указатели шаблона маски данных (двоичный код для использования в информации о формате) и условия генерации шаблона маски данных. Шаблон маски данных формируют путем определения любого модуля в области кодирования (исключая область, сохраненную для информации о формате и информации о версии) как темного, для которого условие является истинным; при условии, что i относится к позиции строки рассматриваемого модуля j к позиции его столбца, причем (i, j) = (0, 0) для верхнего левого модуля символа.
Таблица 10
Указатель шаблона маски данных для символов QR Code | Указатель шаблона маски данных для символов Micro QR Code | Условие |
000 | (i + j) mod 2 = 0 | |
001 | 00 | i mod 2 = 0 |
010 | j mod 3 = 0 | |
011 | (i + j) mod 3 = 0 | |
100 | 01 | ((i div 2) + (j div 3)) mod 2 = 0 |
101 | (ij) mod 2 + (ij) mod 3 = 0 | |
110 | 10 | ((ij) mod 2 + (ij) mod 3) mod 2 = 0 |
111 | 11 | ((i + j) mod 2 + (ij) mod 3) mod 2 = 0 |
На рисунке 21 приведены все шаблоны маски для символа версии 1. На рисунке 23 показан эффект от применения шаблонов 000 - 111.

Примечание 1 - Три бита под каждым шаблоном являются указателем шаблона маски данных.
Примечание 2 - Уравнение, приведенное ниже указателя шаблона маски данных, показывает условия генерации шаблона маски данных; модули, на которых выполняется условие, изображены темным цветом.
На рисунке 22 ниже приведены четыре допустимых шаблона маски данных, применяемых к символам Micro QR Code версии M-4.

к символам Micro QR Code версии M4
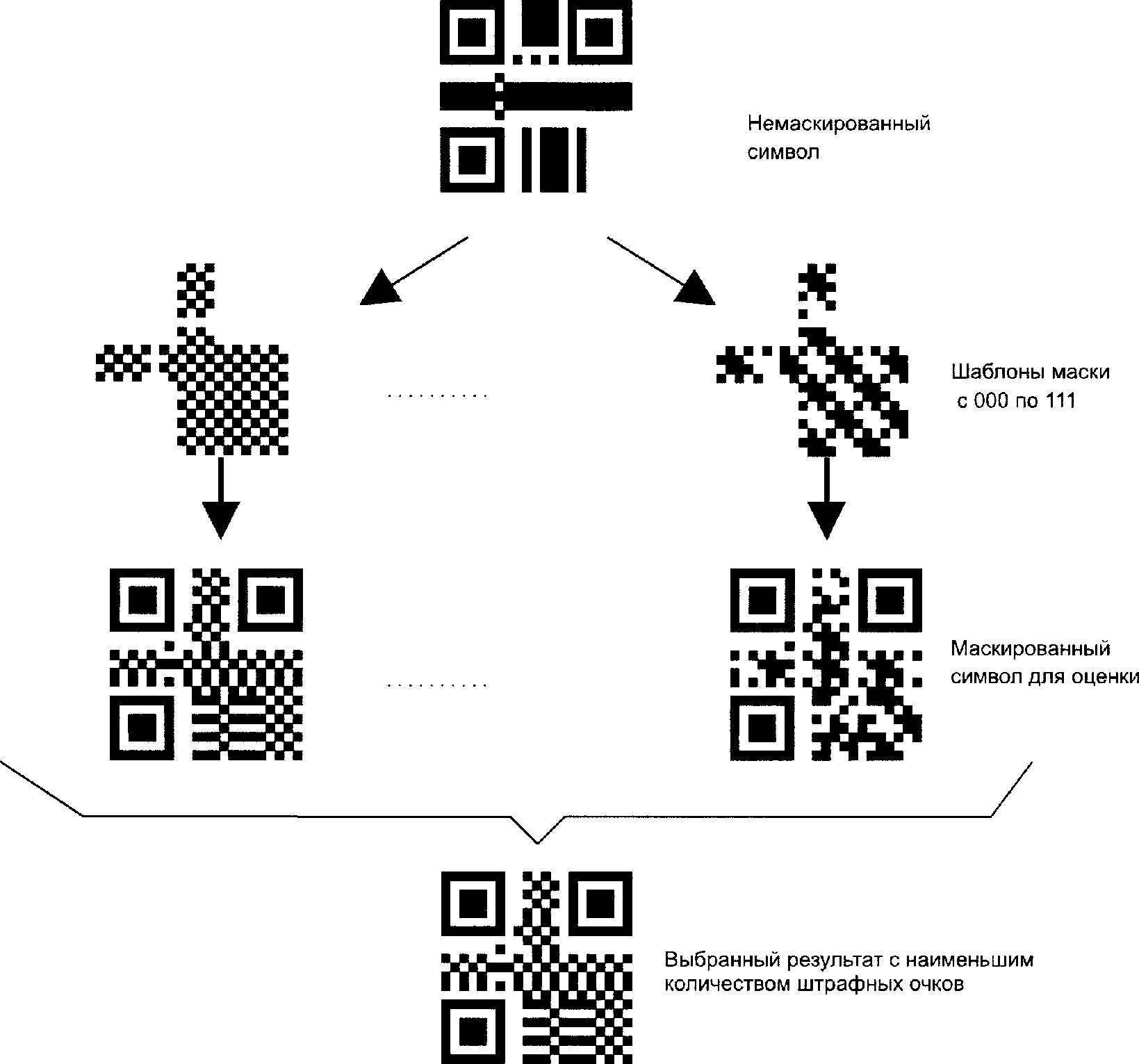
7.8.3.1 Оценка символов QR Code
После выполнения операции маскирования данных для каждого шаблона маски данных должны быть оценены результаты путем подсчета штрафных очков для каждого возникновения следующих особенностей. Чем выше число штрафных очков, тем менее приемлемым является результат. В таблице 11 переменные N1 - N4 представляют взвешенное количество штрафных очков для нежелательных особенностей (N1 = 3, N2 = 3, N3 = 40, N4 = 10), i - количество, на которое число смежных модулей одного цвета превышает 5, и k - оценка отклонения пропорции темных модулей в символе от 50% с шагом 5%. Хотя операцию маскирования данных применяют только в области кодирования символа, исключая информацию о формате, областью, которая оценивается, является весь законченный символ.
Таблица 11
Подсчет результатов применения маскирования данных
Особенность | Оценка особенности | Штрафные очки |
Длинная колонка или строка модулей одного цвета | Число модулей = (5 + i) | N1 + i |
Блоки модулей одного цвета | Размер блока = 2 x 2 | N2 |
Шаблон с соотношением 1:1:3:1:1 (темный:светлый:темный:светлый:темный) в строке или столбце, предшествующий или последующий светлой области 4 модуля шириной | Наличие такого шаблона | N3 |
Процент темных модулей в символе | От 50 x (5 x k)% до 50 x (5 x (k + 1))% | N4 x k |
Примечание 1 - Прилегающие модули одного цвета в строке/столбце Для оценки результатов маскирования данных проверяют блоки, состоящие из 5 и более светлых (белых) и темных (черных) модулей, расположенных в ряду подряд сбоку и вертикально. Подсчет штрафных очков осуществляют следующим образом: каждому блоку из 5 последовательных модулей назначается 3 штрафных очка, из 6 последовательных модулей - 4 штрафных очка и т.д., добавляя одно штрафное очко при увеличении блока на 1 модуль. Например, блоку "темный:темный:темный:темный:темный:темный:темный" назначают 5 штрафных очков, при этом серию из 7 последовательных модулей считают одним блоком. Однако очки не удваивают. Например, блоку из 7 модулей присваивают 5 штрафных очков, а не 12 (складывающихся из 3 штрафных очков за блок из 5 модулей плюс 4 штрафных очка за блок из 6 модулей плюс 5 штрафных очков за блок из 7 модулей). Примечание 2 - Модули одного цвета в блоке Штрафное очко должно быть равно числу блоков, состоящих из темных или светлых модулей размерами (в модулях) 2 x 2. Например, для блока, состоящего из темных модулей, с размерами (в модулях) 3 x 3, количество штрафных очков рассчитывают как 4 (блока) x 3 (очка) = 12 (с учетом того, что в такой блок может быть включено до четырех модулей размерами 2 x 2). Примечание 3 - Шаблон с соотношением 1:1:3:1:1 в строке или столбце Если после или до шаблона с соотношением 1:1:3:1:1 расположена светлая область шириной более 4 модулей, то должно быть назначено 40 штрафных очков. Примечание 4 - Доля темных модулей в символе Назначают 10 штрафных очков при увеличении или уменьшении более чем на 5% доли темных модулей от рекомендуемого уровня 50% (за который назначают 0 штрафных очков). Например, назначают 0 штрафных очков, если доля темных модулей находится в пределах от 45% до 55% и 10 штрафных очков, если доля темных модулей находится в пределах от 40% до 60%. | ||
Выбирают шаблон маски данных, имеющий наименьшее число штрафных очков.
7.8.3.2 Оценка символов Micro QR Code
После выполнения операции маскирования данных в области кодирования символа с каждым шаблоном маски данных оценивают результат, подсчитывая множество темных модулей в каждой из двух границ, которые не содержат шаблоны синхронизации. Чем меньше число темных модулей, тем менее приемлемым является результат. В таких символах рекомендуется иметь больше темных модулей на границе, чтобы более эффективно отличать свободную зону от области кодирования.
Для каждого шаблона маски данных подсчитывают число темных модулей в правой и нижней границах символа (исключая последний модуль шаблона синхронизации). Оценку результата подсчета производят следующим образом:
если SUM1 <= SUM2,
то оценка = SUM1 x 16 + SUM2;
если SUM1 > SUM2,
то оценка = SUM2 x 16 + SUM1,
где SUM1 - число темных модулей на правой границе;
SUM2 - число темных модулей на левой границе.
маскирования для Micro QR Code
Выбирают шаблон маски, имеющий наибольший результат.
Информация о формате представляет собой последовательность из 15 битов, содержащую 5 битов данных и 10 битов исправления ошибок, вычисляемых по коду BCH (15, 5). Подробные сведения о вычислении битов исправления ошибок для информации о формате приведены в приложении C. Первые два бита данных содержат уровень исправления ошибок символа, обозначенный соответствующим образом (таблица 12).
Таблица 12
Индикаторы уровня исправления ошибок для символов QR
Уровень исправления ошибок | Двоичный индикатор |
L | 01 |
M | 00 |
Q | 11 |
H | 10 |
Биты с третьего по пятый содержат указатель шаблона маски данных (см. таблицу 10) для шаблона, выбранного в соответствии с 7.8.3.
Десять битов исправления ошибок вычисляют согласно положениям приложения C и добавляют к окончанию пяти битов данных.
Затем к 15 битам информации о формате применяют операцию XOR с маской 101010000010010, чтобы гарантировать, что никакая комбинация уровня исправления ошибок и указателя шаблона маски данных не имеет в результате 15 нулевых битов.
В результате информация о формате должна быть размещена в области, зарезервированной для этого в символе в соответствии с рисунком 25. Следует обратить внимание, что информация о формате появляется в символе дважды, обеспечивая избыточность, так как ее правильное декодирование необходимо для декодирования завершенного символа. Младший бит информации о формате расположен в модуле с номером 0, а старший бит в модуле с номером 14 (рисунок 25). Модуль в позиции (4V + 9, 8), где V - номер версии, должен всегда быть темным и не является частью информации о формате.
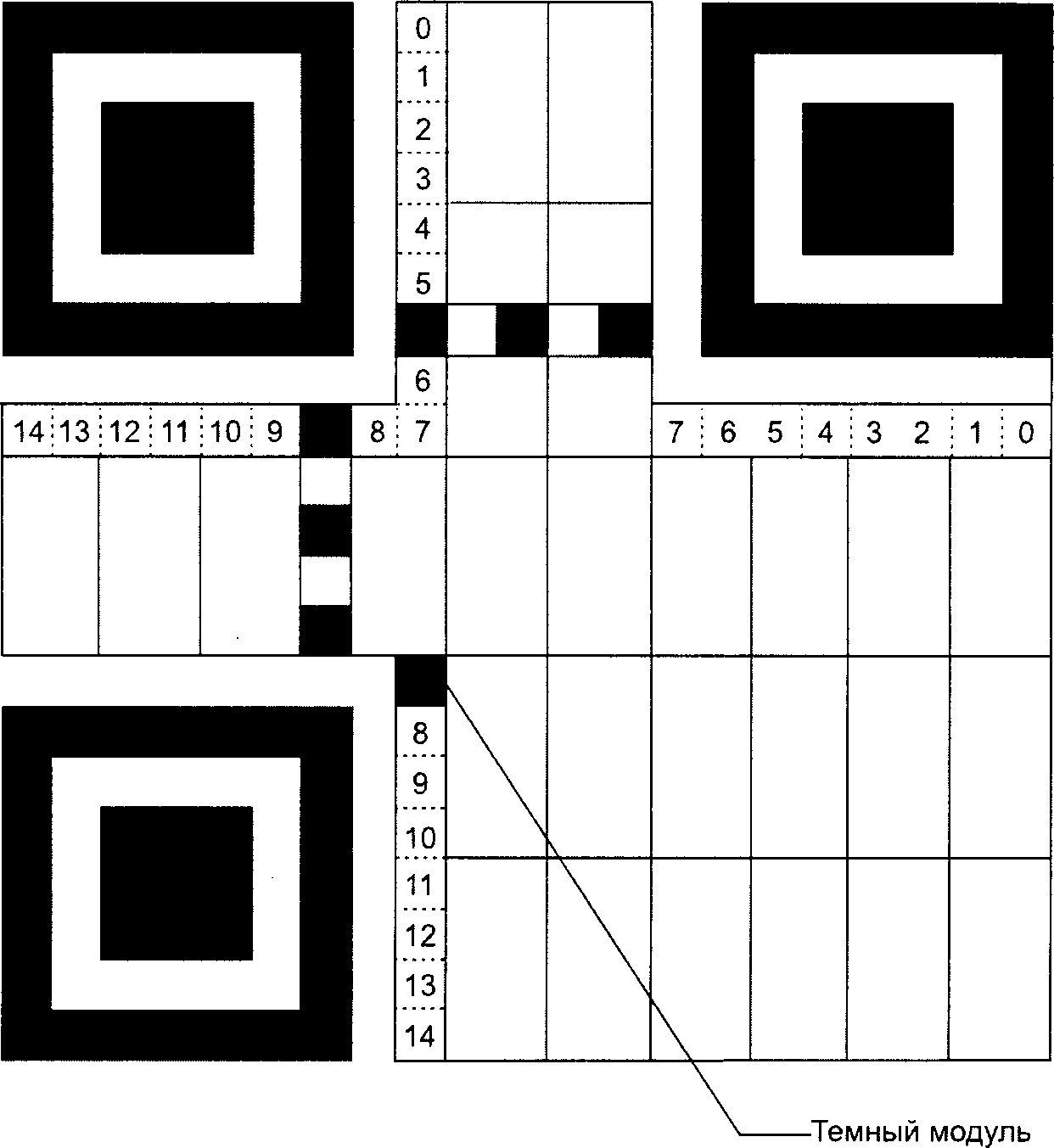
Пример
Уровень исправления ошибок M: 00
Указатель шаблона маски: 101
Данные: 00101
Биты кода BCH: 0011011100
До применения маски: 001010011011100
После операции XOR: 101010000010010
Биты шаблона информации о формате: 100000011001110
│ │
бит 14 бит 0
Информация о формате представляет собой 15-битовую последовательность, содержащую 5 битов данных, и 10 битов исправления ошибок, вычисляемых с использованием кода BCH (15, 5). Подробности вычисления битов исправления ошибок для информации о формате приведены в приложении C. Первые три бита данных содержат номер символа (в двоичном виде), который идентифицирует версию и уровень исправления ошибок согласно таблице 13.
Таблица 13
Номер символа для Micro QR Code
Номер символа | Версия | Уровень исправления ошибок | Двоичный индикатор |
0 | M1 | Только обнаружение | 000 |
1 | M2 | L | 001 |
2 | M2 | M | 010 |
3 | M3 | L | 011 |
4 | M3 | M | 100 |
5 | M4 | L | 101 |
6 | M4 | M | 110 |
7 | M4 | Q | 111 |
Четвертый и пятый биты информации о формате содержат указатель шаблона маски данных, указанный в таблице 10 для шаблона, определенного по 7.8.3.
Десять битов исправления ошибок вычисляют в соответствии с положениями приложения C и добавляют к пяти битам данных.
Затем к 15 битам информации о формате применяют операцию XOR с маской 100010001000101, чтобы гарантировать, что никакая комбинация номера символа и указателя шаблона маски данных не имеет в результате 15 нулевых битов.
В результате информация о формате должна быть размещена в области, сохраненной для этого в символе в соответствии с рисунками 25 и 26, в зависимости от типа символа. Младший бит информации о формате расположен в модуле с номером 0, а старший бит в модуле с номером 14 на рисунках 24 и 25.
Пример
Номер символа 0: 000
Указатель шаблона маски данных: 11
Биты данных (номер символа, указатель
шаблона маски данных): 00011
Биты кода BCH: 1101011001
Битовая последовательность без маски: 000111101011001
После операции XOR: 100010001000101
Шаблон информации о формате: 100101100011100
│ │
бит 14 бит 0

о формате в символе Micro QR Code
Информацию о версии включают в символ QR Code версии 7 или выше. Это 18-битовая последовательность, содержащая 6 битов данных и 12 битов исправления ошибок, вычисляемых с использованием кода BCH (18, 6). Подробные сведения о вычислении проверочных битов информации о версии приведены в приложении D. Шесть битов данных содержат версию символа, старший бит - первый.
12 проверочных битов исправления ошибок вычисляют по алгоритму, приведенному в приложении D, и добавляются к 6 битам данных.
Информация о версии в результате не может содержать только нулевые биты, поэтому только символы версий 7 - 40 содержат информацию о версии. К информации о версии не применяют процедуру маскирования данных.
В результате информация о версии должна быть отображена в области, отведенной для этого в символе согласно рисунку 27. Следует обратить внимание, что информация о версии появляется в символе дважды, чтобы обеспечить избыточность, так как без надлежащего декодирования указанной информации невозможно декодирование всего символа. Младший бит информации о версии расположен в модуле с номером 0, а старший бит в модуле номер 17 (рисунок 28).
Пример
Номер версии: 7
Данные: 000111
BCH биты: 110010010100
Модули шаблона информации о версии: 000111110010010100
Информация о версии занимает блок модулей 6 x 3 над верхним шаблоном синхронизации и непосредственно рядом слева от левого разделителя правого верхнего шаблона поиска и блок модулей 3 x 6 слева от левого шаблона синхронизации и непосредственно над верхним разделителем левого нижнего шаблона поиска.
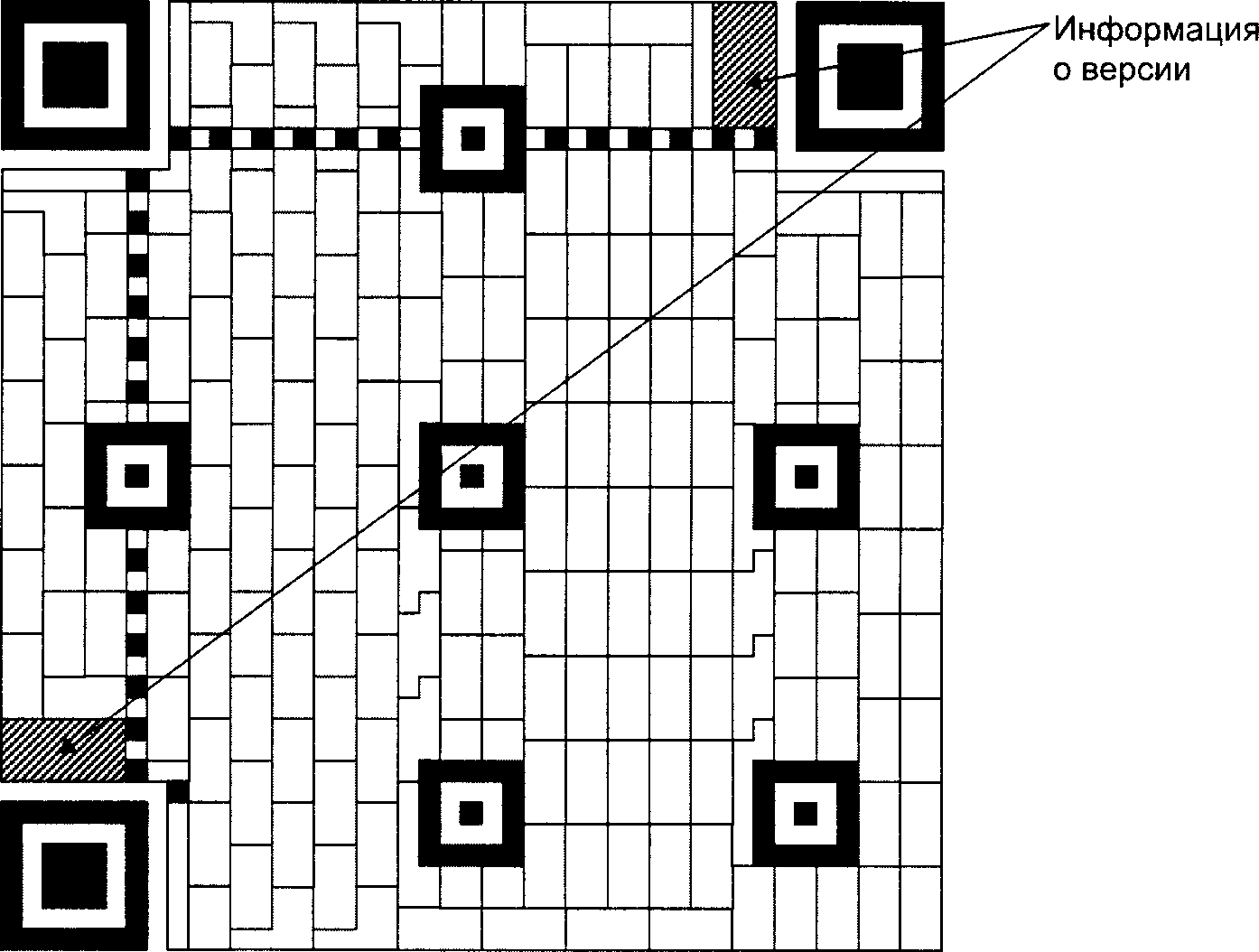
Структурированное соединение не допускается в символах Micro QR Code.
В структурированный формат может быть объединено до 16 символов QR Code. Если символ является частью сообщения со структурированным соединением, то это должно быть указано в заголовке в первых трех позициях знаков символа.
Индикатор режима структурированного соединения имеет битовое значение 0011 и занимает первые четыре значащих бита в первом знаке символа.
Сразу за ним должны быть расположены два кодовых слова структурированного соединения, занимающие младшие биты первого знака символа, весь второй знак и старшие четыре бита третьего знака. Первое кодовое слово является индикатором очередности символа (см. 7.2). Второе кодовое слово является контрольными данными (см. 7.3) и должно быть одинаковым для всех символов структурированного соединения в пределах одного сообщения, допускающим возможность верификации того, чтобы все символы показывали принадлежность части к одному и тому же структурированному соединению. Сразу после заголовка должны следовать кодовые слова данных, начиная с индикатора режима. Если в сообщении используют одну или более интерпретаций ECI, отличающихся от ECI по умолчанию, заголовки режима ECI должны быть расположены сразу за заголовком структурного соединения.
На рисунке 29 приведены четыре символа структурированного соединения, содержащих то же самое сообщение, что и большой символ в верхней части рисунка.

Рисунок 29 - Один символ (сверху) и серия символов
структурированного соединения (снизу) кодирующие "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"
Данное кодовое слово указывает позицию символа в последовательности (до 16) символов QR Code в формате структурированного соединения (в форме m из n символов). Первые 4 бита этого кодового слова идентифицируют позицию конкретного символа. Последние 4 бита указывают общее число символов, которые будут связаны в формате структурированного соединения. 4 битовых значения должны быть двоичными эквивалентами (m - 1) и (n - 1) соответственно.
Пример
Указание третьего символа в наборе из семи символов кодируют следующим образом:
3-я позиция: 0010
Общее число из 7 символов: 0110
Комбинация битов: 00100110
Контрольными данными является 8-битовый байт, расположенный сразу после индикатора очередности символа. Контрольные данные - значение, полученные с помощью последовательного применения операции XOR к значениям байтов всех первоначальных входных данных перед разделением на блоки знаков для символов. Индикаторы режима, индикаторы числа знаков, биты-заполнители, ограничитель и знаки-заполнители не включают в вычисления. Входные данные представлены для этого вычисления двухбайтовыми значениями JIS Shift для знаков кандзи (каждый байт, обрабатывают отдельно с применением XOR вычислений, при этом самый старший бит обрабатывают первым) и 8-битовыми значениями согласно таблице 6 для других знаков. В режиме ECI значения байтов, полученные после любого шифрования или уплотнения данных, следует использовать при вычислениях.
Пример
Входную строку " " разбивают на "0123", "4567" и "
" разбивают на "0123", "4567" и " " следующим образом:
" следующим образом:
" разбивают на "0123", "4567" и "блок знаков первого символа ("0123") - шестнадцатеричные значения 30, 31, 32, 33;
блок знаков второго символа ("4567") - шестнадцатеричные значения 34, 35, 36, 37;
блок знаков третьего символа (" ") - шестнадцатеричные значения 38, 39, 93FA, 967B.
") - шестнадцатеричные значения 38, 39, 93FA, 967B.
Контрольные данные из входной строки " " вычисляют с помощью операции XOR последовательно байт за байтом.
" вычисляют с помощью операции XOR последовательно байт за байтом.
" вычисляют с помощью операции XOR последовательно байт за байтом.
Следует обратить внимание, что вычисление контрольных данных может быть выполнено или перед передачей данных на принтер или в самом принтере, если он обеспечивает такую возможность.
Символы QR Code должны иметь следующие размеры:
- размер X: ширина модуля должна быть установлена в применении с учетом технологии сканирования символа и технологии производства символа;
- размер Y: высота модуля должна быть равна X;
- минимальный размер свободной зоны равен 2X (для символов Micro QR Code) или 4X (для символов QR Code) для всех четырех сторон.
Поскольку символы QR Code способны к кодированию тысяч знаков, интерпретация для визуального чтения данных в виде расположенного рядом обычного текста может оказаться нерациональной. Как альтернатива, символ может сопровождать краткий описательный текст, а не весь закодированный текст сообщения.
Настоящий стандарт не определяет размер и тип шрифта знаков, поэтому описание может быть напечатано в любом месте вблизи символа. Интерпретация для визуального чтения не должна накладываться непосредственно на символ и на его свободные зоны.
Символы QR Code могут быть напечатаны или нанесены с использованием нескольких различных технологий. Рекомендации для пользователя приведены в приложении K.
Оценку качества печати символов QR Code следует проводить с использованием рекомендаций по оценке качества двумерных матричных символов штрихового кода, приведенных в ИСО/МЭК 15415 с учетом изменений, указанных далее.
Некоторые технологии маркирования не могут обеспечить нанесение символов, соответствующих требованиям настоящего стандарта без применения специальных мер. В приложении M приведены дополнительные рекомендации с целью помочь любой системе печати обеспечивать нанесение надлежащих символов QR Code.
Символы, полученные методом прямого маркирования изделий, и/или символы, нанесенные несоединяющимися точками, могут не соответствовать требованиям данной методики и могут быть не считаны сканерами, предназначенными для символов QR Code. Требования по применению таких символов должны устанавливать методы измерения качества, использующие ИСО/МЭК 15415 с учетом дополнительных рекомендаций по качеству согласно ИСО/МЭК ТО 29158, и могут регламентировать необходимость использования специальных сканеров для считывания символов, полученных прямым маркированием.
10.2.1 Повреждение фиксированного шаблона
Методика измерения и оценки повреждения фиксированного шаблона приведена в приложении G.
10.2.2 Класс сканирования и полный класс символа
Класс сканирования должен соответствовать самому низкому из классов контраста символа, модуляции, повреждения фиксированного шаблона, декодирования, осевой неоднородности, неоднородности сетки и неиспользованного исправления ошибок в индивидуальном изображении символа. Полный класс символа - среднее арифметическое отдельных классов сканирования для множества проверенных изображений этого символа.
10.2.3 Осевая неоднородность
Идеальную сетку рассчитывают с использованием шаблонов поиска и направляющих шаблонов в качестве базовых точек, определенных с использованием рекомендуемого алгоритма декодирования (см. раздел 12).
10.3. Методы контрольных измерений
Для мониторинга и контроля при изготовлении символов QR Code используют различные методы и инструментальные средства, приведенные в приложении M. Эти методы не обеспечивают проведение полной проверки качества печати наносимых символов (необходимый метод для оценки качества печати символа указан ранее в настоящем разделе, а также в приложении G), но отдельно и вместе предоставляют полезные сведения о создании в процессе печати пригодных для работы символов.
Этапы декодирования, начиная со считывания символа QR Code и заканчивая формированием выходной строки знаков, являются обратными по отношению к процедуре кодирования. На рисунке 30 приведена схема этого процесса.
1. Определяют место нахождения и получают изображение символа. Темные и светлые модули представляют как массив битов "0" и "1". Определяют полярность коэффициентов отражения по модулям шаблона поиска.
2. Считывают информацию о формате. Реализуют шаблон маски и проводят процедуру исправления ошибок на модулях информации о формате, если необходимо; в случае успеха символ имеет обычную ориентацию, в противном случае предпринимают попытку декодирования информации о формате для изображения в зеркальном отображении. Определяют уровень исправления ошибок в символах QR Code - непосредственно, а в символах Micro QR Code - на основе номера символа и указателя шаблона маски.
3. Считывают информацию о версии (где это применимо), и определяют версию символа (в случае Micro QR Code - из номера символа).
4. Из информации о формате получают указатель шаблона маски и реализуют процедуру маскирования данных, применяя операцию XOR к битам области данных с битами шаблона маски.
5. Считывают знаки символа согласно правилам размещения для модели и восстанавливают кодовые слова данных и исправления ошибок в сообщении.
6. Определяют число кодовых слов исправления ошибок на основании уровня исправления ошибок и находят ошибочные кодовые слова, используя кодовые слова исправления ошибок. Если ошибки были обнаружены, исправляют их.
7. Разделяют кодовые слова данных на сегменты в соответствии с индикаторами режимов и индикаторами числа знаков.
8. В заключении декодируют знаки данных в соответствии с используемым(мыми) режимом(ами) и выводят результат.
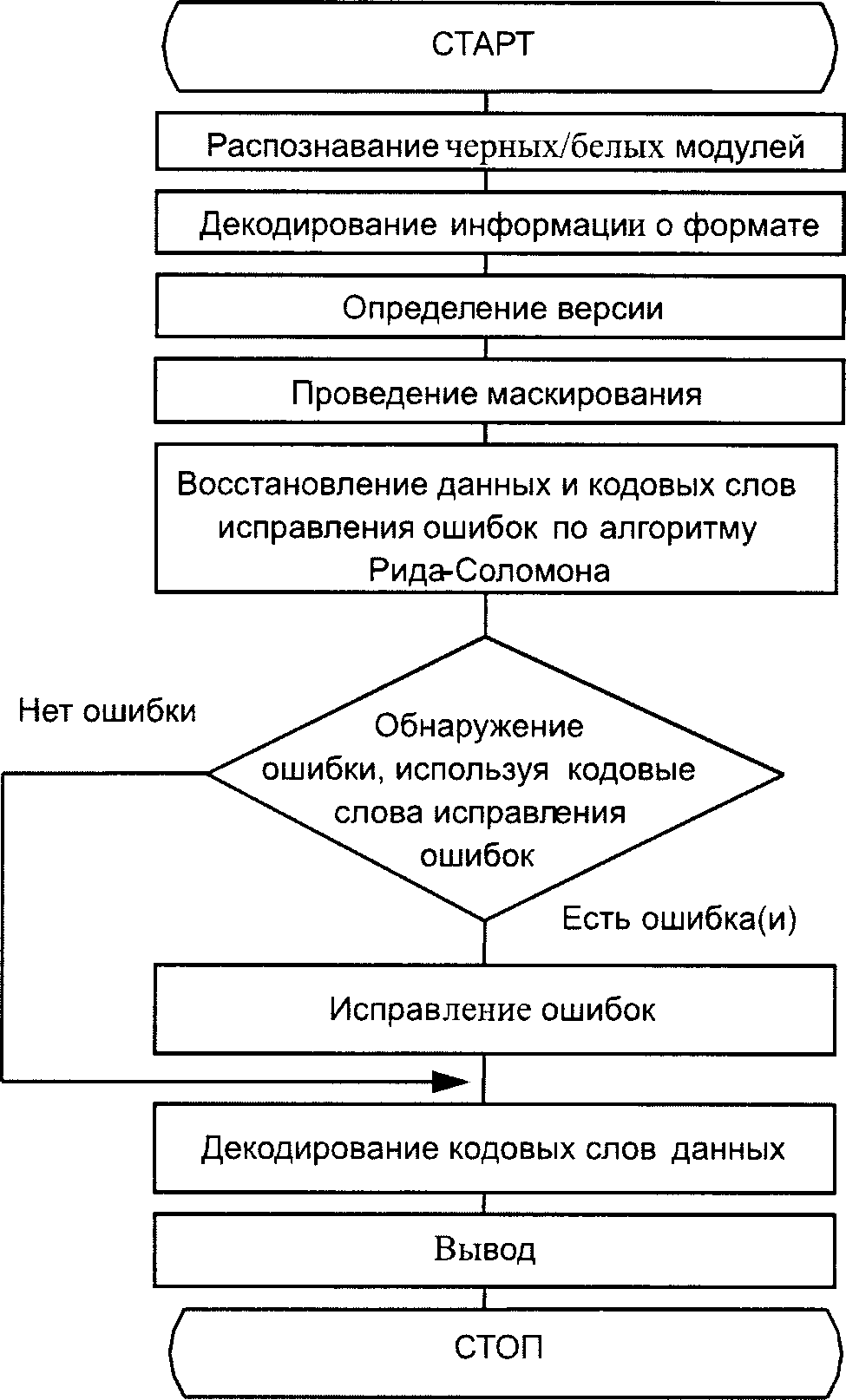
С помощью данного рекомендуемого алгоритма декодирования находят на изображении символы QR Code и декодируют их.
Алгоритм распознавания, относящийся к определению темных и светлых точек в изображении:
a) Определяют глобальный порог, используя полученные значения коэффициента отражения, как среднее между минимальным и максимальным коэффициентом отражения в изображении; преобразуют изображение в массив темных и светлых пикселей на основе глобального порога.
b) Определяют место нахождения шаблона поиска. Шаблон поиска для символов QR Code состоит из трех одинаковых шаблонов, расположенных в трех из четырех углов символа. Шаблон поиска для символов Micro QR Code состоит из единственного шаблона. Согласно 6.3.3 модули в каждом шаблоне поиска формируют последовательность темный-светлый-темный-светлый-темный, относительная значения ширины каждого элемента которой находятся в соотношении 1:1:3:1:1. Для целей данного алгоритма допускается отклонение каждого значения ширине до 0,5 (то есть в диапазоне от 0,5 до 1,5 модулей для области шириной в 1 модуль и от 2,5 до 3,5 модулей для квадратной области шириной 3 модуля).
1) При обнаружении области-кандидата, отмечают позиции первой и последней точки (A и B соответственно) на линии из пикселей, которая пересекается с внешними границами шаблона поиска на изображении (см. рисунок 31). Повторяют вышеуказанное для смежных линий пикселей в изображении до тех пор, пока не будут идентифицированы все линии, пересекающие центральный блок шаблона поиска по оси X изображения.

Рисунок 31 - Линия сканирования в шаблоне поиска
2) Повторяют этап 1) для столбцов пикселей, пересекающих центральный блок найденного шаблона поиска по оси Y.
3) Определяют место нахождения центр шаблона. Проводят линию через точки, находящиеся посередине между точками A и B для линий, пересекающих центральный блок шаблона поиска вдоль оси X, построенных на этапе 1). Проводят линию через точки, находящиеся посередине между точками A и B для линий, пересекающих центральный блок шаблона поиска вдоль оси Y, построенных на этапе 2). Центр шаблона поиска должен находиться в точке пересечения этих двух линий.
4) Повторяют этапы 1) - 3) для нахождения центров двух оставшихся шаблонов поиска.
5) Если не было найдено ни одной области-кандидата на шаблон поиска, изменяют пиксели на инвертированные светлые и темные пиксели и повторяют, начиная с этапа b), попытки декодировать символ как символ с инвертированными значениями коэффициентов отражения.
6) Если найден только один шаблон поиска (а места нахождения двух других не обнаружены), символ декодируют как Micro QR Code, перейдя к рекомендуемому алгоритму декодирования Micro QR Code (с этапа m).
c) Определяют угловую ориентацию символа, анализируя координаты центров найденных шаблонов поиска для уточнения, какой из шаблонов находится в левом верхнем углу символа, и таким образом находят угол поворота символа.
d) Определяют: 1) расстояние D на линии, пересекающей символ и проходящей через центры левого верхнего и правого верхнего шаблонов, и 2) ширину двух этих шаблонов WUL и WUR согласно рисунку 32.
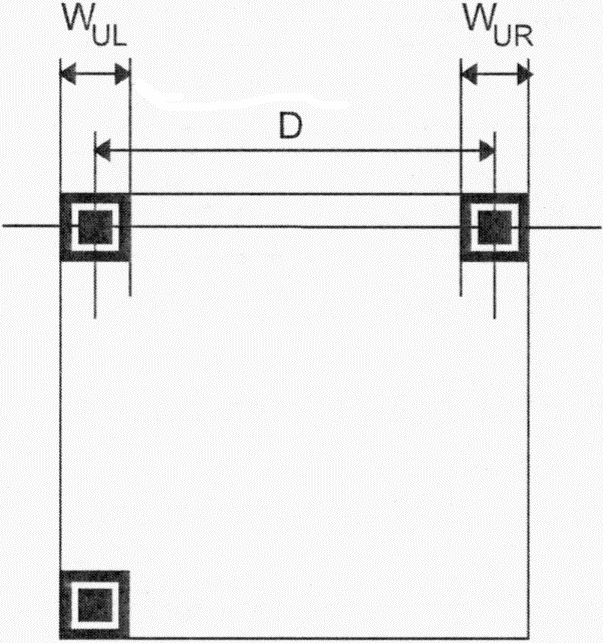
Рисунок 32 - Верхние шаблоны поиска
e) Вычисляют номинальный размер X для символа X = (WUL + WUR)/14.
f) Вычисляют приблизительную версию символа VV = [(D/X) - 10]/4.
g) Если приблизительная версия символа 6 или менее, ее принимают в качестве окончательной версии. Если приблизительная версия 7 или более, декодируют информацию о версии следующим образом.
1) Делят ширину верхнего левого шаблона WUR на 7, чтобы вычислить ширину одного модуля CPUR: CPUR = WUR/7.
2) Находят направляющие линии AC и AB, проходящие через центры трех шаблонов поиска A, B и C согласно рисунку 33. Сетку выборки центров модулей блока 1 информации о версии определяют на основе линий, параллельных направляющим линиям, координат центров шаблонов поиска и размера модуля CPUR. Определяют двоичные значения 0 и 1 по комбинации светлых и темных пикселей на сетке выборки.
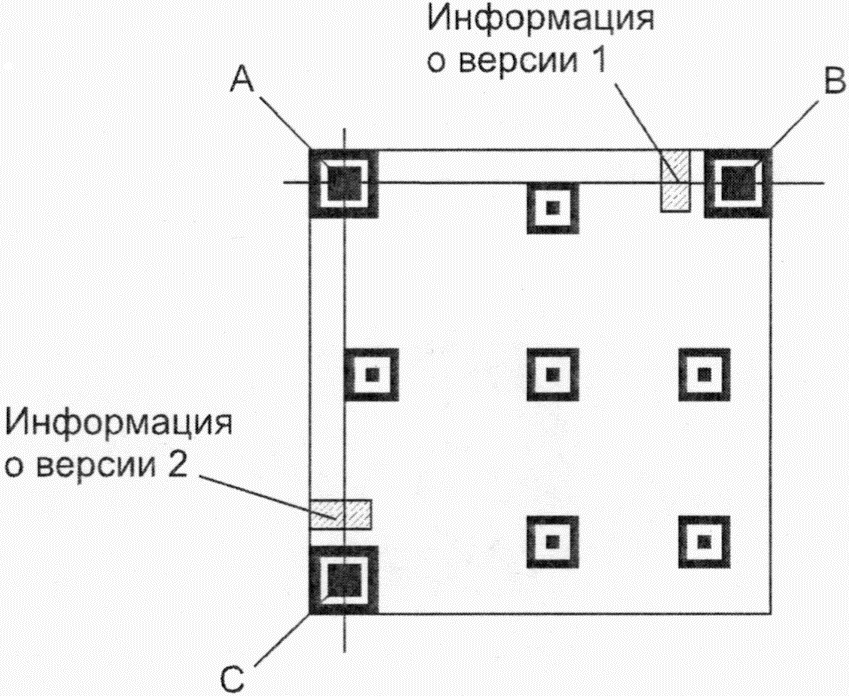
3) Определяют версию, используя обнаружение и исправление ошибок, если необходимо, с помощью таблицы D.1 приложения D.
4) Если число обнаруженных ошибок превышает способность к их исправлению, вычисляют ширину левого нижнего шаблона WDL и выполняют действия, указанные на этапах a), b) и c) для декодирования блока 2 информации о версии.
ИС МЕГАНОРМ: примечание. Обозначение подпункта дано в соответствии с официальным текстом документа. |
a) Для символа версии 1, повторно определяют размер X как средний интервал между центрами темных и светлых модулей в верхнем шаблоне синхронизации. Подобным образом вычисляют размер Y как средний интервал между центрами темных и светлых модулей в левом шаблоне синхронизации. Определяют сетку выборки на основании: 1) базовой горизонтальной линии, проведенной через верхний шаблон синхронизации, совместно с линиями, параллельными базовой горизонтальной линии на расстоянии Y, включая шесть линий выше базовой горизонтальной линии и столько линий ниже этой линии, сколько требуется для данной версии; и 2) вертикальной линии, проведенной по левой стороне шаблона синхронизации совместно с линиями, параллельными этой линии и проведенными на расстоянии X, включая шесть линий левее этой линии и столько линий правее этой линии, сколько требуется для данной версии. Для символов версии 2 и более, определяют координаты центров всех направляющих шаблонов согласно 6.3.6 и приложению E, а затем формируют сетку выборки с линиями, проведенными на равном удалении от этих точек.
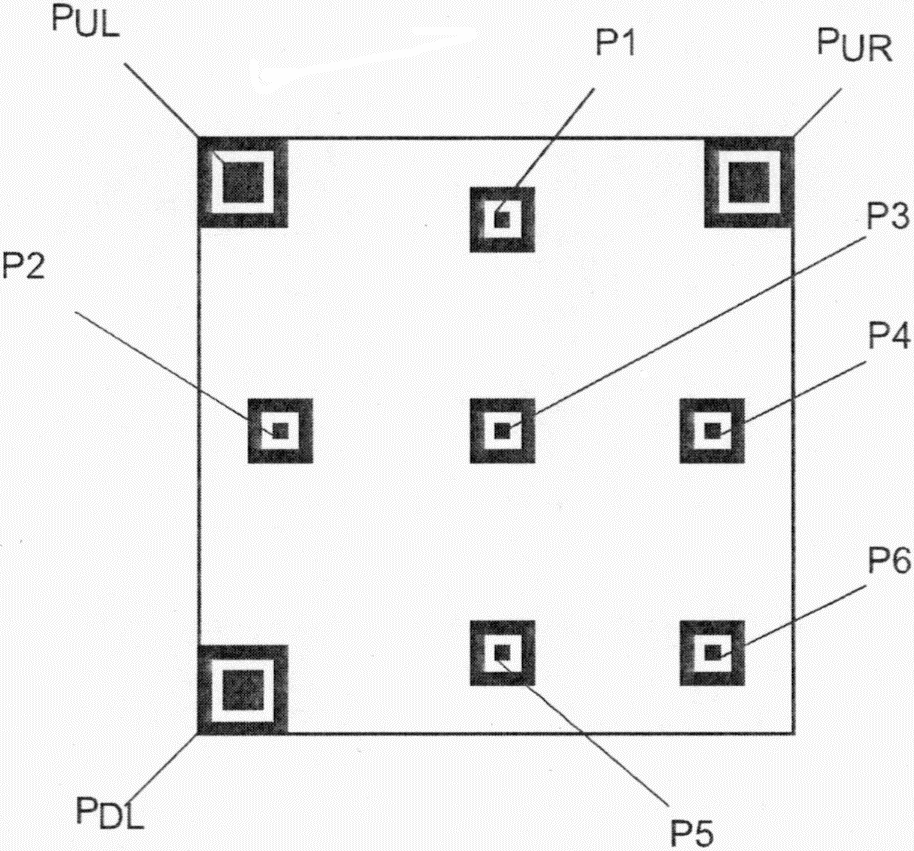
1) Делят ширину WUL левого верхнего шаблона поиска PUL на 7, чтобы вычислить размер модуля CPUL: CPUL = WUL/7.
2) Определяют приблизительные координаты центров направляющих шаблонов P1 и P2 (см. рисунок 34 <1>) на основе координат центра A левого верхнего шаблона поиска PUL, линий, параллельных направляющим линиям AB и AC <2>, <3> и размера модуля CPUL.
--------------------------------
<1> Указана ссылка на рисунок 34 вместо ссылки на рисунок 33, приведенный в ИСО/МЭК 18004-2015.
<2> Исключена ссылка на элемент стандарта "7c", приведенный в ИСО/МЭК 18004-2015.
<3> Направляющие линии AB и AC приведены на рисунке 33.
3) Сканируют направляющие шаблоны P1 и P2, начиная с приблизительной координаты центрального пикселя до контура белого квадрата, чтобы найти фактические координаты центра Xi и Yj (см. рисунок 35).
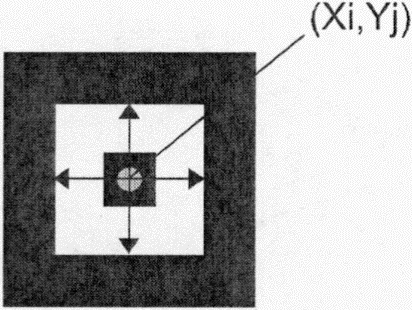
4) Определяют приблизительные координаты центра направляющего шаблона P3 на основе координат центра A верхнего левого шаблона поиска PUL и фактических координат центров направляющих шаблонов P1 и P2, полученных на этапе 3).
5) Находят фактические координаты центра направляющего шаблона P3 с помощью процедуры этапа 3).
6) Находят Lx - расстояние по горизонтали между центрами направляющих шаблонов P2 и P3, и Ly, расстояние по вертикали между центрами направляющих шаблонов P1 и P3. Делят Lx и Ly на AP (см. далее) для получения размеров модуля CPx по левой стороне и CPy по правой стороне в верхней левой области символа (см. рисунок 35)
CPx = Lx/AP;
CPy = Ly/AP,
где AP - расстояние в модулях между центрами направляющих шаблонов (см. таблицу E.1).
Таким же образом находят Lx', расстояние по горизонтали между центрами верхнего левого шаблона поиска PUL и направляющего шаблона P1 и Ly', расстояние по вертикали между центрами верхнего левого шаблона поиска PUL и направляющего шаблона P2. Делят Lx' и Ly' для получения размеров модуля CPx' по верхней стороне и CPy' по левой стороне в верхней левой области символа по формуле
CPx' = Lx'/(координата столбца центрального модуля направляющего шаблона P1 - координата столбца центрального модуля верхнего левого шаблона поиска PUL)
CPy' = Ly'/(координата строки центрального модуля направляющего шаблона P2 - координата строки центрального модуля верхнего левого шаблона поиска PUL).
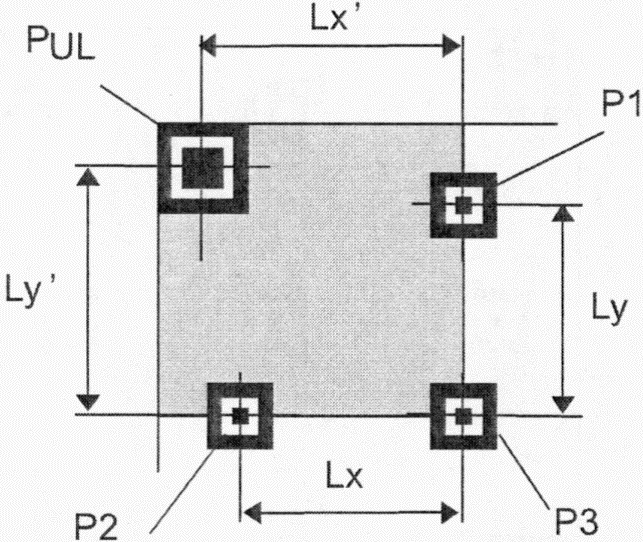
Рисунок 36 - Верхняя левая область символа
7) Определяют сетку выборки, покрывающую верхнюю левую область символа на основе размеров модулей CPx, CPx', CPy и CPy', представленных по каждой стороне верхней левой области символа.
8) Таким же образом определяют примерную сетку выборки для верхней правой области (охватывающей верхний правый шаблон поиска PUR и направляющие шаблоны P1, P3 и P4) и для нижней левой области (охватывающей нижний левый шаблон поиска PDL и направляющие шаблоны P2, P3 и P5) символа.
9) Для направляющего шаблона P6 (см. рисунок 37) определяют приблизительные координаты центрального модуля из размеров модулей CPx' и CPy', значения которых определены из расстояний между направляющими шаблонами P3, P4 и P5, путем проведения вспомогательных линий через центры направляющих шаблонов P3 и P4 и через P3 и P5 соответственно и учета центральных координат этих шаблонов.
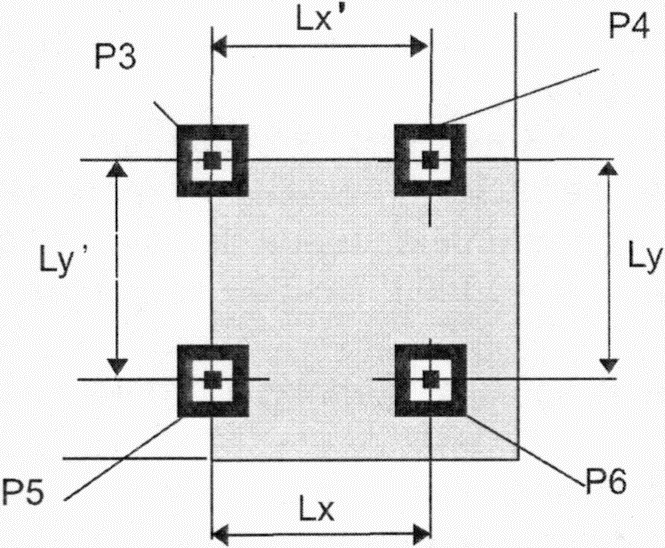
Рисунок 37 - Нижняя правая область символа
10) Повторяют этапы e) - h) для определения сетки выборки для нижней правой области символа.
11) Таким же образом определяют сетки выборки для неохваченных областей символа.
i) Просматривают области изображения размером 3 x 3 пикселей с центрами на пересечениях линий сетки выборки и определяют, является этот модуль светлым или темным на основании глобального порога. Формируют битовую матрицу, присваивая двоичную 1 темным модулям и двоичный 0 светлым модулям.
ИС МЕГАНОРМ: примечание. В официальном тексте документа, видимо, допущена опечатка: приложение C.3 и пункт C.3 отсутствуют. |
j) Декодируют информацию о формате, смежную с верхним левым направляющим шаблоном в соответствии с приложением C.3 для получения уровня исправления ошибок и указателя шаблона маски, примененной к символу. Если число обнаруженных ошибок превышает способность их исправления, повторяют эту процедуру для декодирования информации о формате, смежную с верхним правым и нижним левым шаблонами поиска.
k) Если невозможно получить из двоичной строки надлежащую информацию о формате, предпринимают попытки определения, является ли правильной последовательность битов, если их прочитать в обратном порядке. В случае успеха продолжают декодирование изображения зеркально отображенного символа, меняя местами координаты строк и столбцов.
l) Переходят к этапу y.
m) Для символов Micro QR Code определяют возможный угол поворота символа относительно координатных осей изображения, анализируя углы наклона линий, полученных на этапе b) 3), по отношению к осям датчика изображения, а именно 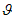 ,
,  ,
, 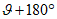 и
и 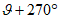 (см. рисунок 38).
(см. рисунок 38).
, и (см. рисунок 38).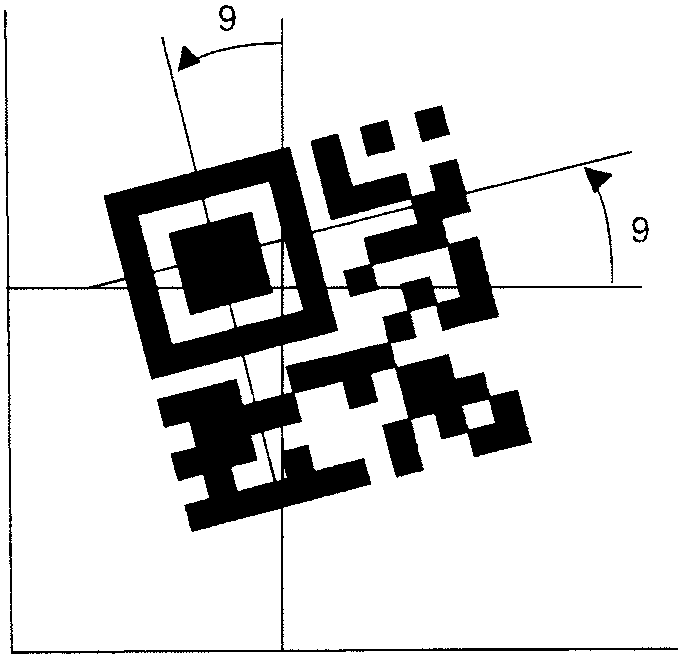
Рисунок 38 - Положение угла 
относительно осей датчика изображения
n) Проводят три линии, параллельные каждой из осей шаблона поиска на одинаковом расстоянии через весь шаблон, и измеряют расстояние от точки A до точки B на каждой линии. Расстояние между линиями не ограничено, однако все три линии должны проходить через шаблон поиска.
o) Вычисляют приблизительный размер X модуля символа по каждой оси как седьмую часть среднего из этих трех расстояний от A до B, определенных на этапе n.
p) Последовательно выбирают каждую сторону внешнего блока шаблона поиска и продлевают линию, направленную наружу от шаблона поиска в обоих направлениях параллельно краю и на расстояние 0,5X, отступая внутрь от края.
q) Осуществляют поиск шаблонов синхронизации:
1) определяют два края шаблона поиска номинально перпендикулярные друг к другу, каждый из которых имеет оба следующих признака:
i) Свободную область не менее 1,5X в одном направлении;
ii) Область с чередующимися светлыми и темными участками с центрами на расстоянии 1X от края шаблона поиска в противоположном направлении (кандидат на шаблон синхронизации).
2) Проверяют, что число темных модулей в каждом кандидате на шаблон синхронизации от двух до пяти.
r) Определяют приблизительную версию символа по количеству темных элементов шаблона синхронизации:
- при двух темных элементах, символ имеет версию M1;
- при трех темных элементах, символ имеет версию M2;
- при четырех темных элементах, символ имеет версию M3;
- при пяти темных элементах, символ имеет версию M4.
s) Из центра первого темного модуля каждой стороны шаблона синхронизации проводят линию, параллельную смежной стороне шаблона поиска до пересечения с соответствующей линией, проведенной из другой стороны и просматривая области изображения размером 3 x 3 пикселей с интервалом 1X вдоль этих линий, определяют статус каждого модуля (светлый или темный) блока информации о формате. Определяют двоичную строку информации о формате, принимая темный пиксель за двоичный 1 и светлый пиксель за двоичный 0.
t) Реализуют маскирование информации о формате, применяя операцию XOR к его двоичной строке с помощью шаблона из 7.9.2, и декодируют информацию о формате (применяя процедуру исправления ошибок по приложению B, если необходимо) для получения номера символа (и, следовательно, версии и уровня исправления ошибок символа) и указателя шаблона маски, примененный к данным символа.
u) Если невозможно получить из двоичной строки информации о формате надлежащую последовательность, предпринимают попытки определить, является ли правильной последовательность битов при их считывании в обратном порядке. В случае успеха продолжают декодирование зеркально отображенного символа, меняя местами координаты строк и столбцов. Если отличие от надлежащей последовательности по приложению C не более двух битов, заменяют эту последовательность и декодируют замененную информацию о формате, чтобы получить номер символа и шаблон маски данных.
v) Убеждаются, что модуль имеет размер X по каждой оси, путем деления полной ширины от внешнего края шаблона поиска, смежного со свободной зоной, до внешнего края последнего темного модуля в шаблоне синхронизации, на число модулей, соответствующей версии символа.
w) Устанавливают сетку выборки, соответствующую версии символа, из линий по каждой оси, параллельных друг другу и стороне шаблона поиска, отстоящих на 1X, и проходящих через центры модулей шаблона синхронизации и подобных позиций в шаблоне поиска.
x) Просматривают области изображения размером 3 x 3 пикселя, расположенные на пересечениях линий сетки выборки, и определяют, является ли модуль темным или светлым на основании глобального порога. Формируют битовую матрицу, принимая темные модули как двоичные 1, и светлые модули как двоичные 0.
y) Выполняют процедуру маскирования, применяя операцию XOR шаблона маски данных к области кодирования символа, и восстанавливают знаки символа, представляющие данные и кодовые слова исправления ошибок. Эта процедура является обратной процессу маскирования данных, применяемому в процессе кодирования.
z) Определяют кодовые слова символа согласно правилам размещения, указанным в 7.7.3.
aa) Перегруппировывают кодовые слова по блокам, как требуется для данной версии символа и уровня исправления ошибок, используя процесс, обратный к приведенному в 7.6 этап 3).
bb) Проводят декодирующую процедуру обнаружения и исправления ошибок по приложению B, чтобы исправить такое число ошибок и стираний, которое максимально возможно для данной версии символа и уровня исправления ошибок.
cc) Восстанавливают первоначальный двоичный поток сообщения, собирая блоки данных в последовательность.
dd) Подразделяют двоичный поток данных на сегменты, каждый из которых начинается с индикатора режима и индикатора числа знаков.
ee) Декодируют каждый сегмент в соответствии правилам, действительными для данного режима.
Символы QR Code могут быть использованы в среде автоматического распознавания со множеством символов других символик (см. приложение L). Хотя символы QR Code Model 1 и символы QR Code могут быть распознаны автоматически путем анализа шаблона маски информации о формате, символы Model 1 не должны использоваться в той же самой среде, что и символы QR Code.
Все закодированные знаки данных должны быть включены в передачу данных. Функциональные шаблоны, информация о формате и информация о версии, знаки исправления ошибок, знаки-заполнители и остаточные знаки не подлежат передаче. Заданным по умолчанию режимом передачи для всех данных должен быть байтовый режим.
Блок заголовка структурного соединения не должен передаваться декодерами, работающими в буферизированном режиме, которые восстановили полное сообщение перед передачей. Если декодер работает в небуферизованном режиме, заголовок структурного дополнения должен быть передан как первые 2 байта каждого символа. Более сложные интерпретации, включая передачу данных с интерпретацией в расширенном канале, приведены далее.
В ИСО/МЭК 15424 установлена стандартная процедура сообщения о считанной символике, вместе с набором опций в декодере и любых особых свойств, встречающихся в символе.
Как только структура данных (включая использование любой интерпретации ECI) была идентифицирована, соответствующий идентификатор символики должен быть добавлен декодером как преамбула к передаваемым данным; если используются интерпретации ECI, обязательно требуется идентификатор символики. В приложении F содержатся значения идентификатора символики, которые используются в QR Code.
В системах, поддерживающих протокол ECI, при каждой передаче требуется передача идентификатора символики. Всякий раз, когда встречается индикатор режима ECI, в выходных данных он должен быть передан как управляющий знак 5CHEX (представляющий собой знак "\" по ИСО/МЭК 8859-1 и спецификации организации AIM, устанавливающей интерпретации в расширенном канале (ECI) <1>, и отображается как знак 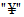 по JIS X 0201). Кодовое слово(а), представляющее обозначение ECI преобразуют в шестизначное число, используя правила, обратные приведенным в таблице 4. Указанные 6 цифр должны быть переданы как соответствующие 8-битовые значения из диапазона 30HEX - 39HEX, непосредственно после управляющего знака.
по JIS X 0201). Кодовое слово(а), представляющее обозначение ECI преобразуют в шестизначное число, используя правила, обратные приведенным в таблице 4. Указанные 6 цифр должны быть переданы как соответствующие 8-битовые значения из диапазона 30HEX - 39HEX, непосредственно после управляющего знака.
--------------------------------
<1> См. спецификацию [22].
При распознавании последовательности \nnnnnn прикладное программное обеспечение должно интерпретировать все последующие знаки как входящие в ECI, определенную 6 цифрами обозначения ECI. Эта интерпретация действует:
- до окончания закодированных данных;
- до изменения на новую ECI, обозначенную индикатором режима 0111, в соответствии с правилами, приведенными в спецификации организации AIM, устанавливающей ECI.
При возвращении к интерпретации, заданной по умолчанию, декодер должен вывести соответствующую управляющую последовательность как префикс к данным.
Если знак 5CHEX должен быть использован в кодируемых данных, при передаче нужно руководствоваться следующими правилами: если знак 5CHEX встречается как знак в данных, при передаче декодер выдает два байта со значением 5CHEX, а единственный знак 5CHEX в передаваемых данных всегда сигнализирует об управляющей последовательности.
Пример 1
a) Кодируемые данные
(шестнадцатеричные значения): 41 42 43 5C 31 32 33 34
Передаваемые данные: 41 42 43 5C 5C 31 32 33 34
b) Кодируемые данные: ABC за которым находятся
<последующие данные>,
закодированные по правилам ECI 123456.
Передаваемые данные: 41 42 43 5C 31 32 33 34 35 36
<последующие данные>
Пример 2 (с использованием данных 7.4.2.2)
Сообщение содержит индикатор режима ECI/обозначение ECI/
индикатор режима/индикатор числа знаков/данные в форме
0111 00001001 0100 00000101 10100001 10100010 10100011 10100100 10100101
Идентификатор символики ]Q2 (см. приложение F) должен быть добавлен
к передаваемым данным.
Передача (шестнадцатеричные значения): 5D 51 32 5C 30 30 30 30 30 39 A1 A2 A3 A4 A5
Закодированные данные в ECI 000009: 
ИС МЕГАНОРМ: примечание. Текст дан в соответствии с официальным текстом документа. |
В режиме структурированного соединения, когда индикатор режима ECI расположен в начале символа, последующие знаки данных следует интерпретировать как находящиеся в режиме интерпретации(й) в расширенном канале (ECI), который был в силе конце предшествующего символа.
Примечание - Знак, имеющий значение 5CHEX, эквивалентен знаку ОБРАТНАЯ ДРОБНАЯ ЧЕРТА "\" в наборе знаков ИСО/МЭК 8859-1 и знаку 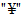 по JIS X 0201.
по JIS X 0201.
В режимах с подразумеваемым знаком FNC1 в первой или второй позиции, этот знак не может быть передан непосредственно, так как отсутствует соответствующее значение байта. Поэтому необходимо указать его присутствие в первой или второй позиции передачей соответствующего идентификатора символики (]Q3, ]Q4, ]Q5 или ]Q6), установленного в приложении F. В соответствии со спецификацией по применению эти знаки могут встречаться и в других местах сообщения в качестве разделителей полей данных, представляемых в алфавитно-цифровом режиме знаком % и в байтовом режиме управляющим знаком GS (шестнадцатеричное значение 1DHEX по ASCII/JIS8). В обоих случаях декодер должен передать шестнадцатеричное значение 1DHEX из набора знаков ASCII/JIS8.
Если в символах в режиме FNC1 знак % должен быть закодирован как данные, в алфавитно-цифровом режиме, он должен быть представлен в символе как %%. Если декодер встречает такую последовательность, он должен передать один знак %.
(обязательное)
ОБНАРУЖЕНИЯ И ИСПРАВЛЕНИЯ ОШИБОК
Кодовые слова исправления ошибок получают путем деления полинома кодовых слов данных, где каждое кодовое слово является коэффициентом полинома в порядке убывания степени, на порождающий полином. Коэффициенты полинома (остатка от этого деления) являются значениями кодовых слов исправления ошибок.
В таблице A.1 приведены порождающие полиномы для кодов исправления ошибок для всех символов QR Code всех версий и уровней исправления ошибок. Число кодовых слов исправления ошибок, требуемых для конкретной версии и уровня исправления ошибок, может быть определено по таблице 9, в которой 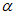 - это примитивный элемент 2 из поля GF(28). Каждый порождающий полином вычисляют как произведение полиномов: x - 20, x - 21, ..., x - 2n-1; где n - степень порождающего полинома.
- это примитивный элемент 2 из поля GF(28). Каждый порождающий полином вычисляют как произведение полиномов: x - 20, x - 21, ..., x - 2n-1; где n - степень порождающего полинома.
Таблица A.1
Порождающие полиномы для кодовых слов
исправления ошибок по Риду-Соломону
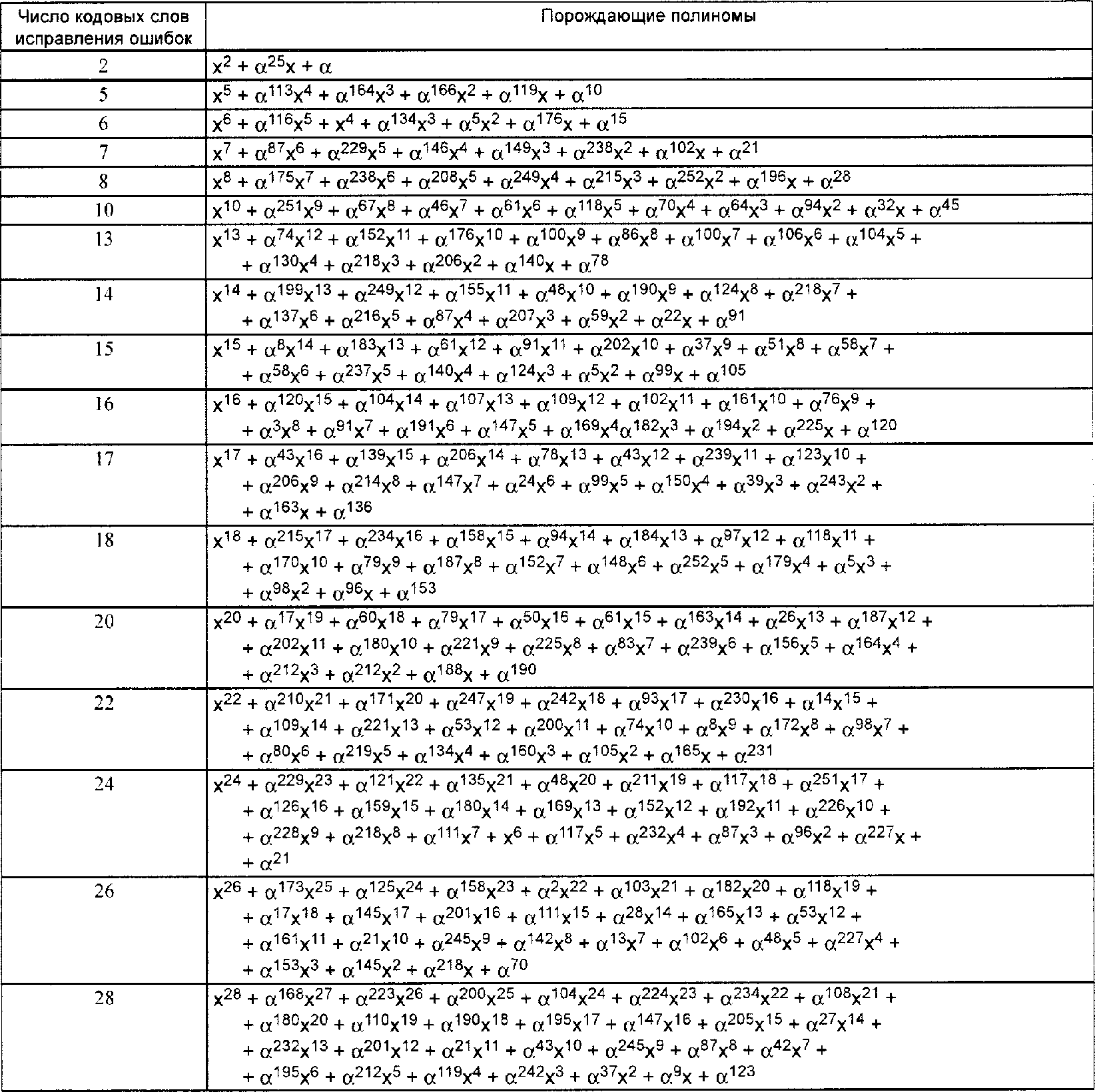
Продолжение таблицы A.1
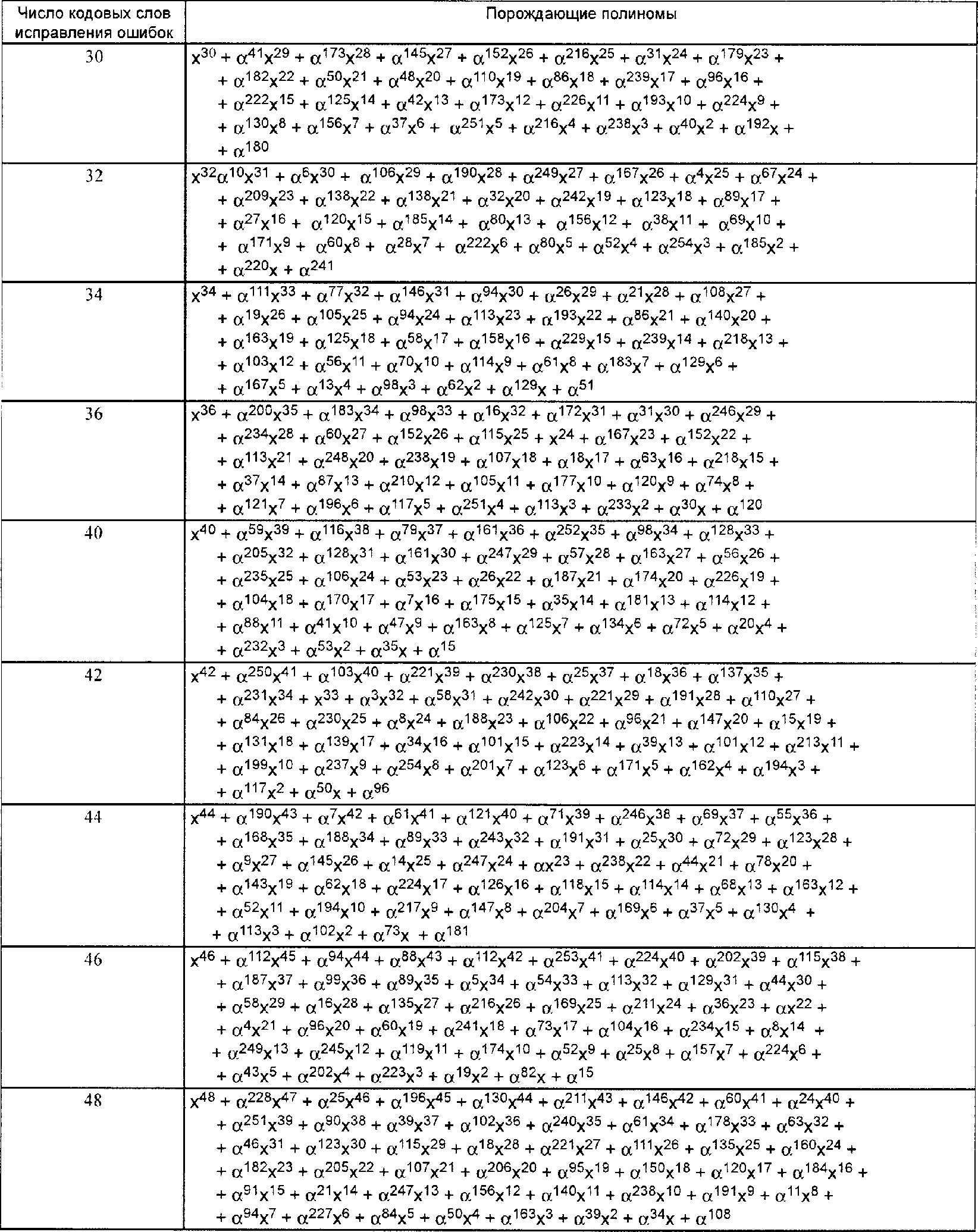
Продолжение таблицы A.1
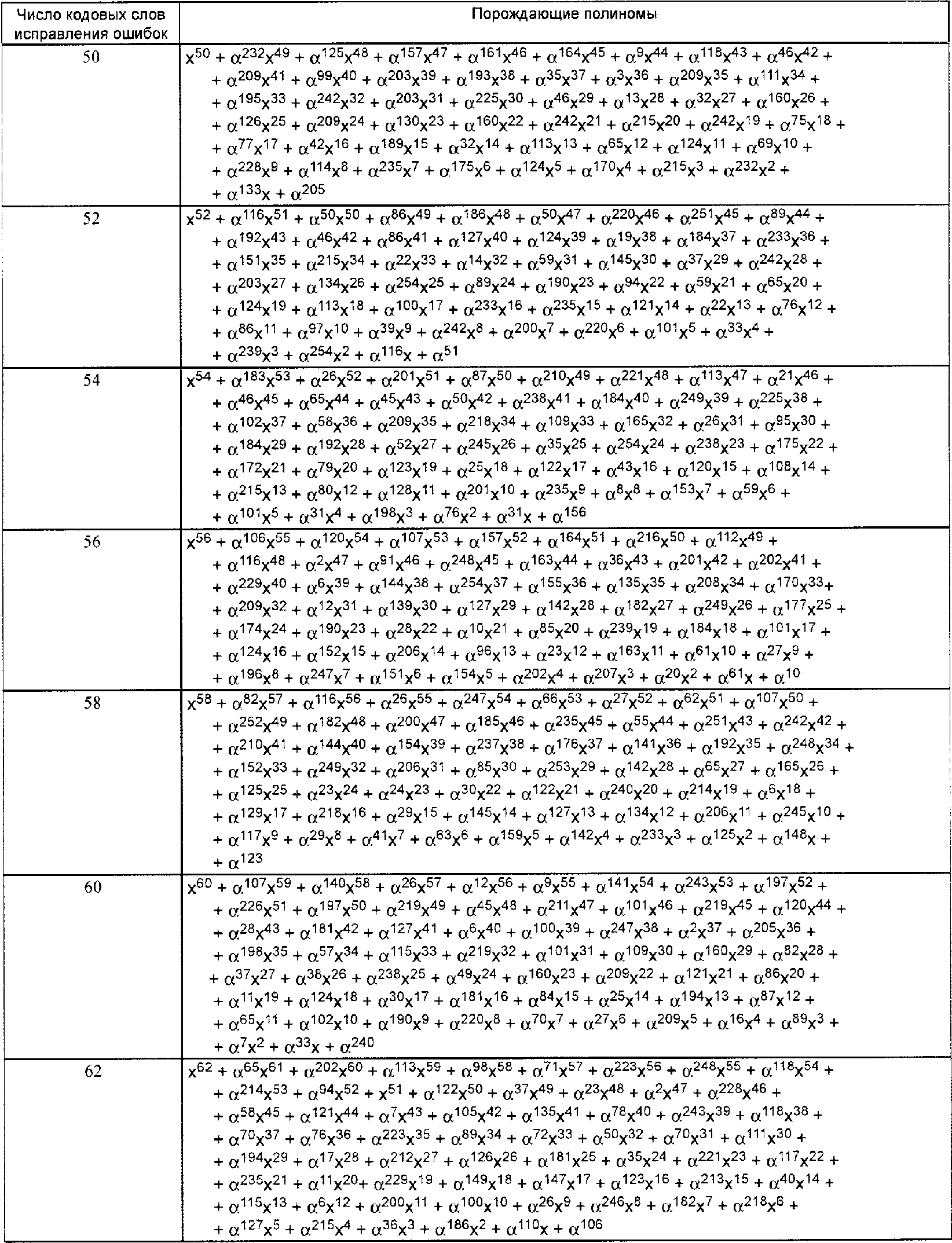
Окончание таблицы A.1

(обязательное)
ИСПРАВЛЕНИЯ ОШИБОК ПРИ ДЕКОДИРОВАНИИ
Для примера возьмем символ версии 1-M, для которого для исправления ошибок используется код Рида-Соломона (26, 16, 4) в поле GF(28). При условии, что код после применения процедуры маскирования представляет собой R = (r0, r1, r2, ..., r25).
Таким образом
R(x) = r0, + r1x + r2x2 + r25x25,
где ri (i = 0 - 25) - элемент поля GF(28).
i) Вычисляют n синдромов (n равно числу кодовых слов, доступных для исправления ошибок, вычисленному по формуле (c - k - p) в соответствии с таблицей 9).
Вычисляют синдромы Si (i = 0 - (n - 1))
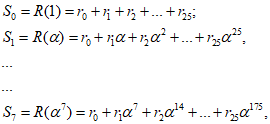
где 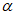 - элемент поля GF(28).
- элемент поля GF(28).
ii) Определяют позиции ошибок
Вычисляют переменные  (i = 1 - 4) для каждой позиции ошибки по вышеуказанным формулам.
(i = 1 - 4) для каждой позиции ошибки по вышеуказанным формулам.
Подставляют переменную в следующий полином и заменяют элементы GF(28) один за другим
Обнаруживают, что ошибка находится на j-й цифре (считая от 0-й цифры) для элемента 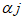 , что приводит к
, что приводит к  .
.
.iii) Определяют размер ошибки
Исходя из предположения, что ошибка находится на j1, j2, j4 цифрах в (ii) выше, вычисляют размер ошибки по формулам
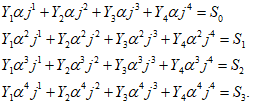
Решают вышеуказанные уравнения для определения размера каждой ошибки Yi (i = 1 - 4).
iv) Исправление ошибок
Исправляют ошибки, прибавляя к значению размера каждой ошибки значения, находящиеся на позициях каждой ошибки.
(обязательное)
Информация о формате представляет собой 15-битовую последовательность, состоящую из 5 битов данных и 10 битов исправления ошибок по алгоритму BCH. В настоящем приложении приведен порядок вычисления битов исправления ошибок и процесс исправления ошибок при декодировании.
C.1 Вычисление битов исправления ошибок
Для получения битов исправления ошибок используют код Боуза-Чоудхури-Хоквингема (Bose-Chaudhuri-Hocquenghem, BCH) (15,5). Полином, коэффициенты которого - биты строки данных, делят на порождающий полином G(x) = x10 + x8 + x5 + x4 + x2 + x + 1. Коэффициенты полинома-остатка преобразуют в двоичную строку и добавляют к битам данных, чтобы получить строку кода BCH (15,5). В завершение для маскирования применяют операцию XOR со строкой 101010000010010 (для символов QR Code) или 100010001000101 (для символов Micro QR Code) для гарантии того, что ни при каком уровне исправления ошибок и шаблоне маски битовое представление информации о формате не получится целиком нулевым.
Пример
Уровень исправления ошибок M; данные шаблона маски 101 | |
Двоичная строка: | 00101 |
Полином: | x2 + 1 |
Повышают степень (15 - 5): | x12 + x10 |
Делят на G(x): | = (x10 + x8 + x5 + x4 + x2 + x + 1)x2 + (x7 + x6 + x4 + x3 + x2) |
Добавляют строку коэффициентов вышеупомянутого полинома-остатка к информационным данным о формате: | |
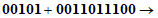 | 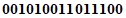 |
XOR с маской | 101010000010010 |
Результат: | 100000011001110 |
Размещают эти биты информации в областях информации о формате согласно 7.9.
C.2 Этапы обнаружения и исправления ошибок при декодировании
Реализуют маскирование модулей информации о формате, применяя операцию XOR к последовательности битов с шаблоном 101010000010010 (для символов QR Code) или 100010001000101 (для символов Micro QR Code).
Интервал Хэмминга (Hamming distance) для кода исправления ошибок, используемый в информации о формате, должен быть 7, что дает возможность исправить до трех ошибочно считанных битов. Есть 32 надлежащих битовых последовательности для информации о формате, так что декодирование можно достаточно эффективно осуществить с использованием таблицы C.1. Считанные последовательности битов из области информации о формате символа побитово сравнивают с 32 надлежащими двоичными строками информации о формате, приведенными в таблице C.1. Принимают двоичную строку, приведенную в таблице C.1, которая является наиболее соответствующей считанной из символа, если строки отличаются на 3 бита или менее.
Пример (для символа QR Code)
Биты, прочитанные из области информации о формате: | 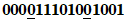 |
Наиболее близкая строка из таблицы: | 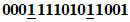 |
Поскольку считанная последовательность и строка из таблицы отличаются только двумя битами, то сравнение считают успешным, так что формат символа утверждают как использующий уровень исправления ошибок M и шаблон маски 011.
Таблица C.1
Последовательность до маскирования | Последовательность после маскирования (символы QR Code) | Последовательность после маскирования (символы Micro QR Code) | |||
Биты данных | Биты исправления ошибок | Двоичная | Шестнадцатеричная | Двоичная | Шестнадцатеричная |
00000 | 0000000000 | 101010000010010 | 5412 | 100010001000101 | 4445 |
00001 | 0100110111 | 101000100100101 | 5125 | 100000101110010 | 4172 |
00010 | 1001101110 | 101111001111100 | 5E7C | 100111000101011 | 4E2B |
00011 | 1101011001 | 101101101001011 | 5B4B | 100101100011100 | 4B1C |
00100 | 0111101011 | 100010111111001 | 45F9 | 101010110101110 | 55AE |
00101 | 0011011100 | 100000011001110 | 40CE | 101000010011001 | 5099 |
00110 | 1110000101 | 100111110010111 | 4F97 | 101111111000000 | 5FC0 |
00111 | 1010110010 | 100101010100000 | 4AA0 | 101101011110111 | 5AF7 |
01000 | 1111010110 | 111011111000100 | 77C4 | 110011110010011 | 6793 |
01001 | 1011100001 | 111001011110011 | 72F3 | 110001010100100 | 62A4 |
01010 | 0110111000 | 111110110101010 | 7DAA | 110110111111101 | 6DFD |
01011 | 0010001111 | 111100010011101 | 789D | 110100011001010 | 68CA |
01100 | 1000111101 | 110011000101111 | 662F | 111011001111000 | 7678 |
01101 | 1100001010 | 110001100011000 | 6318 | 111001101001111 | 734F |
01110 | 0001010011 | 110110001000001 | 6C41 | 111110000010110 | 7C16 |
01111 | 0101100100 | 110100101110110 | 6976 | 111100100100001 | 7921 |
10000 | 1010011011 | 001011010001001 | 1689 | 000011011011110 | 06DE |
10001 | 1110101100 | 001001110111110 | 13BE | 000001111101001 | 03E9 |
10010 | 0011110101 | 001110011100111 | 1CE7 | 000110010110000 | 0CB0 |
10011 | 0111000010 | 001100111010000 | 19D0 | 000100110000111 | 0987 |
10100 | 1101110000 | 000011101100010 | 0762 | 001011100110101 | 1735 |
10101 | 1001000111 | 000001001010101 | 0255 | 001001000000010 | 1202 |
10110 | 0100011110 | 000110100001100 | 0D0C | 001110101011011 | 1D5B |
10111 | 0000101001 | 000100000111011 | 083B | 001100001101100 | 186C |
11000 | 0101001101 | 011010101011111 | 355F | 010010100001000 | 2508 |
11001 | 0001111010 | 011000001101000 | 3068 | 010000000111111 | 203F |
11010 | 1100100011 | 011111100110001 | 3F31 | 010111101100110 | 2F66 |
11011 | 1000010100 | 011101000000110 | 3A06 | 010101001010001 | 2A51 |
11100 | 0010100110 | 010010010110100 | 24B4 | 011010011100011 | 34E3 |
11101 | 0110010001 | 010000110000011 | 2183 | 011000111010100 | 31D4 |
11110 | 1011001000 | 010111011011010 | 2EDA | 011111010001101 | 3E8D |
11111 | 1111111111 | 010101111101101 | 2BED | 011101110111010 | 3BBA |
(обязательное)
D.1 Общие положения
Информация о версии представляет собой 18-битовую последовательность, состоящую из 6 битов данных и 12 битов исправления ошибок по коду Голея (Golay code). В настоящем приложении описан алгоритм вычисления битов исправления ошибок при кодировании и процесс исправления ошибок при декодировании.
D.2 Вычисление битов исправления ошибок
Для получения битов исправления ошибок используют код Голея (Golay code) (18,6). Полином, коэффициенты которого - это биты строки данных, делят на порождающий полином G(x) = x12 + x11 + x10 + x9 + x8 + x5 + x2 + 1. Коэффициенты строки полинома-остатка преобразуют в двоичную строку и добавляют к битам данных, чтобы получить строку кода Голея (18,6).
Пример
Версия: | 7 |
Двоичная строка: | 000111 |
Полином: | x2 + x + 1 |
Повышают степень (18 - 6): | x14 + x13 + x12 |
Делят на G(x): | = (x12 + x11 + x10 + x9 + x8 + x5 + x2 + 1)x2 + (x11 + x10 + x7 + x4 + x2) |
Добавляют строку коэффициентов вышеупомянутого полинома-остатка к строке данных | |
информации о версии: | 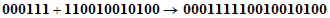 |
Размещают указанные биты в областях информации о версии в соответствии с 7.10.
В таблице D.1 приведены полные двоичные потоки информации о версии для всех версий.
D.3 Этапы исправления ошибок при декодировании
Интервал Хэмминга (Hamming distance) для кода исправления ошибок используют в информации о версии 8, что дает возможность исправить до трех ошибочно считанных битов. Установлены 34 надлежащие битовые последовательности для информации о версии, так что декодирование можно с достаточной эффективностью проводить с использованием таблицы D.1. Считанные последовательности битов из области информации о версии символа побитово сравнивают с 34 надлежащими двоичными строками информации о версии по таблице D.1. Принимают двоичную строку из таблицы D.1, которая является наиболее близкой по значению к считанной, если строки отличаются тремя битами или менее.
Пример
Биты, считанные из области информации о версии: |  |
Наиболее близкая по значению строка из таблицы: |  |
Поскольку считанная последовательность и строка, приведенная в таблице D.1, отличаются только одним битом, то сравнение считают успешным; в результате подтверждается соответствие символа версии 7.
Таблица D.1
Версия | Двоичный поток | Шестнадцатеричный поток |
7 | 00 0111 1100 1001 0100 | 07C94 |
8 | 00 1000 0101 1011 1100 | 085BC |
9 | 00 1001 1010 1001 1001 | 09A99 |
10 | 00 1010 0100 1101 0011 | 0A4D3 |
11 | 00 1011 1011 1111 0110 | 0BBF6 |
12 | 00 1100 0111 0110 0010 | 0C762 |
13 | 00 1101 1000 0100 0111 | 0D847 |
14 | 00 1110 0110 0000 1101 | 0E60D |
15 | 00 1111 1001 0010 1000 | 0F928 |
16 | 01 0000 1011 0111 1000 | 10B78 |
17 | 01 0001 0100 0101 1101 | 1145D |
18 | 01 0010 1010 0001 0111 | 12A17 |
19 | 01 0011 0101 0011 0010 | 13532 |
20 | 01 0100 1001 1010 0110 | 149A6 |
21 | 01 0101 0110 1000 0011 | 15683 |
22 | 01 0110 1000 1100 1001 | 168C9 |
23 | 01 0111 0111 1110 1100 | 177EC |
24 | 01 1000 1110 1100 0100 | 18EC4 |
25 | 01 1001 0001 1110 0001 | 191E1 |
26 | 01 1010 1111 1010 1011 | 1AFAB |
27 | 01 1011 0000 1000 1110 | 1B08E |
28 | 01 1100 1100 0001 1010 | 1CC1A |
29 | 01 1101 0011 0011 1111 | 1D33F |
30 | 01 1110 1101 0111 0101 | 1ED75 |
31 | 01 1111 0010 0101 0000 | 1F250 |
32 | 10 0000 1001 1101 0101 | 209D5 |
33 | 10 0001 0110 1111 0000 | 216F0 |
34 | 10 0010 1000 1011 1010 | 228BA |
35 | 10 0011 0111 1001 1111 | 2379F |
36 | 10 0100 1011 0000 1011 | 24B0B |
37 | 10 0101 0100 0010 1110 | 2542E |
38 | 10 0110 1010 0110 0100 | 26A64 |
39 | 10 0111 0101 0100 0001 | 27541 |
40 | 10 1000 1100 0110 1001 | 28C69 |
(обязательное)
Направляющие шаблоны располагают симметрично по обе стороны диагонали, проходящей из верхнего левого угла к нижнему правому углу символа. Они должны быть расположены без отклонений, насколько возможно между шаблоном синхронизации и противоположной стороной символа без любого отклонения интервала между шаблоном синхронизации и первым направляющим шаблоном внутри символа.
В таблице E.1 для каждой версии приведено число направляющих шаблонов и координаты строки и столбца центрального модуля каждого направляющего шаблона.
Таблица E.1
модуля направляющих шаблонов
Версия | Число направляющих шаблонов | Координаты (столбец/строка) центрального модуля | ||||||
1 | 0 | - | ||||||
2 | 1 | 6 | 18 | |||||
3 | 1 | 6 | 22 | |||||
4 | 1 | 6 | 26 | |||||
5 | 1 | 6 | 30 | |||||
6 | 1 | 6 | 34 | |||||
7 | 6 | 6 | 22 | 38 | ||||
8 | 6 | 6 | 24 | 42 | ||||
9 | 6 | 6 | 26 | 46 | ||||
10 | 6 | 6 | 28 | 50 | ||||
11 | 6 | 6 | 30 | 54 | ||||
12 | 6 | 6 | 32 | 58 | ||||
13 | 6 | 6 | 34 | 62 | ||||
14 | 13 | 6 | 26 | 46 | 66 | |||
15 | 13 | 6 | 26 | 48 | 70 | |||
16 | 13 | 6 | 26 | 50 | 74 | |||
17 | 13 | 6 | 30 | 54 | 78 | |||
18 | 13 | 6 | 30 | 56 | 82 | |||
19 | 13 | 6 | 30 | 58 | 86 | |||
20 | 13 | 6 | 34 | 62 | 90 | |||
21 | 22 | 6 | 28 | 50 | 72 | 94 | ||
22 | 22 | 6 | 26 | 50 | 74 | 98 | ||
23 | 22 | 6 | 30 | 54 | 78 | 102 | ||
24 | 22 | 6 | 28 | 54 | 80 | 106 | ||
25 | 22 | 6 | 32 | 58 | 84 | 110 | ||
26 | 22 | 6 | 30 | 58 | 86 | 114 | ||
27 | 22 | 6 | 34 | 62 | 90 | 118 | ||
28 | 33 | 6 | 26 | 50 | 74 | 98 | 122 | |
29 | 33 | 6 | 30 | 54 | 78 | 102 | 126 | |
30 | 33 | 6 | 26 | 52 | 78 | 104 | 130 | |
31 | 33 | 6 | 30 | 56 | 82 | 108 | 134 | |
32 | 33 | 6 | 34 | 60 | 86 | 112 | 138 | |
33 | 33 | 6 | 30 | 58 | 86 | 114 | 142 | |
34 | 33 | 6 | 34 | 62 | 90 | 118 | 146 | |
35 | 46 | 6 | 30 | 54 | 78 | 102 | 126 | 150 |
36 | 46 | 6 | 24 | 50 | 76 | 102 | 128 | 154 |
37 | 46 | 6 | 28 | 54 | 80 | 106 | 132 | 158 |
38 | 46 | 6 | 32 | 58 | 84 | 110 | 136 | 162 |
39 | 46 | 6 | 26 | 54 | 82 | 110 | 138 | 166 |
40 | 46 | 6 | 30 | 58 | 86 | 114 | 142 | 170 |
Например, для символа версии 7 в таблице E.1 указаны значения 6, 22 и 38. Поэтому направляющие шаблоны должны быть расположены на позициях (строка, столбец) (6, 22), (22, 6), (22, 22), (22, 38), (38, 22), (38,38). Следует обратить внимание, что координаты (6, 6), (6, 38), (38,6) заняты шаблонами поиска и поэтому не используются для направляющих шаблонов.
(обязательное)
Идентификатор символики, присвоенный QR Code в соответствии с ИСО/МЭК 15424, который должен быть добавлен как преамбула к декодированным данным соответственно запрограммированными декодерами:
]Qm,
где: ] - флаг идентификатора символики (знак набора ASCII с десятичным значением 93);
Q - знак кода для символики QR Code;
m - знак-модификатор, соответствующий одному из значений, приведенных в таблице F.1.
Для символов Micro QR Code значение m всегда должно быть равно 1.
Таблица F.1
Варианты применения идентификатора
символики и значения знака-модификатора
Значение знака-модификатора | Вариант применения |
0 | Символ QR Code Model 1 (в соответствии с AIM ITS 97-001) |
1 | Символ QR Code, протокол ECI не используется |
2 | Символ QR Code, протокол ECI используется |
3 | Символ QR Code, протокол ECI не используется, FNC1 представлен в первой позиции |
4 | Символ QR Code, протокол ECI используется, FNC1 представлен в первой позиции |
5 | Символ QR Code, протокол ECI не используется, FNC1 представлен во второй позиции |
6 | Символ QR Code, протокол ECI используется, FNC1 представлен во второй позиции |
Для знака-модификатора m допустимыми значениями являются 0, 1, 2, 3, 4, 5, 6.
(обязательное)
АСПЕКТЫ, СВЯЗАННЫЕ С ОСОБЕННОСТЯМИ СИМВОЛИКИ
G.1 Общие положения
Из-за различий в структурах символики и рекомендуемых алгоритмах декодирования влияние некоторых параметров на эффективность считывания символов может варьироваться. Применение ИСО/МЭК 15415 обеспечивает для спецификаций символик оценку дополнительных параметров, связанных с особенностями символики. В настоящем приложении приведена методика оценки повреждения фиксированных шаблонов и дополнительных параметров (информации о версии и информации о формате), которую следует использовать при применении ИСО/МЭК 15415 к символике QR Code.
G.2 Повреждение фиксированных шаблонов
G.2.1 Параметры, подлежащие оценке
G.2.1.1 Символы QR Code
Параметрами, подлежащими оценке, являются следующие:
- Три угловых сегмента, каждый из которых включает в себя:
- шаблон поиска 7 x 7;
- шаблон-разделитель шириной 1X вокруг двух внутренних сторон шаблонов поиска;
- часть свободной зоны шириной не менее 4 модулей (или более, в зависимости от применения) длиной 15 модулей вдоль двух других сторон шаблонов поиска.
- Два шаблона синхронизации, состоящие из чередующихся темных и светлых модулей, проходящих между внутренними углами шаблонов поиска.
- Направляющие шаблоны 5 x 5 (если присутствуют в символах Model 2 версии 2 или более).
Перечисленные выше параметры должны быть оценены как следующие шесть сегментов:
- три угловых сегмента (шаблон поиска со связанным с ним разделителем и частью свободной зоны) (сегменты A1, A2 и A3 соответственно);
- два шаблона синхронизации (сегменты B1 и B2 соответственно);
- одиночный сегмент, содержащий все направляющие шаблоны (сегмент C).
Там, где шаблон синхронизации пересекается с направляющим шаблоном, пять модулей, совпадающих с направляющим, следует оценивать как принадлежащие как шаблону синхронизации, так и к направляющему шаблону.
Например, в символе версии 7 (45 x 45 модулей) каждый сегмент A содержит 168 модулей; каждый сегмент B имеет 29 модулей в длину; сегмент C занимает в общей сложности 150 модулей (т.е. 6 x 25).
Данные сегменты для символа версии 7 приведены на рисунке G.1. A1, A2 и A3 указывают на три угловых сегмента; B1 и B2 указывают на два сегмента шаблонов синхронизации; C указывает на единственный сегмент C (объединяющий шесть направляющих шаблонов).
Примечание - Для символа QR Code ширина свободной зоны должна составлять 4X. На рисунке G.1 указаны области, которые должны быть проверены при оценке качества печати фиксированного шаблона. Остальные области свободных зон не проверяют.
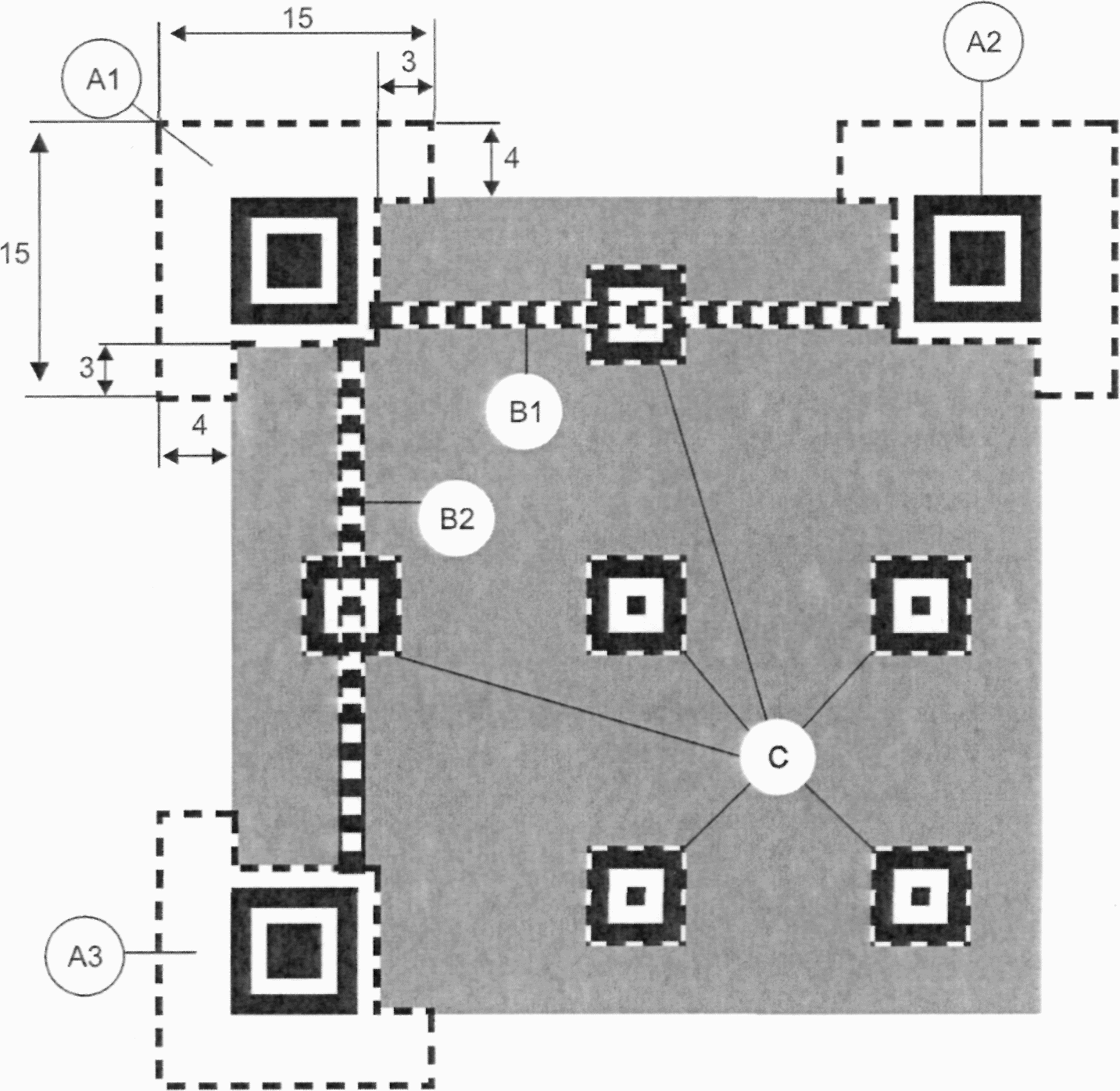
G.2.1.2 Символы Micro QR Code
Параметрами, подлежащими оценке, являются следующие:
- Угловой сегмент, включающий в себя:
- шаблон поиска;
- шаблон-разделитель шириной 1X вокруг двух внутренних сторон шаблона поиска;
- часть свободной зоны шириной не менее двух модулей (или более, в зависимости от применения) длиной 11 модулей вдоль двух других сторон шаблонов поиска.
- Два шаблона синхронизации, состоящие из чередующихся темных и светлых модулей, проходящих вдоль верхней и левой стороны символа, начинающихся от шаблона поиска.
Перечисленные выше параметры должны быть оценены как следующие три сегмента:
- угловой сегмент (шаблон поиска со связанными с ним разделителями и частью свободной зоны) (сегмент A), занимающий 104 модуля;
- два шаблона синхронизации (сегменты B1 и B2 соответственно).
Например, в символе версии M4 (17 x 17 модулей), каждый сегмент B имеет длину 9 модулей.
Данные сегменты для символа версии M4 представлены на рисунке G.2. Обозначение A указывает на угловой сегмент, B1 и B2 - на два сегмента шаблонов синхронизации.
Примечание - Для символа Micro QR Code ширина свободной зоны должна составлять 2X. На рисунке G.2 указаны области, которые подлежат проверке при оценке качества печати фиксированных шаблонов. Остальные области свободных зон не проверяют.
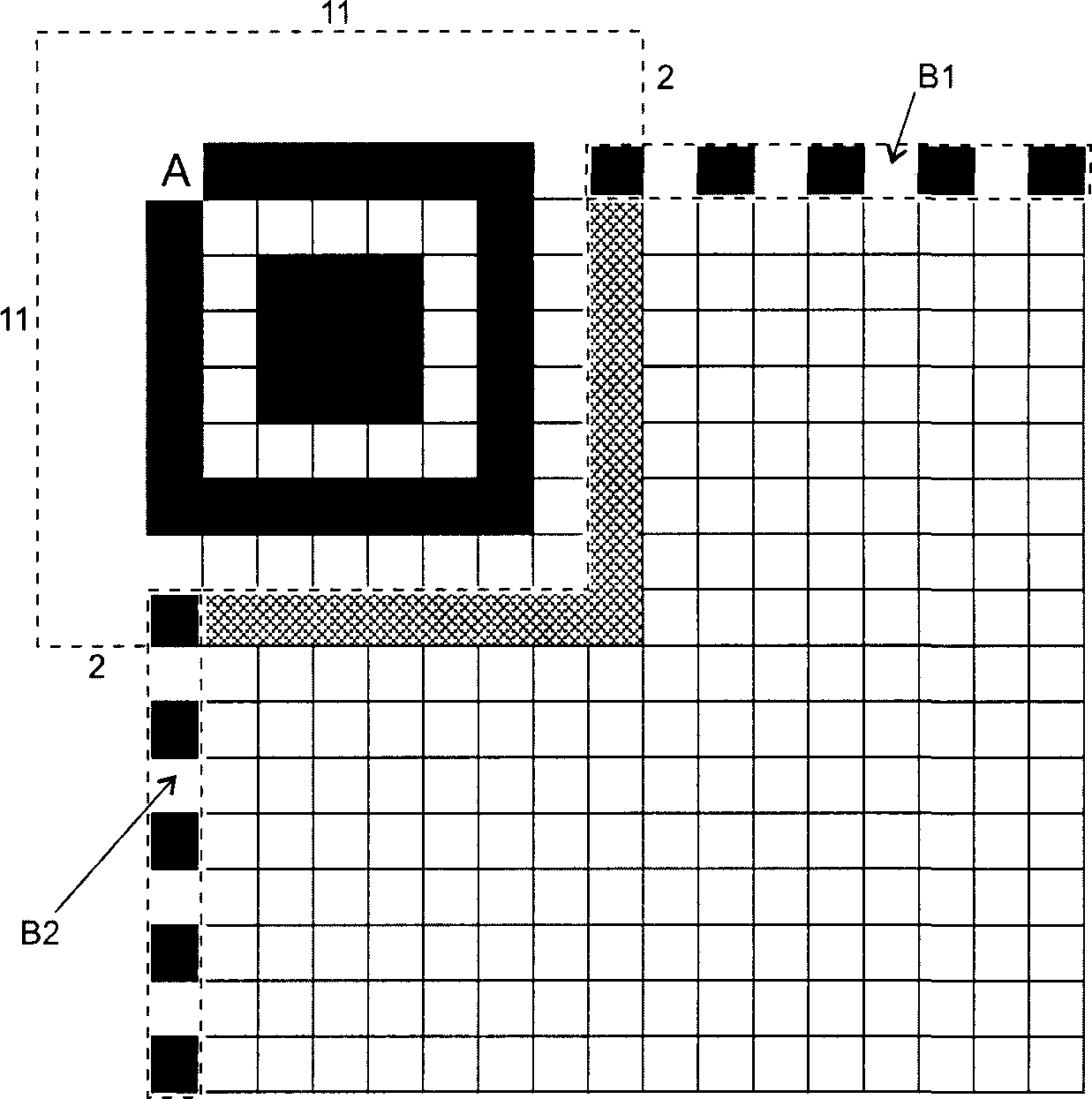
Рисунок G.2 - Сегменты фиксированных шаблонов Micro QR Code
G.2.2 Оценка повреждения фиксированных шаблонов
Повреждения каждого сегмента следует оценивать на основе параметра модуляции отдельных модулей, из которых состоят эти сегменты.
Оценку каждого сегмента проводят следующим образом:
a) На изображении символа (коэффициент отражения каждого пикселя должен быть выражен в уровнях градации серого) для каждого модуля определяют класс модуляции по ISO/IEC 15415. Так как уже известно, какой модуль следует считать темным, а какой светлым, то любой модуль, который должен быть темным, но коэффициент отражения которого выше глобального порога, а также любой модуль, который должен быть светлым, но коэффициент отражения которого менее глобального порога, должен иметь класс модуляции 0.
b) Для каждого класса модуляции предполагают, что все модули, которые не соответствуют этому или более высокому классу, являются поврежденными и им присваивают условный класс повреждения на основе пороговых значений классов, приведенных в таблице G.1. Выбирают меньший из классов модуляции и условного класса повреждения. Условный класс повреждения определяют следующим образом:
1) для каждого сегмента A1, A2 и A3, или сегмента A для Micro QR Code, подсчитывают число поврежденных модулей;
2) для сегментов B1 и B2 подсчитывают число поврежденных модулей. Представляют это число в процентах общего числа модулей в сегменте;
3) для сегментов B1 и B2 берут группы из пяти смежных модулей и, продвигаясь с шагом один модуль вдоль сегмента, проверяют, что в пределах каждой группы смежных модулей присутствует не более двух поврежденных модулей; если это не так, соответствующему сегменту присваивают класс 0. Эту проверку не применяют к символам Micro QR Code;
4) для сегмента C (только для символов QR Code) подсчитывают число направляющих шаблонов, содержащих поврежденные модули. Выражают это число в процентах от общего числа направляющих шаблонов в символе;
5) на основе пороговых значений классов, приведенных в таблице G.1, присваивают условный класс повреждения каждому сегменту.
c) Класс повреждения фиксированных шаблонов для сегмента должен соответствовать самому высокому полученному классу из всех классов модуляции.
Класс повреждения фиксированных шаблонов для символа должен быть меньшим классом сегментов.
Таблица G.1
шаблонов QR Code
Сегменты A1, A2 и A3 (QR Code); сегмент A (Micro QR Code) | Сегменты B1 и B2 (QR Code) | Сегменты B1 и B2 (Micro QR Code) | Сегмент C (QR Code) | Класс |
Число поврежденных модулей | Поврежденные модули от общего числа модулей, % | Поврежденные модули от общего числа модулей, % | Поврежденные модули от общего числа модулей, % | |
0 | 0 | 0 | 0 | 4 |
1 | <= 7 | <= 10 | 3 | |
2 | <= 11 | <= 30 | <= 20 | 2 |
3 | <= 14 | <= 30 | 1 | |
>= 4 | > 14 | > 30 | > 30 | 0 |
G.3 Оценка по классам дополнительных параметров
G.3.1 Общие положения
Символы QR Code содержат двойной набор модулей, представляющих информацию, которая определяет формат символа, а символы версии от 7 до 40 также содержат двойной набор модулей, представляющих информацию, которая определяет размер символа. Символы Micro QR Code содержат единственный набор модулей, представляющих информацию, которая определяет формат символа. Для этих данных требуется, чтобы повреждения были обнаружены на ранней стадии процесса декодирования, и если эта информация не может быть декодирована, остаток от символа в свою очередь также не может быть декодирован. По этой причине информацию о формате и блоки модуля информации о версии оценивают отдельно (способом, аналогичным оценке повреждения фиксированных шаблонов), и их классы включают в определение полного класса символа.
G.3.2 Оценка по классам информации о формате
Для каждого блока информации о формате вычисляют класс блока, используя следующую методику.
a) На изображении символа (коэффициент отражения каждого пикселя должен быть выражен в уровнях градации серого) для каждого модуля определяют класс модуляции по ИСО/МЭК 15415. Поскольку действительное значение коэффициента отражения каждого модуля блока информации о формате становится известным только после успешного декодирования блока, то любой модуль, который должен быть темным, но коэффициент отражения которого выше глобального порога, а также любой модуль, который должен быть светлым, но коэффициент отражения которого ниже глобального порога, приводит к классу модуляции 0 <1>.
--------------------------------
<1> Если блок информации о формате не может быть декодирован, класс всего блока должен соответствовать 0 и этап b не выполняют.
b) Для каждого класса модуляции:
1) предполагают, что все модули, которые не соответствуют этому или более высокому классу, являются поврежденными модулями, и им присваивают условный класс повреждения блока на основе пороговых значений классов, приведенных в таблице G.2.
Таблица G.2
Условный класс информации о формате
Число поврежденных модулей | Класс |
0 | 4 |
1 | 3 |
2 | 2 |
3 | 1 |
>= 4 | 0 |
2) выбирают меньший из классов модуляции и условного класса повреждения согласно таблице G.3;
3) класс для блока получают как лучший условный класс согласно таблице G.3.
Таблица G.3
Пример оценки для блока информации о формате
Класс модуляции | Условный класс | Меньший из классов |
4 | 2 | 2 |
3 | 2 | 2 |
2 | 3 | 2 |
1 | 3 | 1 |
0 | 4 | 0 |
Выбранный (наилучший) класс -> | 2 |
c) Класс информации о формате:
1) для символов QR Code должен быть средним значением классов двух блоков информации о формате, если необходимо, округленным до ближайшего большего целого;
2) для символов Micro QR Code класс должен быть равен классу, полученному на этапе 2 c).
G.3.3 Оценка по классам информации о версии (для символов QR Code)
Для каждого блока информации о версии вычисляют класс блока, используя следующую методику.
a) На изображении символа (коэффициент отражения каждого пикселя должен быть выражен в уровнях градации серого) для каждого модуля определяют класс модуляции по ИСО/МЭК 15415. Поскольку действительное значение коэффициента отражения каждого модуля блока информации о версии становится известным только после успешного декодирования блока, то любой модуль, который должен быть темным, но коэффициент отражения которого выше глобального порога, а также любой модуль, который должен быть светлым, но коэффициент отражения которого ниже глобального порога, приводит к классу модуляции 0. Если блок информации о версии не может быть декодирован, класс всего блока должен быть 0 <1>.
--------------------------------
<1> В этом случае этап b) не выполняют.
b) Для каждого класса модуляции:
1) предполагают, что все модули, которые не соответствуют этому или более высокому классу, являются поврежденными модулями, и им присваивают условный класс повреждения блока на основе пороговых значений классов, приведенных в таблице G.4.
Таблица G.4
Условный класс информации о версии
Число поврежденных модулей | Класс |
0 | 4 |
1 | 3 |
2 | 2 |
3 | 1 |
>= 4 | 0 |
2) выбирают меньший из класса модуляции и условного класса повреждения по таблице G.5;
3) класс для блока определяют как лучший условный класс по таблице G.5.
Таблица G.5
Пример оценки для блока информации о версии
Класс модуляции | Условный класс | Меньший класс |
4 | 2 | 2 |
3 | 2 | 2 |
2 | 3 | 2 |
1 | 3 | 1 |
0 | 4 | 0 |
Выбранный (наилучший) класс -> | 2 |
c) Класс информации о формате должен быть средним значением двух классов блоков информации о версии, если необходимо, округленным до ближайшего большего целого числа.
G.4 Класс сканирования
Класс сканирования должен быть меньшим из классов типовых параметров, вычисленных по ИСО/МЭК 15415, класса повреждения фиксированных шаблонов, класса информации о формате и (если применимо) класса информации о версии, вычисленных на основе настоящего приложения.
(справочное)
Таблица H.1

Окончание таблицы H.1
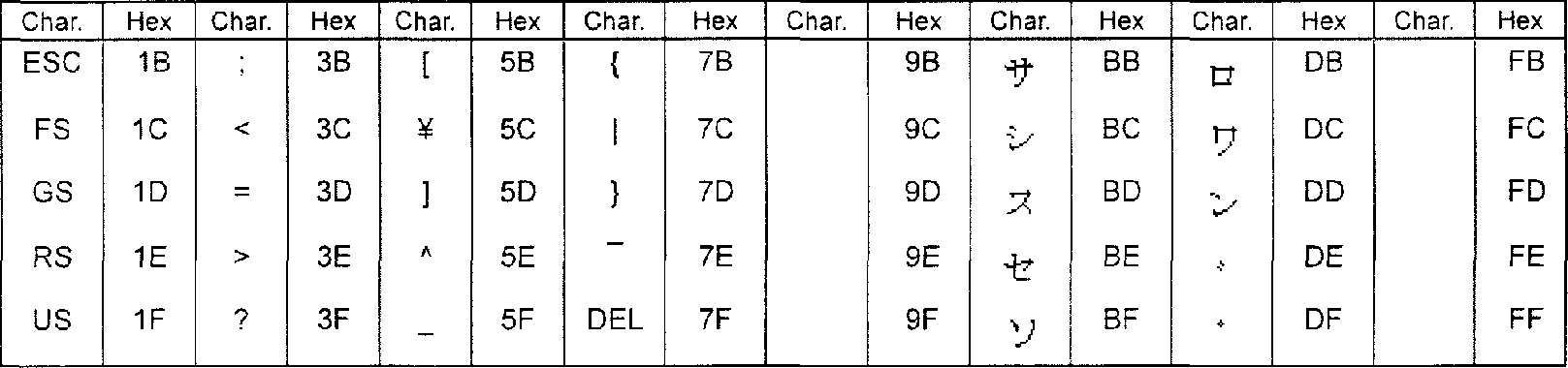
На рисунке H.1 представлена область матрицы 256 x 256, занятая двухбайтовыми знаками Shift JIS.
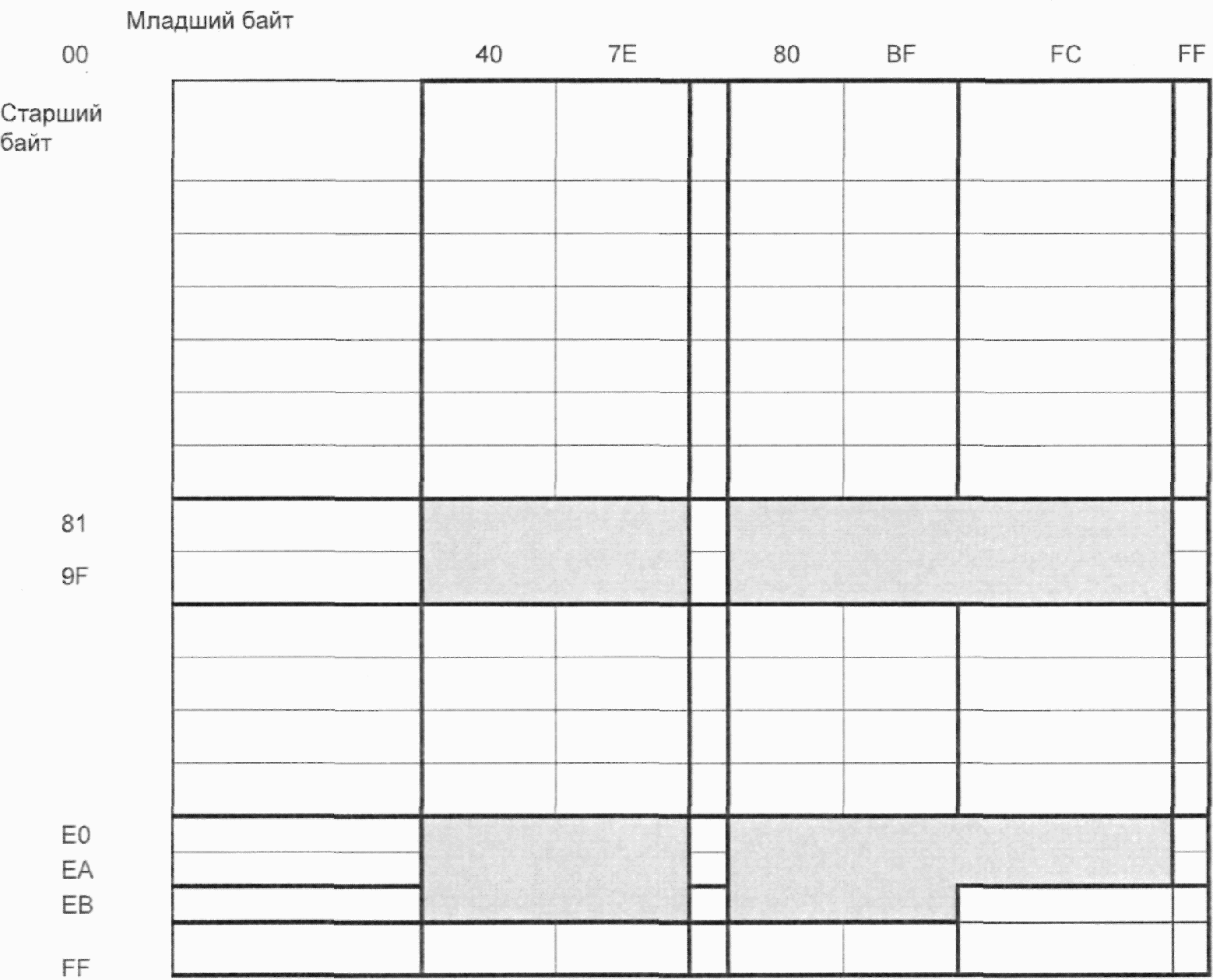
Согласно JIS X0208:1997 начальный и конечный байты заштрихованной области предназначены для знаков Shift JIS кандзи. Любые пары байтов из этих диапазонов могут быть закодированы с использованием схемы уплотнения режима кандзи.
(справочное)
ПРИМЕРЫ КОДИРОВАНИЯ СИМВОЛОВ
I.1 Общие положения
В настоящем приложении приведено кодирование строки данных 01234567 в символы QR Code и Micro QR Code.
I.2 Кодирование символа QR Code
Указанная строка данных будет закодирована в символ версии 1-M с использованием цифрового режима, приведенного в 7.4.3.
Этап 1: Кодирование данных
- Разбивают строку на группы по три цифры и преобразуют каждую группу из десятичного числа в 7-битовый двоичный эквивалент:
- 012 -> 0000001100
- 345 -> 0101011001
- 67 -> 1000011
- Преобразуют индикатор числа знаков в двоичный эквивалент (10 битов для версии 1-M).
Индикатор числа знаков (8) = 0000001000
- Добавляют индикатор цифрового режима (0001), индикатор числа знаков (0000001000), двоичные данные и ограничитель (0000)
0001 0000001000 0000001100 0101011001 1000011 0000
- Делят на 8-битовые кодовые слова, добавляют биты-заполнители (для наглядности подчеркнуты), поскольку последнее кодовое слово заполнено только на 5 битов:
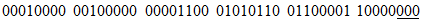
- Добавляют кодовые слова-заполнители для заполнения емкости символа (для версии 1-M, 16 кодовых слов данных, требуется 10 кодовых слов-заполнителей (для наглядности подчеркнуты)); в результате получают:
00010000 00100000 00001100 01010110 01100001 10000000 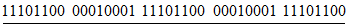
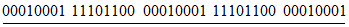
Этап 2: Генерация кодовых слов исправления ошибок
Используя алгоритм Рида-Соломона для генерации требуемого числа кодовых слов исправления ошибок (10 слов для версии 1-M), которые (для наглядности подчеркнуты) добавляют к двоичному потоку, получают:
00010000 00100000 00001100 01010110 01100001 10000000 11101100 00010001 11101100 00010001 11101100 00010001 11101100 00010001 11101100 00010001 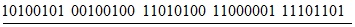
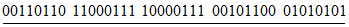
Этап 3: Размещение модулей в матрице символа
Поскольку для символа версии 1-M используется только один блок исправления ошибок, перемешивание не требуется. Шаблоны поиска, разделители и шаблоны синхронизации размещают в пустой матрице 21 x 21 и модули в позиции для информации о формате временно оставляют пустыми. Кодовые слова, полученные на этапе 2, размещают в матрице в соответствии с 7.7.3, в результате получают символ, приведенный на рисунке I.1.

Рисунок I.1 - Размещение модулей данных в символе
до маскирования данных
Этап 4: Выбор шаблона для маски данных
Применяют шаблоны маски данных согласно 7.8.2 по очереди и оценивают результаты по 7.8.3. Для данного символа рекомендуется выбрать шаблон маски с обозначением 010.
Этап 5: Информация о формате
Уровень исправления ошибок - M, что в двоичном виде представляют 00, и указатель шаблона маски равен 010. Следовательно, по 7.9.1 получают биты информации о формате 00 010.
Вычисляют биты исправления ошибок по коду BCH и получают 1001101110 как битовую последовательность для добавления к данным; результат дополнения:
000101001101110 как немаскированная информация о формате.
Применяют к этому двоичному потоку операцию XOR с маской 101010000010010:
000101001101110 (исходный двоичный поток);
101010000010010 (маска);
101111001111100 (информация о формате, подлежащая размещению в символе).
Этап 6: Заключительное формирование символа
Применяют выбранный шаблон маски данных к области кодирования символа согласно 7.8, и добавляют модули информации о формате в позиции, зарезервированные на этапе 3. В результате получают завершенный символ, показанный на рисунке I.2.
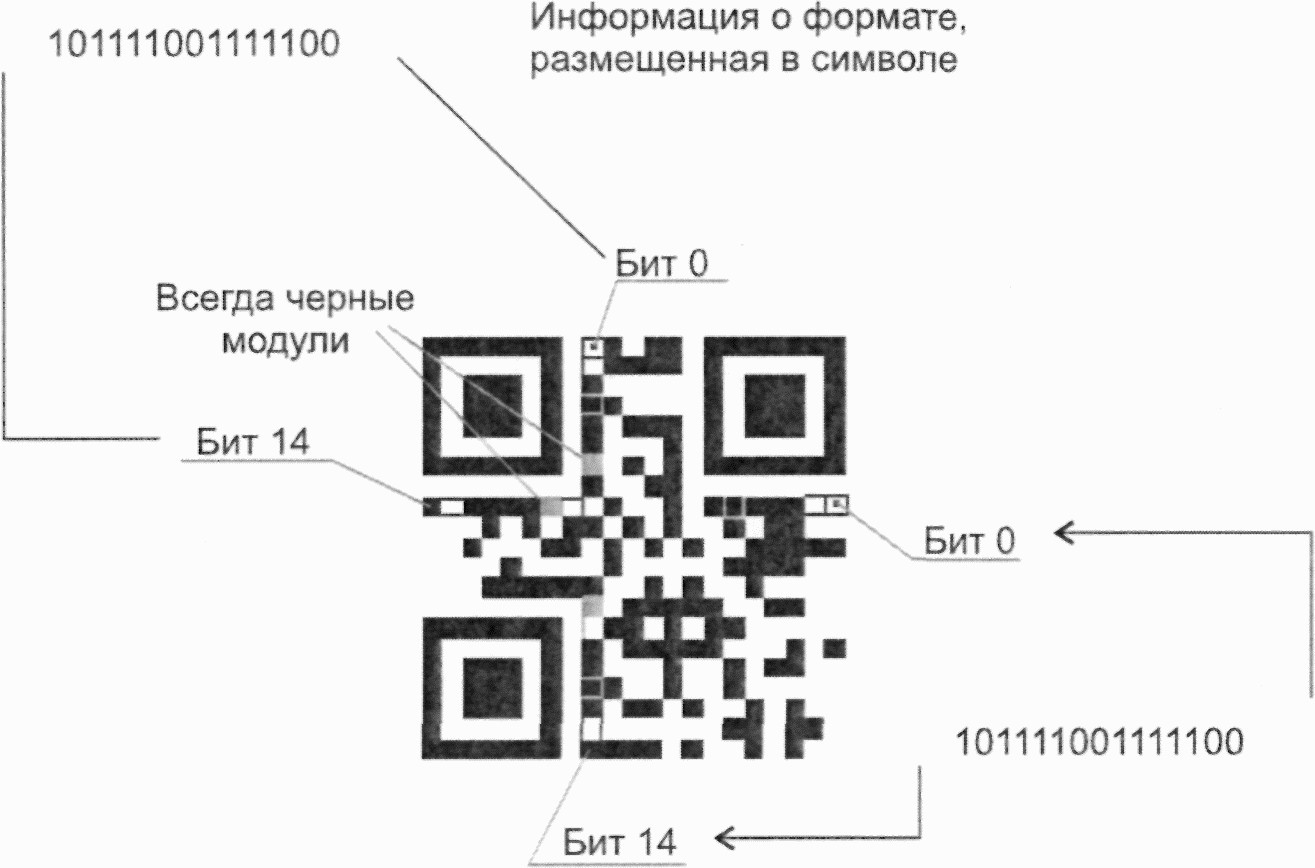
Рисунок I.2 - Окончательный вид символа версии 1-M,
кодирующего 01234567
I.3 Кодирование символа Micro QR Code
Строка данных 01234567 подлежит кодированию в символе версии M2 с уровнем исправления ошибок L с использованием числового режима кодирования по 7.4.3.
Этап 1: Кодирование данных
- Разбивают строку на группы по три цифры и преобразуют каждую группу из десятичного числа в 7-битовый двоичный эквивалент:
- 012 -> 0000001100
- 345 -> 0101011001
- 67 -> 1000011;
- индикатор числового режима для версии M2 - 0;
- число знаков - 8; преобразуют индикатор числа знаков в двоичный эквивалент (4 бита для версии M2-L):
Индикатор числа знаков (8) = 1000
- ограничитель для версии M2, включающий в себя 5 нулевых битов - 00000;
- добавляют индикатор цифрового режима (0), индикатор числа знаков (1000), двоичные данные и ограничитель (00000)
0 1000 0000001100 0101011001 1000011 00000;
- делят на 8-битовые кодовые слова, добавляя 3 бита-заполнителя (для наглядности подчеркнуты), поскольку последнее кодовое слово заполнено только 5 битами
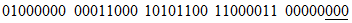 ;
;- кодовые слова-заполнители не требуются для заполнения емкости символа (для версии M2-L, используется 5 кодовых слов данных).
Этап 2: Генерация кодовых слов исправления ошибок
Используя алгоритм Рида-Соломона для генерации требуемого числа кодовых слов исправления ошибок (5 слов для версии M2-L), которые (для наглядности подчеркнуты) добавляют к двоичному потоку, получают:
01000000 00011000 10101100 11000011 00000000 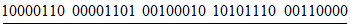
Шаблон поиска и шаблоны синхронизации размещают в пустой матрице 13 x 13 и модули в позиции для информации о формате временно оставляют пустыми. Кодовые слова, полученные на этапе 2, размещают в матрице в соответствии с 7.7.3, в результате получают символ, приведенный на рисунке I.3.

Рисунок I.3 - Размещение модулей данных в символе
до маскирования данных
Этап 4: Выбор шаблона маски данных
Применяют шаблоны маски данных согласно 7.8.2 по очереди и оценивают результаты по 7.8.3. Для данного символа рекомендуется использовать шаблон маски данных с обозначением 01. Применяют выбранный шаблон маски данных к области кодирования в матрице согласно 7.8.
Этап 5: Подготовка информации о формате
Для символа версии M2-L номер версии равен 1, что в двоичном виде представляют как 001, и шаблон маски данных 01. В результате получают биты данных в информации о формате 001 01.
Вычисляют биты исправления ошибок по коду ВСН и получают 0011011100 как битовую последовательность для добавления к данным; результат дополнения:
001010011011100 как немаскированная информация о формате.
Применяют к этому двоичному потоку операцию XOR с маской 100010001000101:
- 001010011011100 (исходный двоичный поток);
- 100010001000101 (маска);
- 101000010011001 (информация о формате, которая будет размещена в символе).
Этап 6: Заключительное формирование символа
Добавляют модули информации о формате в позиции, зарезервированные на этапе 3. В результате получают завершенный символ, приведенный на рисунке I.4.

Рисунок I.4 - Окончательный вид символа версии M2-L,
кодирующего 01234567
(справочное)
J.1 Общие положения
В соответствии с настоящим стандартом в символике QR Code предусмотрены различные режимы кодирования, каждый из которых отличается по числу битов, требуемых для представления конкретной строки данных. Так как присутствует перекрытие между наборами знаков для каждого режима - например, числовые данные могут быть закодированы в числовом, алфавитно-цифровом и байтовом режимах, а латинские алфавитно-цифровые данные могут быть закодированы в алфавитно-цифровом и байтовом режимах, программное обеспечение генерации символов должно выбрать наиболее подходящие режимы, чтобы закодировать знаки данных, которые могут появиться более, чем в одном режиме.
Такой же выбор может быть между применением символов QR Code и Micro QR Code.
Выбор режима должен быть сделан в самом начале, но затем режим может быть изменен для части потока данных.
Может быть использовано множество альтернативных подходов для уменьшения длины двоичного потока. Алгоритм должен не только учитывать непосредственную последовательность знаков, но также и предвидеть следующую последовательность данных ввиду избыточности, требуемой для переключения режимов. Термин "исключительный поднабор" использован в настоящем приложении для обозначения "набора знаков в пределах набора знаков режима, которые не пересекаются с более ограниченным набором знаков другого режима", как указано далее и в таблице J.1.
Таблица J.1
Исключительные поднаборы для режимов кодирования QR Code
Исключительный поднабор | Байтовые (шестнадцатеричные) значения |
числовой | От 30 до 39 |
алфавитно-цифровой | 20, 24, 25, 2A, 2B, от 2D до 2F, 3A, и от 41 до 5A |
байтовый | От 00 до 1F, от 21 до 23, от 26 до 29, 2C, от 3B до 40, от 5B до FF (исключая зарезервированные значения от 80 до 9F и от E0 до FF) |
знаки кандзи | Двухбайтовые значения из диапазона, определенного в приложении H |
Исключительный поднабор для числового режима - это множество знаков с шестнадцатеричными значениями от 30 до 39 (цифры от 0 до 9).
Исключительный поднабор для алфавитно-цифрового режима - это множество знаков с шестнадцатеричными значениями 20, 24, 25, 2A, 2B, от 2D до 2F, 3A и от 41 до 5A с графическими представлениями {латинские буквы a - z, A - Z, пробел, $ % * + - . / :}.
Примечание 1 - Этот поднабор не включает в себя цифры.
Исключительный поднабор для байтового режима - это знаки с шестнадцатеричными значениями от 00 до FF, за исключением 20, 24, 25, 2A, 2B, от 2D до 3A и от 41 до 5A.
Примечание 2 - Исключенные значения содержат исключительные поднаборы знаков числового и алфавитно-цифрового режимов.
Эффективность уплотнения, приведенную в 7.4.3 - 7.4.6, необходимо интерпретировать с осторожностью. Лучшая схема для данного набора знаков данных может быть не та, у которой наименьшее число битов на знак данных. Если требуется самая высокая степень уплотнения, следует учитывать число дополнительных битов, требуемых для изменения режима (дополнительный индикатор режима и индикатор числа знаков). Следует отметить, что даже если число кодовых слов является минимальным, поток кодовых слов должен быть увеличен, чтобы заполнить емкость символа. Процесс заполнения проводят с использованием знаков-заполнителей.
Для символов QR Code следующие рекомендации, основанные на одном из возможных для применения алгоритмов, формируют самый короткий двоичный поток для любых взятых входных данных.
Число знаков приведено в квадратных скобках, например [5, 7, 9] применительно к символам версий 1 - 9, 10 - 26 и 27 - 40 соответственно.
a) Выбирают начальный режим:
1) если исходный входной поток данных состоит только из знаков исключительного поднабора байтового набора знаков, выбирают байтовый режим;
2) если начальный входной байт является начальным байтом из исключительного поднабора набора знаков кандзи, а следующий байт - завершающий байт из исключительно поднабора набора знаков кандзи, И подпоследовательность данных состоит из алфавитно-цифрового или числового исключительного поднабора знаков, то выбирают режим кандзи, ИНАЧЕ, если подпоследовательность данных состоит из исключительного поднабора байтового набора знаков И последующие [5, 5, 6] пары байтов также принадлежат исключительному поднабору набора знаков кандзи, выбирают байтовый режим;
3) если исходный входной поток данных состоит из исключительного поднабора набора алфавитно-цифровых знаков И если их меньше [6 - 8] знаков, а следующий знак из байтового набора знаков ТОГДА, выбирают байтовый режим, ИНАЧЕ выбирают алфавитно-цифровой режим;
4) если исходные данные являются числовыми, И если их меньше чем [4, 4, 5] знаков, а следующий знак из исключительного поднабора байтового набора знаков, ТОГДА выбирают байтовый режим, ИНАЧЕ ЕСЛИ их меньше чем [7 - 9] знаков, а следующий знак из исключительного поднабора алфавитно-цифрового набора знаков, ТОГДА выбирают алфавитно-цифровой режим, ИНАЧЕ выбирают числовой режим.
b) При нахождении в байтовом режиме:
1) если последовательность по крайней мере [9, 12, 13] байтовых пар из исключительного поднабора набора знаков кандзи встречается перед большим количеством данных из исключительного поднабора набора байтовых знаков, то переходят в режим кандзи;
2) если последовательность по крайней мере [11, 15, 16] знаков из исключительного поднабора алфавитно-цифрового набора знаков встречается перед большей последовательностью данных из исключительного поднабора байтового набора знаков, то переходят в алфавитно-цифровой режим;
3) если последовательность по крайней мере [6, 8, 9] числовых знаков встречается перед большей последовательностью данных из исключительного поднабора байтового набора знаков, то переходят в числовой режим;
4) если последовательность по крайней мере [6 - 8] числовых знаков встречается перед большей последовательностью данных из исключительного поднабора набора алфавитно-цифровых знаков, то переходят в числовой режим.
c) При нахождении в алфавитно-цифровом режиме:
1) если встречается один или более знаков кандзи, то переходят в режим кандзи;
2) если встречается один или более знаков исключительного поднабора из байтового набора знаков, то переходят в байтовый режим;
3) если последовательность по крайней мере [13, 15, 17] числовых знаков встречается перед большей последовательностью данных из исключительного поднабора набора алфавитно-цифровых знаков, то переходят в числовой режим.
d) При нахождении в числовом режиме:
1) если встречается один или более знаков кандзи, то переходят в режим кандзи;
2) если встречается один или более знаков исключительного поднабора байтового набора знаков, то переходят в байтовый режим;
3) если встречается один или более знаков исключительного поднабора набора алфавитно-цифровых знаков, то переходят в алфавитно-цифровой режим.
J.3.1 Принципы оптимизации
Предположим, что данные, которые нужно закодировать, находятся в исключительных поднаборах не более чем двух режимов, и что все данные в каждом поднаборе сгруппированы вместе (например "123abcdef"), алгоритм определения самого короткого двоичного потока для данных Micro QR Code, может быть определен в таблице J.2. Эти принципы могут быть расширены для обеспечения работы при наличии более двух режимов, но следует принять во внимание, что результирующий двоичный поток будет соответствовать одному из доступных символов.
Поскольку низкие режимы используют меньшее число битов на знак, чем высокие режимы, следует учитывать, что избыточность в виде индикатора режима и индикатора числа знаков для изменения режима должна компенсироваться большей плотностью кодирования для более низкого режима. В таблице J.2 приведено минимальное число последовательных знаков в низком режиме, для которого достигают более короткого общего двоичного потока путем изменения режимов. При меньшем числе знаков кодирование всех данных в более высоком режиме приведет к более короткому двоичному потоку.
Таблица J.2
длины двоичного потока путем изменения режимов
Комбинация режимов | Символы версии M2 | Символы версии M3 | Символы версии M4 |
Числовой + алфавитно-цифровой | 3 цифры | 4 цифры | 5 цифр |
Числовой + байтовый (8 битовые байты) | Не применим | 2 цифры | 3 цифры |
Алфавитно-цифровой + байтовый | Не применим | 3 буквы и цифры | 4 буквы и цифры |
J.3.2 Емкость символов Micro QR Code
ИС МЕГАНОРМ: примечание. В официальном тексте документа, видимо, допущена опечатка: таблица J.3 отсутствует. |
На приведенных ниже рисунках J.1 - J.6, учитывающих данные таблицы J.3 и емкости различных версий символа, для каждой комбинации режимов представлены варианты, применимые для кодирования определенного объема данных в комбинациях режимов.
Заголовки столбцов и строк идентифицируют число знаков в каждом режиме. На данных рисунках приведены версии символа и уровни исправления ошибок без указания начальной буквы версии M; таким образом, например, 4Q относится к символу версии M4 с уровнем исправления ошибок Q. Для любой данной комбинации знаков и режимов, доступными версиями символа являются те, которые находятся на соответствующем пересечении строки и столбца и приведенные справа или ниже этого пересечения.
Например, строка данных "123456ABCDEFGH" состоит из шести числовых знаков и восьми знаков из алфавитно-цифрового набора знаков. На рисунке J.1 показано, что данные размещены или в символе версии M3-L (с общим числом битов 77, включая индикаторы режима и индикаторы числа знаков), или в символе версии M4-M, или символе версии M4-L (81 бит в любом случае). На варианты могут быть наложены ограничения в зависимости от доступного места или требуемого уровня исправления ошибок.
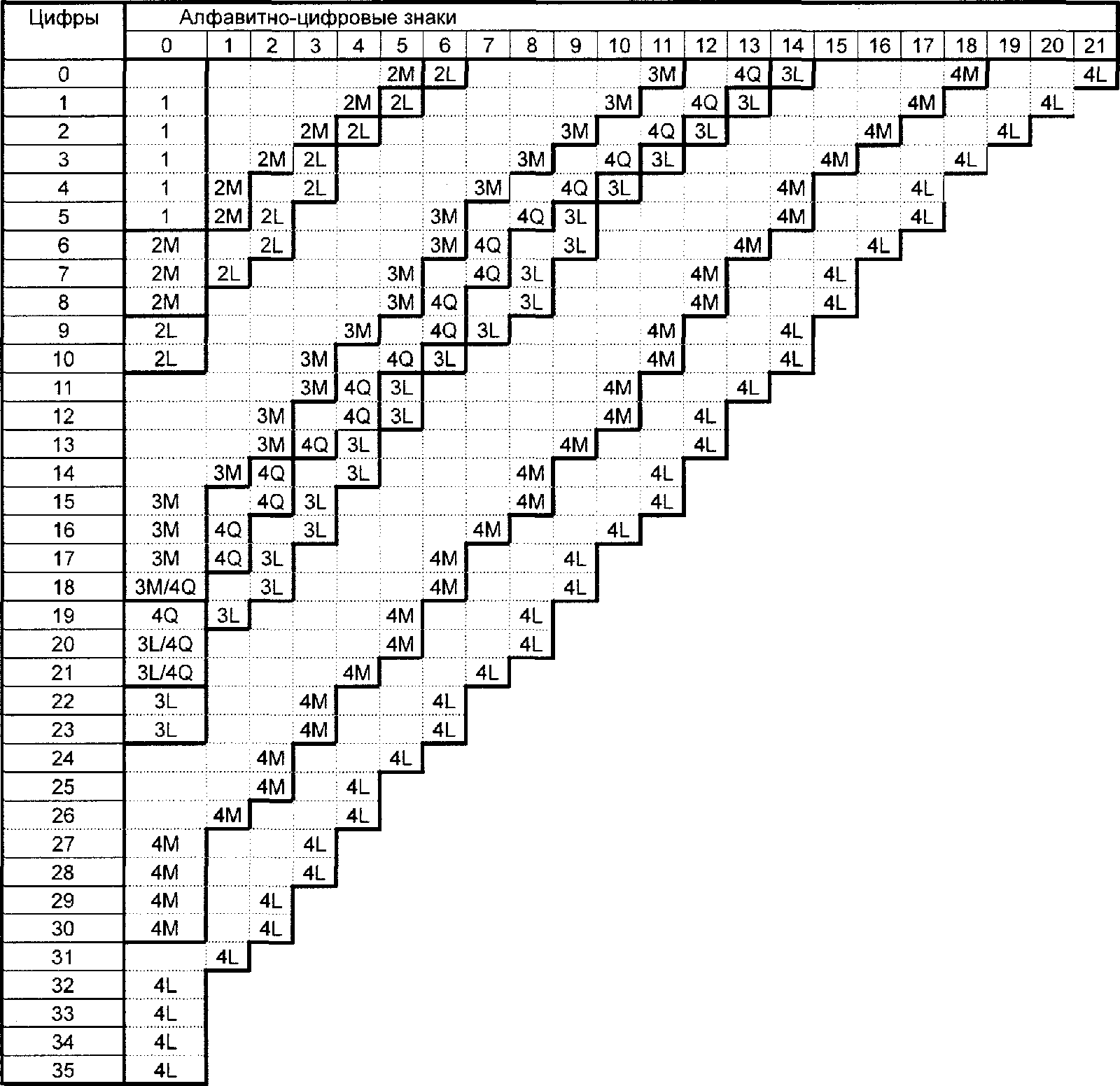
для данных - цифр и алфавитно-цифровых знаков
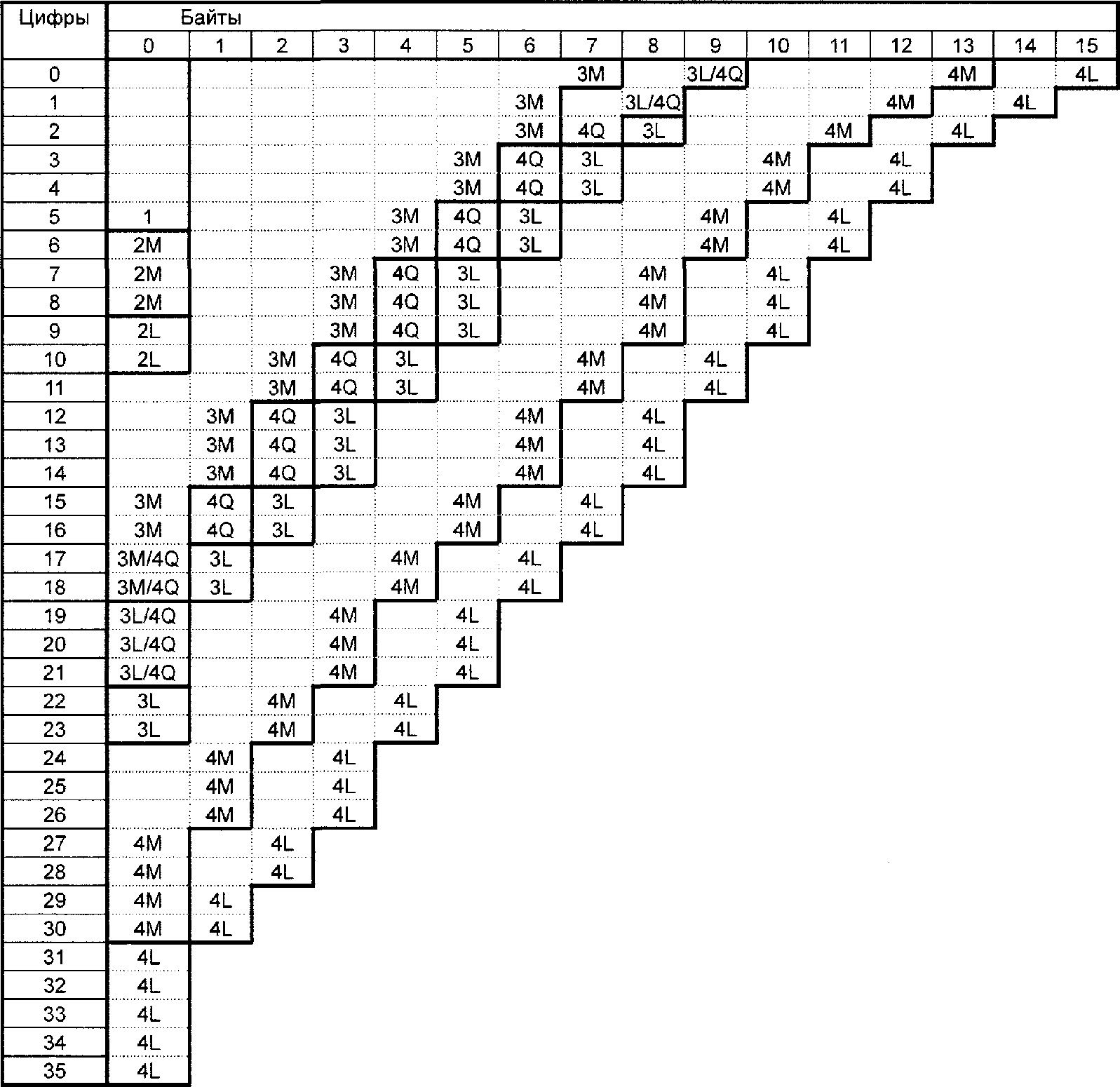
Рисунок J.2 - Емкости символов Micro QR Code
для данных - цифр и байтов
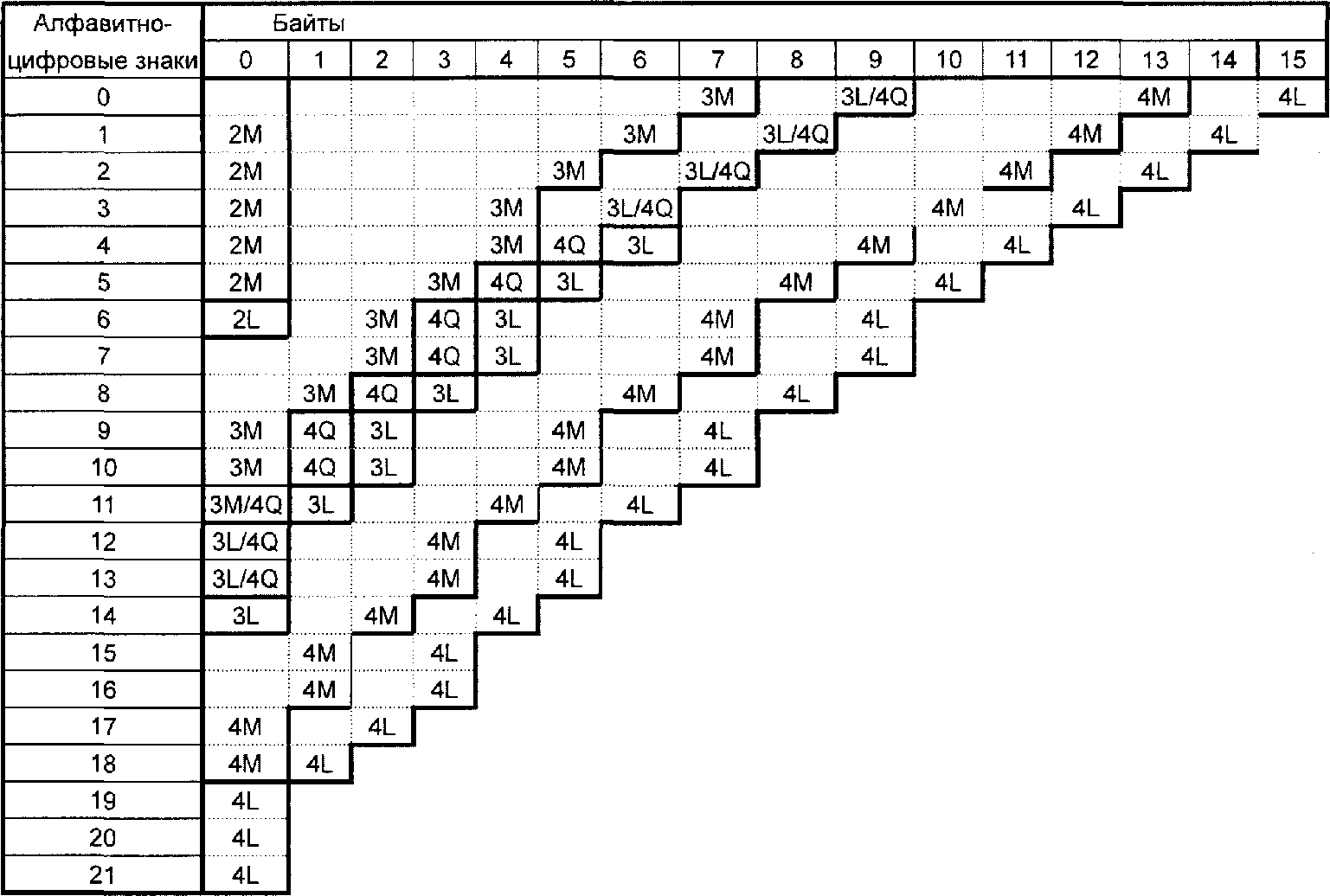
Рисунок J.3 - Емкости символов Micro QR Code
для данных - алфавитно-цифровых знаков и байтов
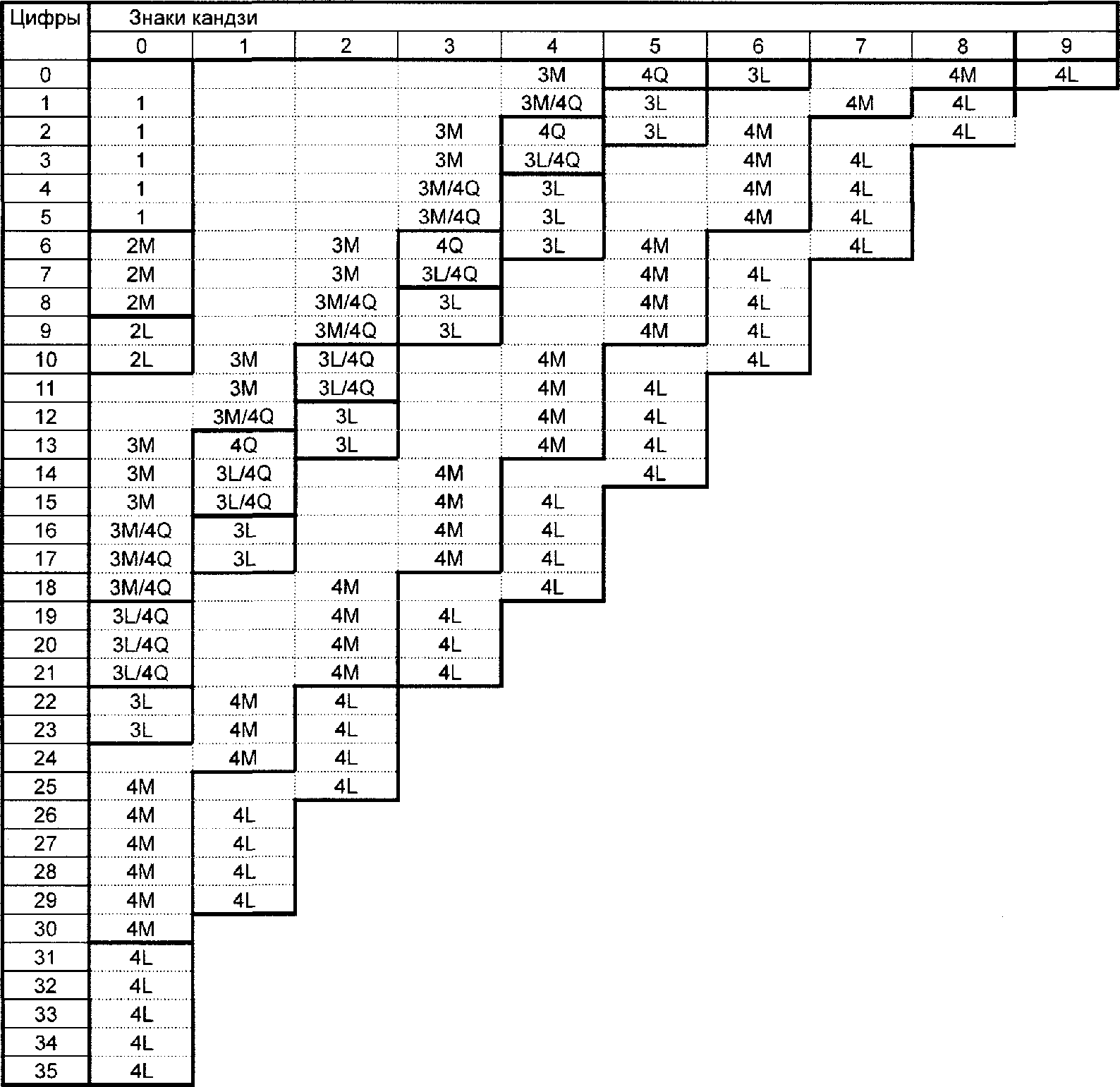
Рисунок J.4 - Емкости символов Micro QR Code
для данных - цифр и знаков кандзи
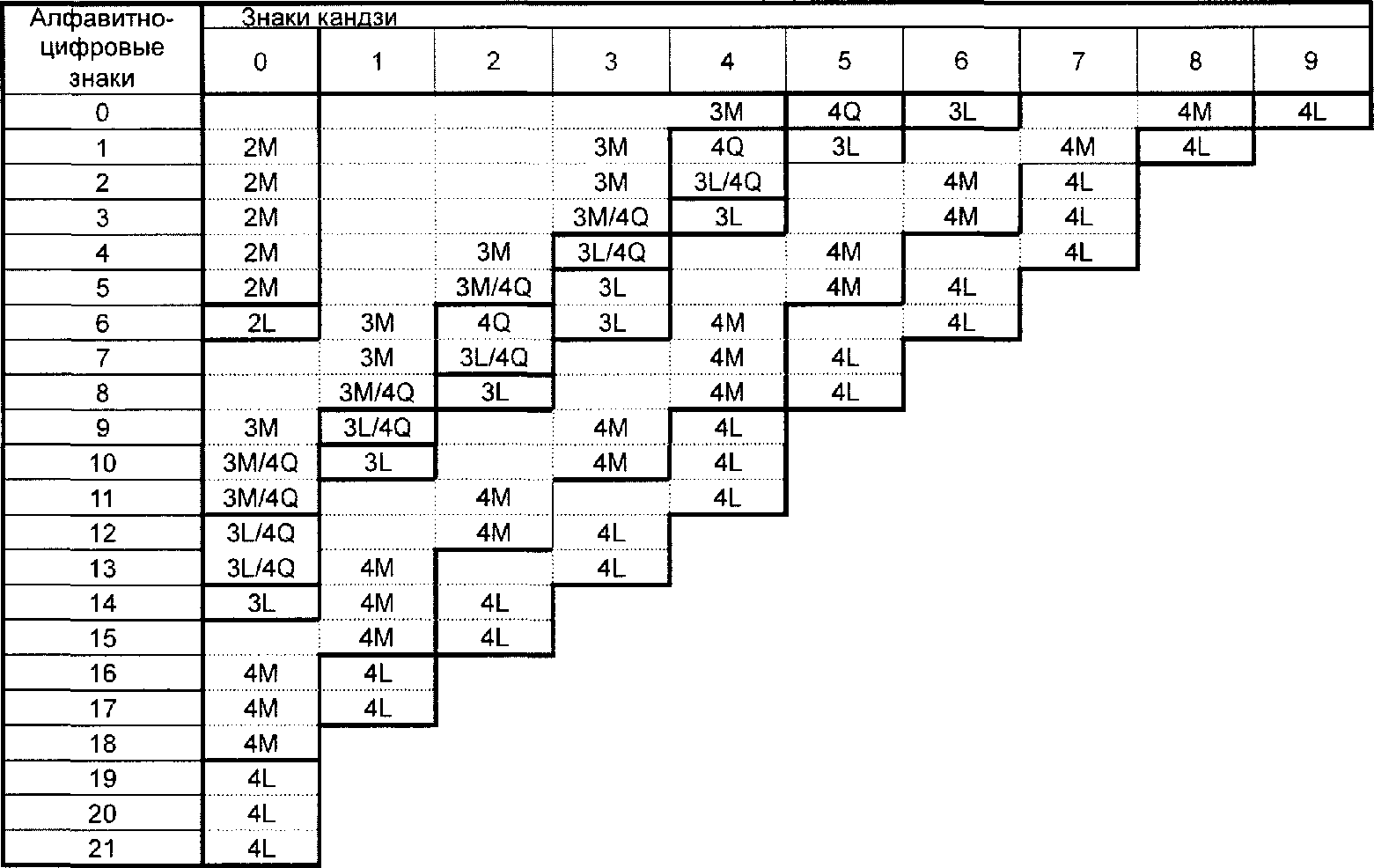
Рисунок J.5 - Емкости символов Micro QR Code
для данных - алфавитно-цифровых знаков
и знаков кандзи
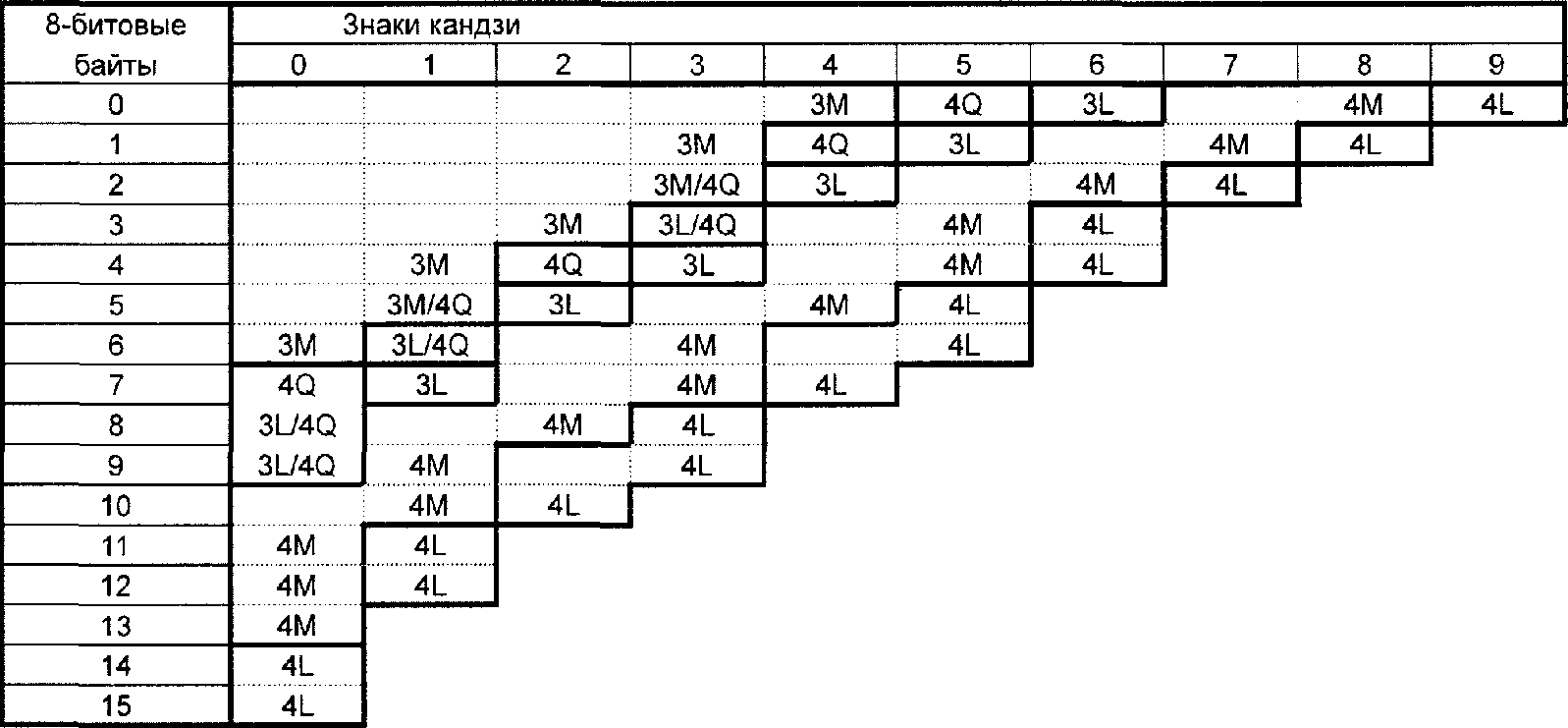
для данных - байтов и знаков кандзи
(справочное)
ПОЛЬЗОВАТЕЛЯМ ПО ПЕЧАТИ И СКАНИРОВАНИЮ СИМВОЛОВ QR CODE
K.1 Основные положения
Любое конкретное применение символики QR Code следует рассматривать как законченное системное решение. Все компоненты цепочки кодирования/декодирования символики (устройства маркирования поверхности или принтеры, этикетки, устройства считывания), используемые совместно, должны взаимодействовать друг с другом как система. Отказ в любом звене цепочки или несоответствие между ними может поставить под угрозу эффективность функционирования всей системы.
Хотя соответствие требованиям - единственный ключ к обеспечению успешной работы всей системы, следует принимать во внимание и другие соображения, которые также могут влиять на эффективность работы. Следующие рекомендации учитывают ряд факторов, которые необходимо иметь в виду при разработке спецификации или реализации систем на основе штрихового или матричного кода:
a) Следует выбирать плотность печати с допусками, которые могут быть обеспечены используемой технологией маркирования или печати. Необходимо обеспечить, чтобы размер модуля был равен целому числу размеров пикселей печатающей головки (в параллельном и перпендикулярном направлениях печати). Следует добиваться того, чтобы любое приращение (сокращение) размеров элементов при печати осуществлялось путем изменения цвета одинакового целого числа пикселей с темного на светлый (или наоборот со светлого на темный) на всех границах перехода с темного на светлый для отдельных модулей или групп смежных темных модулей таким образом, чтобы интервал между центрами модулей оставался постоянным, хотя видимое растровое представление индивидуального темного (или светлого) модуля может быть откорректировано в размере, соответствующем направлению компенсации.
b) Следует подбирать устройство считывания с разрешающей способностью, наиболее подходящей для плотности и качества печати символа, которая обеспечивает данная технология печати.
c) Должна быть обеспечена совместимость оптических свойств напечатанного символа с длиной волны источника излучения и приемного элемента сканера.
d) Следует проверять соответствие символа на этикетке в ее законченном виде или итоговой конфигурации упаковки. Наложение изображений, просвечивание, фигурные или неровные поверхности могут оказывать влияние на эффективность считывания символа.
Следует учитывать влияние зеркального отражения от глянцевых подложек символа. Сканирующие системы должны учитывать колебания в диффузном отражении между темными и светлыми областями символа. При некоторых углах сканирования составляющая зеркального отраженного излучения может намного превышать требуемую составляющую диффузного отраженного излучения, снижая эффективность работы сканера. В тех случаях, когда поверхность материала или изделия может быть изменена путем получения матовой поверхности или устранения влияния глянца, это может помочь минимизировать эффекты зеркального отражения. Там, где подобные мероприятия невозможны, должны быть приняты меры по обеспечению специального освещения символа, чтобы оптимизировать считывание при требуемых значениях контраста.
Пользователи должны определить соответствующий уровень исправления ошибок, чтобы он соответствовал требованиям по применению. Согласно таблице 8 четыре уровня исправления ошибок от L до H увеличивают способность обнаружения и исправления ошибок за счет некоторого увеличения размера символа для данной длины сообщения. Например, символ версии 20-Q может содержать в общем случае 485 кодовых слов данных, но в случае применения иного уровня исправления ошибок, те же самые данные могут быть также быть представлены в символе версии 15-L (точная емкость 523 кодовых слова данных).
Уровень исправления ошибок должен быть определен с учетом:
- ожидаемого уровня качества символа: чем ниже ожидаемый класс качества печати, тем выше уровень исправления ошибок, который должен быть использован;
- важности осуществления декодирования с первого сканирования;
- возможности повторного сканирования в случае неудачного декодирования;
- ограничения размеров, которые могут уменьшать возможность использования более высокого уровня исправления ошибок.
Уровень исправления ошибок L соответствует высокому качеству печати символа и/или потребности в самом компактном возможном символе для размещения данных. Уровень M принят в качестве "Стандартного" уровня и обеспечивает хороший компромисс между увеличенной надежностью и небольшим размером. Уровень Q - "Высокая надежность" подходит для более требовательных применений или применений с низким качеством печати, в то время как уровень H обеспечивает максимальную достижимую надежность.
(справочное)
Символы QR Code могут быть считаны с помощью надлежащим образом запрограммированных декодеров, которые предназначены для их автоматического распознавания среди других символик. Запрограммированные соответствующим образом устройства считывания QR Code не должны декодировать символ, принадлежащий другой символике, как действительный символ QR Code; однако, представления, соответствующие коротким линейным символам, могут присутствовать в любом матричном символе, в том числе и в QR Code.
Хотя символы QR Code Model 1 могут быть автоматически распознаны соответствующим декодером отдельно от символов QR Code, настоятельно рекомендуется, чтобы эти два типа символов не использовались совместно в рамках одного применения.
Допустимый набор символик, на которые запрограммирован декодер, должен быть ограничен потребностями конкретного применения для достижения максимальной надежности считывания.
(справочное)
M.1 Общие положения
В настоящем приложении описаны процедуры и инструментальные средства, рекомендуемые для проведения мониторинга и контроля процесса создания пригодных для сканирования символов QR Code. Эти методы не включают в себя проверку качества печати произведенных символов (указанные методы приведены в разделе 10 и приложении G и устанавливают требуемый метод для оценки качества символа), но они по отдельности и все вместе предоставляют полезные рекомендации относительно того, создает ли данная технология производства пригодные для работы символы.
M.2 Контраст символа
Большинство верификаторов для линейных символов штрихового кода имеют или режим рефлектометра или режим построения профилей отражения при сканировании и/или отчет о контрасте символа согласно ISO/IEC 15416 для сканирований без декодирования. За исключением символов, требующих специальной конфигурации освещения, результаты считывания контраста символа с использованием апертуры размером 0,150 или 0,250 мм при оптическом излучении с длиной волны 660 нм (или с отчетом о значениях контраста символа, максимальном и минимальном значениях в профиле отражения при сканировании, или с указанием разности между максимальным и минимальным показаниями рефлектометра) хорошо коррелируются со значениями контраста символа, полученными при обработке изображения. В частности, результаты считывания могут быть использованы для проверки того, что контраст символа остается выше минимального допустимого значения, определяемого классом символа.
M.3 Оценка осевой неоднородности
Для символа QR Code измеряют расстояние от левого края верхнего левого шаблона поиска до правого края верхнего правого шаблона поиска и расстояние от верхнего края верхнего левого шаблона поиска до нижнего края нижнего левого шаблона поиска. Для символов Микро QR Code измеряют расстояние от левого края верхнего левого шаблона поиска до правого края самого правого модуля в верхнем шаблоне синхронизации и расстояние от верхнего края верхнего левого шаблона поиска до нижнего края самого нижнего модуля в левом шаблоне поиска. Производят деление каждого полученного значения на число модулей в соответствующем измерении. Например символ версии 2 имел бы значение 25 в качестве делителя. Следует заменить результаты на XAVG и YAVG в формуле в G.2.4 <1> и получить класс для оценки осевой неоднородности.
--------------------------------
<1> В ИСО/МЭК 18004:2005 ошибочно приведена ссылка на отсутствующий подраздел G.2.4. Формула для определения параметра осевой неоднородности приведена в ИСО/МЭК 15415 (7.8.6).
M.4 Визуальные проверки искажений и дефектов символа
Визуальный осмотр шаблонов писка и шаблонов синхронизации в образцах символов поможет контролировать важный аспект процесса производства.
Матричные символы чувствительны к ошибкам, вызванным локальными искажениями матричной сетки. Любые такие искажения могут быть обнаружены визуально или как изогнутые края на шаблонах поиска или как неравные интервалы в чередующихся шаблонах синхронизации, проведенных между шаблонами поиска и выровненных по их внутренним границам.
Шаблон(ы) поиска и смежные свободные зоны должны всегда быть сплошными темными и светлыми <2>. Ошибки в механизме печати, который может создавать дефекты в форме светлых или темных полос, проходящих через символ, должны быть явно видны там, где они нарушают шаблон поиска или свободную зону. Такие систематические ошибки в процессе печати должны быть исправлены.
--------------------------------
<2> То есть должны иметь коэффициенты отражения с противоположными значениями.
M.5 Оценка приращения размеров элементов при печати
Линейный верификатор штрихового кода, допускающий прямые измерения ширины штрихов и пробелов, может использоваться для оценки приращения или сокращения при печати по горизонтальной и вертикальной осям путем измерения по двум путям сканирования проходящими под прямым углом через шаблон поиска и пересекающими центр, состоящий из блока модулей 3 x 3. Анализ на выходе должен обнаружить видимый шаблон штрих/пробел/штрих/пробел/штрих; увеличение (или уменьшение) при печати можно оценить путем сравнения пяти измеренных значений ширины напечатанных элементов с идеальным отношением значений ширины 1:1:3:1:1.
(справочное)
N.1 Символы Model 1 QR Code
QR Code Model 1 согласно спецификации AIM ITS 97-001 <1>, является формой символики, первоначально использовавшейся в ранних или закрытых системах конкретных применений, но не рекомендуемой для использования в новых или открытых системах применений, и не подходит для случаев, где вероятно появление больших объемов данных. Во многих отношениях это следует из самой спецификации QR Code, но отличается во множестве существенных аспектов, которые приведены в настоящем приложении.
--------------------------------
<1> См. спецификацию [21].
N.1.1 Общие параметры Model 1
a) Размер символа (исключая свободную зону):
От 21 x 21 модулей до 73 x 73 модулей (версии от 1 до 14, в порядке возрастания с шагом в 4 модуля на сторону).
b) Максимальная емкость данных (для символа максимального размера с минимальным уровнем исправления ошибок, версия 14-L):
- числовые данные: | 1 167 знаков; |
- алфавитно-цифровые данные: | 707 знаков; |
- данные в байтах: | 486 знаков; |
- данные в знаках кандзи: | 299 знаков. |
c) Структура и параметры символа в сравнении с символами QR Code:
- направляющие шаблоны: символы Model 1 не имеют направляющих шаблонов;
- дополнительные шаблоны: символы Model 1 имеют дополнительные шаблоны по правой и нижней сторонам;
- информация о версии: символы Model 1 не содержат информации о версии;
- размещение знаков символа: из-за вышеупомянутого, размещение знаков символа следует другим правилам;
- символы Model 1 не поддерживают протокол ECI;
- символы Model 1 не поддерживают зеркальное отображение;
- символы Model 1 не поддерживают инвертирование коэффициентов отражения.
d) Исправление ошибок: алгоритмы вычисления кодовых слов обнаружения и исправления ошибок совпадают с принятыми для символов QR Code, но число и размеры блоков исправления ошибок различаются для разных версий. Для блоков данных и блоков кодовых слов исправления ошибок не используется чередование.
На рисунке N.1 приведена структура символа версии 7 Model 1 QR Code.
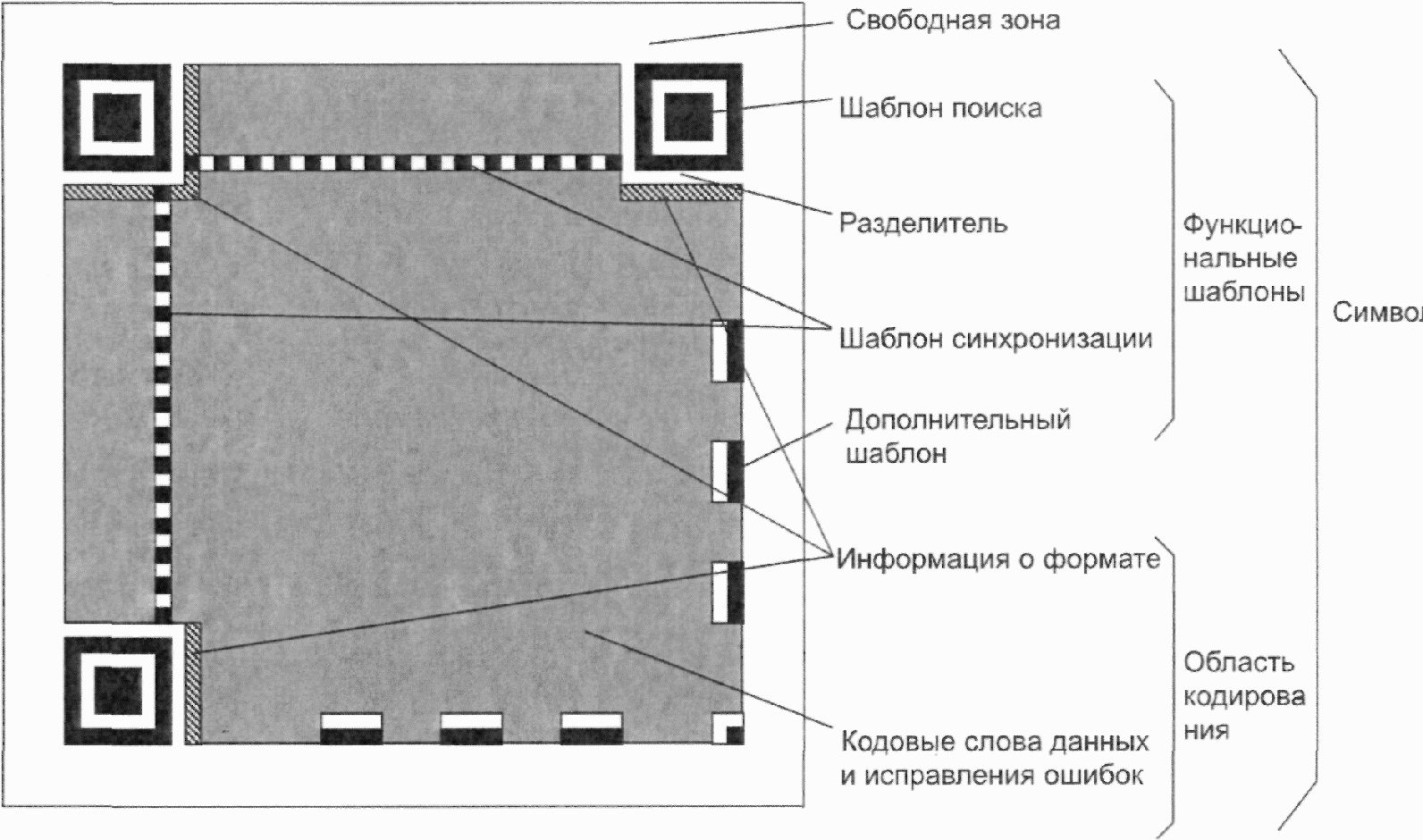
Рисунок N.1 - Структура символа QR Code Model 1
N.1.2 Версии и размеры символов
Установлены четырнадцать вариантов размеров символов Model 1 от версии 1 до версии 14, размеры которых совпадают с размерами символов Model 2 тех же версий согласно 6.3.2. Символы версии 1, следовательно, имеют размер 21 x 21 модуль, а символы версии 14 - размер 73 x 73 модуля. В таблице N.1 приведена емкость данных для символов Model 1 для разных уровней исправления ошибок.
Таблица N.1
Емкость данных для всех версий символов Model 1 QR Code
Версия | Число модулей/сторона (A) | Число модулей в функциональных шаблонах (B) | Число модулей в информации о формате (C) | Оставшееся число модулей для данных (D <1>) (D = A2 - B - C) | Емкость данных [кодовые слова] (E) |
1 | 21 | 206 | 31 | 204 | 26 |
2 | 25 | 230 | 31 | 364 | 46 |
3 | 29 | 238 | 31 | 572 | 72 |
4 | 33 | 262 | 31 | 796 | 100 |
5 | 37 | 270 | 31 | 1 068 | 134 |
6 | 41 | 294 | 31 | 1 356 | 170 |
7 | 45 | 302 | 31 | 1 692 | 212 |
8 | 49 | 326 | 31 | 2 044 | 256 |
9 | 53 | 334 | 31 | 2 444 | 306 |
10 | 57 | 358 | 31 | 2 860 | 358 |
11 | 61 | 366 | 31 | 3 324 | 416 |
12 | 65 | 390 | 31 | 3 804 | 476 |
13 | 69 | 398 | 31 | 4 332 | 542 |
14 | 73 | 422 | 31 | 4 876 | 610 |
Примечание - Первое кодовое слово имеет длину 4 бита. Все последующие кодовые слова имеют длину 8 битов. Для алгоритмов генерации кодовых слов исправления ошибок к первому кодовому слову (4 бита) добавляется префикс 0000, чтобы получить кодовое слово длиной 8 битов.
--------------------------------
N.2 Детальная информация
Полная информация о производстве и считывании символов Model 1 содержится в AIM ITS 97-001 <2>.
--------------------------------
<2> См. спецификацию [21].
(справочное)
ГРАФИЧЕСКИЕ ЗНАКИ РАСШИРЕННОГО НАБОРА ЗНАКОВ ASCII (ВЕРСИЯ
КОИ-8) ПО ИСО/МЭК 8859-1 И НАБОР 8-БИТОВЫХ ГРАФИЧЕСКИХ
ЗНАКОВ (ВЕРСИЯ КОИ-8) ПО ИСО/МЭК 8859-5
ДА.1 Набор 7-битовых знаков ASCII (версия КОИ-7) по ИСО/МЭК 646
В таблице ДА.1 приведен набор 7-битовых знаков ASCII (версия КОИ-7) по ИСО/МЭК 646 и соответствие международных и русских наименований и обозначений знаков.
Таблица ДА.1
Набор 7-битовых знаков ASCII (версия КОИ-7) по ИСО/МЭК 646
Десятичное значение | Шестнадцатеричное значение | Обозначения знака | Наименование знака | ||
Международное | Русское | Международное | Русское | ||
00 | 00 | NUL | ПУС | NULL | ПУСТО |
01 | 01 | SOH | НЗ | START OF HEADING | НАЧАЛО ЗАГОЛОВКА |
02 | 02 | STX | НТ | START OF TEXT | НАЧАЛО ТЕКСТА |
03 | 03 | ETX | КТ | END OF TEXT | КОНЕЦ ТЕКСТА |
04 | 04 | EOT | КП | END OF TRANSMISSION | КОНЕЦ ПЕРЕДАЧИ |
05 | 05 | ENQ | КТМ | ENQUIRY | КТО ТАМ? |
06 | 06 | ACK | ДА | ACKNOWLEDGE | ПОДТВЕРЖДЕНИЕ |
07 | 07 | BEL | ЗВ | BELL | ЗВОНОК |
08 | 08 | BS | ВШ | BACKSPACE | ВОЗВРАТ НА ШАГ |
09 | 09 | HT | ГТ | HORIZONTAL TABULATION | ГОРИЗОНТАЛЬНАЯ ТАБУЛЯЦИЯ |
10 | 0A | LF | ПС | LINE FEED | ПЕРЕВОД СТРОКИ |
11 | 0B | VT | ВТ | VERTICAL TABULATION | ВЕРТИКАЛЬНАЯ ТАБУЛЯЦИЯ |
12 | 0C | FF | ПФ | FORM FEED | ПЕРЕВОД ФОРМАТА |
13 | 0D | CR | ВК | CARRIAGE RETURN | ВОЗВРАТ КАРЕТКИ |
14 | 0E | SO | ВЫХ | SHIFT-OUT | ВЫХОД |
15 | 0F | SI | ВХ | SHIFT-IN | ВХОД |
16 | 10 | DLE | АР1 | DATA LINK ESCAPE | АВТОРЕГИСТР ОДИН |
17 | 11 | DC1 | СУ1 | DEVICE CONTROL ONE | СИМВОЛ УСТРОЙСТВА ОДИН |
18 | 12 | DC2 | СУ2 | DEVICE CONTROL TWO | СИМВОЛ УСТРОЙСТВА ДВА |
19 | 13 | DC3 | СУ3 | DEVICE CONTROL THREE | СИМВОЛ УСТРОЙСТВА ТРИ |
20 | 14 | DC4 | СУ4 | DEVICE CONTROL FOUR | СИМВОЛ УСТРОЙСТВА ЧЕТЫРЕ |
21 | 15 | NAK | НЕТ | NEGATIVE ACKNOWLEDGE | ОТРИЦАНИЕ |
22 | 16 | SYN | СИН | SYNCHRONOUS IDLE | СИНХРОНИЗАЦИЯ |
23 | 17 | ETB | КБ | END OF TRANSMISSION BLOCK | КОНЕЦ БЛОКА |
24 | 18 | CAN | АН | CANCEL | АННУЛИРОВАНИЕ |
25 | 19 | EM | КН | END OF MEDIUM | КОНЕЦ НОСИТЕЛЯ |
26 | 1A | SUB | ЗМ | SUBSTITUTE CHARACTER | ЗАМЕНА СИМВОЛА |
27 | 1B | ESC | АР2 | ESCAPE | АВТОРЕГИСТР ДВА |
28 | 1C | FS | РФ | FILE SEPARATOR | РАЗДЕЛИТЕЛЬ ФАЙЛОВ |
29 | 1D | GS | РГ | GROUP SEPARATOR | РАЗДЕЛИТЕЛЬ ГРУПП |
30 | 1E | RS | РЗ | RECORD SEPARATOR | РАЗДЕЛИТЕЛЬ ЗАПИСЕЙ |
31 | 1F | US | РЭ | UNIT SEPARATOR | РАЗДЕЛИТЕЛЬ ЭЛЕМЕНТОВ |
32 | 20 | SP | SPACE | ПРОБЕЛ | |
33 | 21 | ! | ! | EXCLAMATION MARK | ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК |
34 | 22 | " | " | QUOTATION MARK | КАВЫЧКИ |
35 | 23 | # | # | NUMBER SIGN | НОМЕР |
36 <1> | 24 | CURRENCY SIGH | ЗНАК ДЕНЕЖНОЙ ЕДИНИЦЫ | ||
<1> В международной ссылочной версии (IRV. International Reference Version) ИСО/МЭК 646 знаку с десятичным значением 36 соответствует знак $ - DOLLAR SIGH (ДЕНЕЖНЫЙ ЗНАК ДОЛЛАРА). | |||||
37 | 25 | % | % | PERCENT SIGH | ПРОЦЕНТЫ |
38 | 26 | & | & | AMPERSAND | КОММЕРЧЕСКОЕ И (АМПЕРСАНД) |
39 | 27 | ' | ' | APOSTROPHE | АПОСТРОФ |
40 | 28 | ( | ( | LEFT PARENTHESIS | КРУГЛАЯ СКОБКА ЛЕВАЯ |
41 | 29 | ) | ) | RIGHT PARENTHESIS | КРУГЛАЯ СКОБКА ПРАВАЯ |
42 | 2A | * | * | ASTERISK | ЗВЕЗДОЧКА |
43 | 2B | + | + | PLUS SIGH | ПЛЮС |
44 | 2C | , | , | COMMA | ЗАПЯТАЯ |
45 | 2D | - | - | HYPHEN-MINUS | ДЕФИС, МИНУС |
46 | 2E | . | . | FULL STOP | ТОЧКА |
47 | 2F | / | / | SOLIDUS | ДРОБНАЯ ЧЕРТА |
48 | 30 | 0 | 0 | DIGIT ZERO | ЦИФРА НОЛЬ |
49 | 31 | 1 | 1 | DIGIT ONE | ЦИФРА ОДИН |
50 | 32 | 2 | 2 | DIGIT TWO | ЦИФРА ДВА |
51 | 33 | 3 | 3 | DIGIT THREE | ЦИФРА ТРИ |
52 | 34 | 4 | 4 | DIGIT FOUR | ЦИФРА ЧЕТЫРЕ |
53 | 35 | 5 | 5 | DIGIT FIVE | ЦИФРА ПЯТЬ |
54 | 36 | 6 | 6 | DIGIT SIX | ЦИФРА ШЕСТЬ |
55 | 37 | 7 | 7 | DIGIT SEVEN | ЦИФРА СЕМЬ |
56 | 38 | 8 | 8 | DIGIT EIGHT | ЦИФРА ВОСЕМЬ |
57 | 39 | 9 | 9 | DIGIT NINE | ЦИФРА ДЕВЯТЬ |
58 | 3A | : | : | COLON | ДВОЕТОЧИЕ |
59 | 3B | ; | ; | SEMICOLON | ТОЧКА С ЗАПЯТОЙ |
60 | 3C | < | < | LESS THAN SIGN | МЕНЬШЕ |
61 | 3D | = | = | EQUALS SIGN | РАВНО |
62 | 3E | > | > | GREATER THAN SIGN | БОЛЬШЕ |
63 | 3F | ? | ? | QUESTION MARK | ВОПРОСИТЕЛЬНЫЙ ЗНАК |
64 | 40 | @ | @ | COMMERCIAL AT | КОММЕРЧЕСКОЕ ЭТ |
65 | 41 | A | A | LATIN CAPITAL LETTER A | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A |
66 | 42 | B | B | LATIN CAPITAL LETTER B | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА B |
67 | 43 | C | C | LATIN CAPITAL LETTER C | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА C |
68 | 44 | D | D | LATIN CAPITAL LETTER D | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА D |
69 | 45 | E | E | LATIN CAPITAL LETTER E | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА E |
70 | 46 | F | F | LATIN CAPITAL LETTER F | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА F |
71 | 47 | G | G | LATIN CAPITAL LETTER G | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА G |
72 | 48 | H | H | LATIN CAPITAL LETTER H | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА H |
73 | 49 | I | I | LATIN CAPITAL LETTER I | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА I |
74 | 4A | J | J | LATIN CAPITAL LETTER J | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА J |
75 | 4B | K | K | LATIN CAPITAL LETTER K | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА K |
76 | 4C | L | L | LATIN CAPITAL LETTER L | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА L |
77 | 4D | M | M | LATIN CAPITAL LETTER M | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА M |
78 | 4E | N | N | LATIN CAPITAL LETTER N | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА N |
79 | 4F | O | O | LATIN CAPITAL LETTER O | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O |
80 | 50 | P | P | LATIN CAPITAL LETTER P | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА P |
81 | 51 | Q | Q | LATIN CAPITAL LETTER Q | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА Q |
82 | 52 | R | R | LATIN CAPITAL LETTER R | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА R |
83 | 53 | S | S | LATIN CAPITAL LETTER S | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА S |
84 | 54 | T | T | LATIN CAPITAL LETTER T | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА T |
85 | 55 | U | U | LATIN CAPITAL LETTER U | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА U |
86 | 56 | V | V | LATIN CAPITAL LETTER V | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА V |
87 | 57 | W | W | LATIN CAPITAL LETTER W | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА W |
88 | 58 | X | X | LATIN CAPITAL LETTER X | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА X |
89 | 59 | Y | Y | LATIN CAPITAL LETTER Y | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА Y |
90 | 5A | Z | Z | LATIN CAPITAL LETTER Z | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА Z |
91 | 5B | [ | [ | LEFT SQUARE BRACKET | КВАДРАТНАЯ СКОБКА ЛЕВАЯ |
92 | 5C | \ | \ | REVERSE SOLIDUS | ОБРАТНАЯ ДРОБНАЯ ЧЕРТА |
93 | 5D | ] | ] | RIGHT SQUARE BRACKET | КВАДРАТНАЯ СКОБКА ПРАВАЯ |
94 | 5E | CIRCUMFLEX ACCENT | ЦИРКУМФЛЕКС УДАРЕНИЕ | ||
95 | 5F | _ | _ | LOW LINE | ПОДЧЕРКИВАНИЕ |
96 | 60 | GRAVE ACCENT | СЛАБОЕ УДАРЕНИЕ | ||
97 | 61 | a | a | LATIN SMALL LETTER A | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a |
98 | 62 | b | b | LATIN SMALL LETTER B | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА b |
99 | 63 | c | c | LATIN SMALL LETTER C | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА c |
100 | 64 | d | d | LATIN SMALL LETTER D | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА d |
101 | 65 | e | e | LATIN SMALL LETTER E | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА e |
102 | 66 | f | f | LATIN SMALL LETTER F | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА f |
103 | 67 | g | g | LATIN SMALL LETTER G | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА g |
104 | 68 | h | h | LATIN SMALL LETTER H | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА h |
105 | 69 | i | i | LATIN SMALL LETTER I | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА i |
106 | 6A | j | j | LATIN SMALL LETTER J | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА j |
107 | 6B | k | k | LATIN SMALL LETTER K | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА k |
108 | 6C | l | l | LATIN SMALL LETTER L | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА l |
109 | 6D | m | m | LATIN SMALL LETTER M | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА m |
110 | 6E | n | n | LATIN SMALL LETTER N | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА n |
111 | 6F | o | o | LATIN SMALL LETTER O | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o |
112 | 70 | p | p | LATIN SMALL LETTER P | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА p |
113 | 71 | q | q | LATIN SMALL LETTER Q | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА q |
114 | 72 | r | r | LATIN SMALL LETTER R | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА r |
115 | 73 | s | s | LATIN SMALL LETTER S | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА s |
116 | 74 | t | t | LATIN SMALL LETTER T | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА t |
117 | 75 | u | u | LATIN SMALL LETTER U | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА u |
118 | 76 | v | v | LATIN SMALL LETTER V | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА v |
119 | 77 | w | w | LATIN SMALL LETTER W | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА w |
120 | 78 | x | x | LATIN SMALL LETTER X | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА x |
121 | 79 | y | y | LATIN SMALL LETTER Y | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА y |
122 | 7A | z | z | LATIN SMALL LETTER Z | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА z |
123 | 7B | { | { | LEFT CURLY BRACKET | ФИГУРНАЯ СКОБКА ЛЕВАЯ |
124 | 7C | | | | | VERTICAL LINE | ВЕРТИКАЛЬНАЯ ЧЕРТА |
125 | 7D | } | } | RIGHT CURLY BRACKET | ФИГУРНАЯ СКОБКА ПРАВАЯ |
126 | 7E | ~ | ~ | TILDE | ТИЛЬДА |
127 | 7F | DEL | DEL | DELETE | ЗАБОЙ |
Примечание - Набор 7-битовых знаков ASCII (версия КОИ-7) состоит из набора знаков G0 по ИСО/МЭК 646 и C0 по ИСО/МЭК 6429, в котором знаки с десятичными значениями от 28 до 31 соответствуют знакам FS, GS, RS и US национальной версии США <1> соответственно.
--------------------------------
<1> Набор знаков по ANSI INCITS 4-1986 (R2007) Information Systems - Coded Character Sets - 7-Bit American National Standard Code for Information Interchange (7-Bit ASCII) (Информационные системы - Кодированные наборы знаков - 7-битовый американский национальный стандартный код для обмена информацией (7-битовый ASCII)).
ДА.2 Графические знаки расширенного набора знаков ASCII (версия КОИ-8) по ИСО/МЭК 8859-1
В таблице ДА.2 приведены графические знаки расширенного набора 8-битовых знаков ASCII (версия КОИ-8) по ИСО/МЭК 8859-1:1998 (латинский алфавит N 1) и соответствие международных и русских наименований и обозначений знаков. В связи с тем, что знаки указанного набора с десятичными значениями с 0 по 127 полностью совпадают с набором знаков ASCII (КОИ-7), в таблице ДА.2 приведены 8-битовые графические знаки с десятичными значениями от 160 по 255 и их шестнадцатеричные значения.
Таблица ДА.2
Графические знаки расширенного набора 8-битовых знаков ASCII
(версия КОИ-8) по ИСО/МЭК 8859-1
Десятичное значение | Шестнадцатеричное значение | Международное (русское) обозначение знака | Наименование знака | |||||
Международное | Русское | |||||||
160 | A0 | NBSP (НПР) | NO-BREAK SPACE | НЕПРЕРЫВАЮЩИЙ ПРОБЕЛ | ||||
161 | A1 | INVERTED EXCLAMATION MARK | ПЕРЕВЕРНУТЫЙ ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК | |||||
162 | A2 | CENT SIGN | ДЕНЕЖНЫЙ ЗНАК ЦЕНТА | |||||
163 | A3 | POUND SIGN | ДЕНЕЖНЫЙ ЗНАК ФУНТА | |||||
164 | A4 | CURRENCY SIGN | ЗНАК ДЕНЕЖНОЙ ЕДИНИЦЫ | |||||
165 | A5 | YEN SIGN | ДЕНЕЖНЫЙ ЗНАК ЙЕНЫ | |||||
166 | A6 | BROKEN BAR | ВЕРТИКАЛЬНАЯ ЧЕРТА С РАЗРЫВОМ | |||||
167 | A7 | § | SECTION SIGN | ПАРАГРАФ | ||||
168 | A8 | DIAERESIS | ДИЕРЕЗ | |||||
169 | A9 | COPYRIGHT SIGN | ЗНАК АВТОРСКОГО ПРАВА | |||||
170 | AA | FEMININE ORDINAL INDICATOR | ЖЕНСКИЙ ПОРЯДКОВЫЙ ИНДИКАТОР | |||||
171 | AB | LEFT POINTING DOUBLE ANGLE QUOTATION MARK | ЗНАК ЛЕВОНАПРАВЛЕННОЙ ДВОЙНОЙ УГЛОВОЙ КАВЫЧКИ | |||||
172 | AC | NOT SIGN | ЗНАК НЕТ | |||||
| ||||||||
173 | AD | SOFT HYPHEN | ГИБКИЙ ДЕФИС | |||||
174 | AE | REGISTERED SIGN | ЗНАК РЕГИСТРАЦИИ | |||||
175 | AF | MACRON | ЧЕРТА СВЕРХУ | |||||
176 | B0 | ° | DEGREE SIGN | ЗНАК ГРАДУСА | ||||
177 | B1 | PLUS-MINUS SIGN | ЗНАК ПЛЮС-МИНУС | |||||
178 | B2 | SUPERSCRIPT TWO | ВЕРХНИЙ ИНДЕКС ДВА | |||||
179 | B3 | SUPERSCRIPT THREE | ВЕРХНИЙ ИНДЕКС ТРИ | |||||
180 | B4 | ACUTE ACCENT | СИЛЬНОЕ УДАРЕНИЕ | |||||
181 | B5 | MICRO SIGN | ЗНАК МИКРО | |||||
182 | B6 | PILCROW SIGN | ЗНАК ПИ | |||||
183 | B7 | MIDDLE DOT | СРЕДНЯЯ ТОЧКА | |||||
184 | B8 | CEDILLA | СЕДИЛЬ | |||||
185 | B9 | SUPERSCRIPT ONE | ВЕРХНИЙ ИНДЕКС ОДИН | |||||
186 | BA | MASCULINE ORDINAL INDICATOR | МУЖСКОЙ ПОРЯДКОВЫЙ ИНДИКАТОР | |||||
187 | BB | RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK | ЗНАК ПРАВОНАПРАВЛЕННОЙ ДВОЙНОЙ УГЛОВОЙ КАВЫЧКИ | |||||
188 | BC | VULGAR FRACTION ONE QUARTER | ПРОСТАЯ ДРОБЬ ОДНА ЧЕТВЕРТАЯ | |||||
189 | BD | VULGAR FRACTION ONE HALF | ПРОСТАЯ ДРОБЬ ОДНА ВТОРАЯ | |||||
190 | BE | VULGAR FRACTION THREE QUARTERS | ПРОСТАЯ ДРОБЬ ТРИ ЧЕТВЕРТЫХ | |||||
191 | BF | INVERTED QUESTION MARK | ПЕРЕВЕРНУТЫЙ ВОПРОСИТЕЛЬНЫЙ ЗНАК | |||||
192 | C0 | LATIN CAPITAL LETTER A WITH GRAVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A СО СЛАБЫМ УДАРЕНИЕМ | |||||
193 | C1 | LATIN CAPITAL LETTER A WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A С СИЛЬНЫМ УДАРЕНИЕМ | |||||
194 | C2 | LATIN CAPITAL LETTER A WITH CIRCUMFLEX | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A С ЦИРКУМФЛЕКСОМ | |||||
| ||||||||
194 | C3 | LATIN CAPITAL LETTER A WITH TILDE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A С ТИЛЬДОЙ | |||||
196 | C4 | LATIN CAPITAL LETTER A WITH DIAERESIS | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A С ДИЕРЕЗОМ | |||||
197 | C5 | LATIN CAPITAL LETTER A WITH RING ABOVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА A С КРУЖКОМ СВЕРХУ | |||||
198 | C6 | LATIN CAPITAL LETTER | ПРОПИСНАЯ ЛАТИНСКАЯ ЛИГАТУРА | |||||
199 | C7 | LATIN CAPITAL LETTER C WITH CEDILLA | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЕМ | |||||
200 | C8 | LATIN CAPITAL LETTER E WITH GRAVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА E СО СЛАБЫМ УДАРЕНИЕМ | |||||
201 | C9 | LATIN CAPITAL LETTER E WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА E С СИЛЬНЫМ УДАРЕНИЕМ | |||||
202 | CA | LATIN CAPITAL LETTER E WITH CIRCUMFLEX | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА E С ЦИРКУМФЛЕКСОМ | |||||
203 | CB | LATIN CAPITAL LETTER E WITH DIAERESIS | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА E С ДИЕРЕЗОМ | |||||
204 | CC | LATIN CAPITAL LETTER I WITH GRAVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА I СО СЛАБЫМ УДАРЕНИЕМ | |||||
205 | CD | LATIN CAPITAL LETTER I WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА I С СИЛЬНЫМ УДАРЕНИЕМ | |||||
206 | CE | LATIN CAPITAL LETTER I WITH CIRCUMFLEX | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА I С ЦИРКУМФЛЕКСОМ | |||||
207 | CF | LATIN CAPITAL LETTER I WITH DIAERESIS | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА I С ДИЕРЕЗОМ | |||||
208 | D0 | LATIN CAPITAL LETTER ETH | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА D СО ШТРИХОМ | |||||
209 | D1 | LATIN CAPITAL LETTER N WITH TILDE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ | |||||
210 | D2 | LATIN CAPITAL LETTER O WITH GRAVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O СО СЛАБЫМ УДАРЕНИЕМ | |||||
211 | D3 | LATIN CAPITAL LETTER O WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O С СИЛЬНЫМ УДАРЕНИЕМ | |||||
212 | D4 | LATIN CAPITAL LETTER O WITH CIRCUMFLEX | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O С ЦИРКУМФЛЕКСОМ | |||||
213 | D5 | LATIN CAPITAL LETTER O WITH TILDE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ | |||||
214 | D6 | LATIN CAPITAL LETTER O WITH DIAERESIS | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O С ДИЕРЕЗОМ | |||||
215 | D7 | MULTIPLICATION SING | ЗНАК УМНОЖЕНИЯ | |||||
216 | D8 | LATIN CAPITAL LETTER O WITH STROKE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА O СО ШТРИХОМ | |||||
217 | D9 | LATIN CAPITAL LETTER U WITH GRAVE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА U СО СЛАБЫМ УДАРЕНИЕМ | |||||
218 | DA | LATIN CAPITAL LETTER U WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА U С СИЛЬНЫМ УДАРЕНИЕМ | |||||
219 | DB | LATIN CAPITAL LETTER U WITH CIRCUMFLEX | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА U С ЦИРКУМФЛЕКСОМ | |||||
220 | DC | LATIN CAPITAL LETTER U WITH DIAERESIS | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА U С ДИЕРЕЗОМ | |||||
221 | DD | LATIN CAPITAL LETTER Y WITH ACUTE | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА Y С СИЛЬНЫМ УДАРЕНИЕМ | |||||
222 | DE | LATIN CAPITAL LETTER THORN | ПРОПИСНАЯ ЛАТИНСКАЯ БУКВА | |||||
223 | DF | LATIN SMALL LETTER SHARP S | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА | |||||
224 | E0 | LATIN SMALL LETTER A WITH GRAVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a СО СЛАБЫМ УДАРЕНИЕМ | |||||
225 | E1 | LATIN SMALL LETTER A WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a С СИЛЬНЫМ УДАРЕНИЕМ | |||||
226 | E2 | LATIN SMALL LETTER A WITH CIRCUMFLEX | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a С ЦИРКУМФЛЕКСОМ | |||||
227 | E3 | LATIN SMALL LETTER A WITH TILDE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a С ТИЛЬДОЙ | |||||
228 | E4 | LATIN SMALL LETTER A WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a С ДИЕРЕЗОМ | |||||
229 | E5 | LATIN SMALL LETTER A WITH RING ABOVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА a С КРУЖКОМ СВЕРХУ | |||||
230 | E6 | LATIN SMALL LETTER AE | СТРОЧНАЯ ЛАТИНСКАЯ ЛИГАТУРА | |||||
231 | E7 | LATIN SMALL LETTER С WITH CEDILLA | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА c С СЕДИЛЕМ | |||||
232 | E8 | LATIN SMALL LETTER E WITH GRAVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА e СО СЛАБЫМ УДАРЕНИЕМ | |||||
233 | E9 | LATIN SMALL LETTER E WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА e С СИЛЬНЫМ УДАРЕНИЕМ | |||||
234 | EA | LATIN SMALL LETTER E WITH CIRCUMFLEX | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА e С ЦИРКУМФЛЕКСОМ | |||||
235 | EB | LATIN SMALL LETTER E WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА e С ДИЕРЕЗОМ | |||||
236 | EC | LATIN SMALL LETTER I WITH GRAVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА i СО СЛАБЫМ УДАРЕНИЕМ | |||||
237 | ED | LATIN SMALL LETTER I WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА i С СИЛЬНЫМ УДАРЕНИЕМ | |||||
238 | EE | LATIN SMALL LETTER I WITH CIRCUMFLEX | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА i С ЦИРКУМФЛЕКСОМ | |||||
239 | EF | LATIN SMALL LETTER I WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА i С ДИЕРЕЗОМ | |||||
240 | F0 | LATIN SMALL LETTER ETH | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА | |||||
241 | F1 | LATIN SMALL LETTER N WITH TILDE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА n С ТИЛЬДОЙ | |||||
242 | F2 | LATIN SMALL LETTER O WITH GRAVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o СО СЛАБЫМ УДАРЕНИЕМ | |||||
243 | F3 | LATIN SMALL LETTER O WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o С СИЛЬНЫМ УДАРЕНИЕМ | |||||
244 | F4 | LATIN SMALL LETTER O WITH CIRCUMFLEX | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o С ЦИРКУМФЛЕКСОМ | |||||
245 | F5 | LATIN SMALL LETTER O WITH TILDE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o С ТИЛЬДОЙ | |||||
246 | F6 | LATIN SMALL LETTER O WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o С ДИЕРЕЗОМ | |||||
247 | F7 | DIVISION SING | ЗНАК ДЕЛЕНИЯ | |||||
248 | F8 | LATIN SMALL LETTER O WITH STROKE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА o СО ШТРИХОМ | |||||
249 | F9 | LATIN SMALL LETTER U WITH GRAVE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА u СО СЛАБЫМ УДАРЕНИЕМ | |||||
250 | FA | LATIN SMALL LETTER U WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА u С СИЛЬНЫМ УДАРЕНИЕМ | |||||
251 | FB | LATIN SMALL LETTER U WITH CIRCUMFLEX | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА u С ЦИРКУМФЛЕКСОМ | |||||
252 | FC | LATIN SMALL LETTER U WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА u С ДИЕРЕЗОМ | |||||
253 | FD | LATIN SMALL LETTER Y WITH ACUTE | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА y С СИЛЬНЫМ УДАРЕНИЕМ | |||||
254 | FE | LATIN SMALL LETTER THORN | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА | |||||
255 | FF | LATIN SMALL LETTER Y WITH DIAERESIS | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА y С ДИЕРЕЗОМ | |||||
ДА.3 Набор 8-битовых графических знаков (версия КОИ-8) по ИСО/МЭК 8859-5
В таблице ДА.3 приведен набор 8-битовых графических знаков (версия КОИ-8) по ИСО/МЭК 8859-5:1999 (латинский/кирилловский алфавит) и соответствие международных и русских наименований и обозначений знаков. В связи с тем, что знаки указанного набора с десятичными значениями с 0 по 127 полностью совпадают с набором 7-битовых знаков по ИСО 646, в таблице ДА.3 приведены 8-битовые графические знаки с десятичными значениями от 160 по 255.
Таблица ДА.3
Набор 8-битовых графических знаков (версия КОИ-8)
по ИСО/МЭК 8859-5
Десятичное значение | Шестнадцатеричное значение | Международное (русское) обозначение знака | Наименование знака | |
Международное | Русское | |||
160 | A0 | NBSP (НПР) | NO-BREAK SPACE | НЕРАЗРЫВАЮЩИЙ ПРОБЕЛ |
161 | A1 | CYRILLIC CAPITAL LETTER IO | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
162 | A2 | CYRILLIC CAPITAL LETTER DJE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
163 | A3 | CYRILLIC CAPITAL LETTER GJE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
164 | A4 | CYRILLIC CAPITAL LETTER UKRAINIAN IE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
165 | A5 | CYRILLIC CAPITAL LETTER DZE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
166 | A6 | CYRILLIC CAPITAL LETTER BYELORUSSIAN-UKRAINIAN I | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
167 | A7 | CYRILLIC CAPITAL LETTER YI | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
168 | A8 | CYRILLIC CAPITAL LETTER JE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
169 | A9 | CYRILLIC CAPITAL LETTER LJE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
170 | AA | CYRILLIC CAPITAL LETTER NJE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
171 | AB | CYRILLIC CAPITAL LETTER TSHE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
172 | AC | CYRILLIC CAPITAL LETTER KJE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
173 | AD | SHY (ГД) | SOFT HYPHEN | ГИБКИЙ ДЕФИС |
174 | AE | CYRILLIC CAPITAL LETTER SHORT U | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
175 | AF | CYRILLIC CAPITAL LETTER DZHE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА | |
176 | B0 | А | CYRILLIC CAPITAL LETTER A | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА А |
177 | B1 | Б | CYRILLIC CAPITAL LETTER BE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Б |
178 | B2 | В | CYRILLIC CAPITAL LETTER VE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА В |
179 | B3 | Г | CYRILLIC CAPITAL LETTER GHE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Г |
180 | B4 | Д | CYRILLIC CAPITAL LETTER DE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Д |
181 | B5 | Е | CYRILLIC CAPITAL LETTER IE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Е |
182 | B6 | Ж | CYRILLIC CAPITAL LETTER ZHE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ж |
183 | B7 | З | CYRILLIC CAPITAL LETTER ZE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА З |
184 | B8 | И | CYRILLIC CAPITAL LETTER I | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА И |
185 | B9 | Й | CYRILLIC CAPITAL LETTER SHORT I | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Й |
186 | BA | К | CYRILLIC CAPITAL LETTER KA | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА К |
187 | BB | Л | CYRILLIC CAPITAL LETTER EL | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Л |
188 | BC | М | CYRILLIC CAPITAL LETTER EM | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА М |
189 | BD | Н | CYRILLIC CAPITAL LETTER EN | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Н |
190 | BE | О | CYRILLIC CAPITAL LETTER O | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА О |
191 | BF | П | CYRILLIC CAPITAL LETTER PE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА П |
192 | C0 | Р | CYRILLIC CAPITAL LETTER ER | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Р |
193 | C1 | С | CYRILLIC CAPITAL LETTER ES | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА С |
194 | C2 | Т | CYRILLIC CAPITAL LETTER TE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Т |
195 | C3 | У | CYRILLIC CAPITAL LETTER U | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА У |
196 | C4 | Ф | CYRILLIC CAPITAL LETTER EF | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ф |
197 | C5 | Х | CYRILLIC CAPITAL LETTER HA | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Х |
198 | C6 | Ц | CYRILLIC CAPITAL LETTER TSE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ц |
199 | C7 | Ч | CYRILLIC CAPITAL LETTER CHE | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ч |
200 | C8 | Ш | CYRILLIC CAPITAL LETTER SHA | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ш |
201 | C9 | Щ | CYRILLIC CAPITAL LETTER SHCHA | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Щ |
202 | CA | Ъ | CYRILLIC CAPITAL LETTER HARD SIGN | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ъ |
203 | CB | Ы | CYRILLIC CAPITAL LETTER YERU | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ы |
204 | CC | Ь | CYRILLIC CAPITAL LETTER SOFT SIGN | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ь |
205 | CD | Э | CYRILLIC CAPITAL LETTER E | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Э |
206 | CE | Ю | CYRILLIC CAPITAL LETTER YU | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Ю |
207 | CF | Я | CYRILLIC CAPITAL LETTER YA | ПРОПИСНАЯ КИРИЛЛОВСКАЯ БУКВА Я |
208 | D0 | а | CYRILLIC SMALL LETTER A | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА а |
209 | D1 | б | CYRILLIC SMALL LETTER BE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА б |
210 | D2 | в | CYRILLIC SMALL LETTER VE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА в |
211 | D3 | г | CYRILLIC SMALL LETTER GHE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА г |
212 | D4 | д | CYRILLIC SMALL LETTER DE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА д |
213 | D5 | е | CYRILLIC SMALL LETTER IE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА е |
214 | D6 | ж | CYRILLIC SMALL LETTER ZHE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ж |
215 | D7 | з | CYRILLIC SMALL LETTER ZE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА з |
216 | D8 | и | CYRILLIC SMALL LETTER I | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА и |
217 | D9 | й | CYRILLIC SMALL LETTER SHORT I | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА й |
218 | DA | к | CYRILLIC SMALL LETTER KA | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА к |
219 | DB | л | CYRILLIC SMALL LETTER EL | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА л |
220 | DC | м | CYRILLIC SMALL LETTER EM | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА м |
221 | DD | н | CYRILLIC SMALL LETTER EN | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА н |
222 | DE | о | CYRILLIC SMALL LETTER O | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА о |
223 | DF | п | CYRILLIC SMALL LETTER PE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА п |
224 | E0 | р | CYRILLIC SMALL LETTER ER | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА р |
225 | E1 | с | CYRILLIC SMALL LETTER ES | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА с |
226 | E2 | т | CYRILLIC SMALL LETTER TE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА т |
227 | E3 | у | CYRILLIC SMALL LETTER U | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА у |
228 | E4 | ф | CYRILLIC SMALL LETTER EF | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ф |
229 | E5 | х | CYRILLIC SMALL LETTER HA | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА х |
230 | E6 | ц | CYRILLIC SMALL LETTER TSE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ц |
231 | E7 | ч | CYRILLIC SMALL LETTER CHE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ч |
232 | E8 | ш | CYRILLIC SMALL LETTER SHA | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ш |
233 | E9 | щ | CYRILLIC SMALL LETTER SHCHA | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА щ |
234 | EA | ъ | CYRILLIC SMALL LETTER HARD SIGN | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ъ |
235 | EB | ы | CYRILLIC SMALL LETTER YERU | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ы |
236 | EC | ь | CYRILLIC SMALL LETTER SOFT SIGN | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ь |
237 | ED | э | CYRILLIC SMALL LETTER E | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА э |
238 | EE | ю | CYRILLIC SMALL LETTER YU | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА ю |
239 | EF | я | CYRILLIC SMALL LETTER YA | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА я |
240 | F0 | nо | NUMERO SIGN | ЗНАК "НОМЕР" |
241 | F1 | CYRILLIC SMALL LETTER IO | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
242 | F2 | CYRILLIC SMALL LETTER DJE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
243 | F3 | CYRILLIC SMALL LETTER GJE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
244 | F4 | CYRILLIC SMALL LETTER UKRAINIAN IE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
245 | F5 | CYRILLIC SMALL LETTER DZE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
246 | F6 | CYRILLIC SMALL LETTER BYELORUSSIAN-UKRAINIAN I | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
247 | F7 | CYRILLIC SMALL LETTER YI | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
248 | F8 | CYRILLIC SMALL LETTER JE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
249 | F9 | CYRILLIC SMALL LETTER LJE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
250 | FA | CYRILLIC SMALL LETTER NJE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
251 | FB | CYRILLIC SMALL LETTER TSHE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
252 | FC | CYRILLIC SMALL LETTER KJE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
253 | FD | § | SECTION SIGN | ПАРАГРАФ |
254 | FE | CYRILLIC SMALL LETTER SHORT U | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
255 | FF | CYRILLIC SMALL LETTER DZHE | СТРОЧНАЯ КИРИЛЛОВСКАЯ БУКВА | |
(справочное)
ССЫЛОЧНЫМ НАЦИОНАЛЬНЫМ СТАНДАРТАМ РОССИЙСКОЙ ФЕДЕРАЦИИ
Сведения о соответствии ссылочных международных стандартов ссылочным национальным стандартам Российской Федерации приведены в таблице ДБ.1.
Таблица ДБ.1
Обозначение ссылочного международного стандарта | Степень соответствия | Обозначение и наименование соответствующего национального стандарта | ||||
ИСО/МЭК 8859-1:1998 | ||||||
ИСО/МЭК 15415 | IDT | ГОСТ Р ИСО/МЭК 15415-2012 "Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация испытаний символов штрихового кода для оценки качества печати. Двумерные символы" | ||||
| ||||||
ИСО/МЭК 19762-1 | IDT | ГОСТ Р ИСО/МЭК 19762-1-2011 "Информационные технологии. Технологии автоматической идентификации и сбора данных (АИСД). Гармонизированный словарь. Часть 1. Общие термины в области АИСД" | ||||
ИСО/МЭК 19762-2 | IDT | ГОСТ Р ИСО/МЭК 19762-2-2011 "Информационные технологии. Технологии автоматической идентификации и сбора данных (АИСД). Гармонизированный словарь. Часть 2. Оптические носители данных (ОНД)" | ||||
JIS X 0201 | <*> | |||||
<*> Соответствующий национальный стандарт отсутствует. Оригинал международного стандарта ИСО/МЭК находится в Федеральном информационном фонде технических регламентов и стандартов. Примечание - В настоящей таблице принято следующее условное обозначение: IDT - идентичный стандарт. | ||||||
[1] | ISO/IEC 646, Information technology - ISO 7-bit coded graphic character set (Информационные технологии - 7-битовый кодированный набор знаков ИСО для обмена информацией) |
[2] | ISO/IEC 8859-2:1999 <1>, Information technology - 8-bit single-byte coded graphic character sets - Part 2: Latin alphabet No. 2 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 2: Латинский алфавит N 2) |
[3] | ISO/IEC 8859-3:1999, Information technology - 8-bit single-byte coded graphic character sets - Part 3: Latin alphabet No. 3 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 3: Латинский алфавит N 3) |
[4] | ISO/IEC 8859-4:1998, Information technology - 8-bit single-byte coded graphic character sets - Part 4: Latin alphabet No. 4 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 4: Латинский алфавит N 4) |
[5] | ISO/IEC 8859-5:1999 <2>, Information technology - 8-bit single-byte coded graphic character sets - Part 5: Latin/Cyrillic alphabet (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 5: Латинский/Кирилловский алфавит) |
[6] | ISO/IEC 8859-6:1999, Information technology - 8-bit single-byte coded graphic character sets - Part 6: Latin/Arabic alphabet (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 6: Латинский/Арабский алфавит) |
[7] | ISO/IEC 8859-7:2003, Information technology - 8-bit single-byte coded graphic character sets - Part 7: Latin/Greek alphabet (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 7: Латинский/Греческий алфавит) |
[8] | ISO/IEC 8859-8:1999, Information technology - 8-bit single-byte coded graphic character sets - Part 8: Latin/Hebrew alphabet (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 8: Латинский алфавит /Иврит) |
[9] | ISO/IEC 8859-9:1999, Information technology - 8-bit single-byte coded graphic character sets - Part 9: Latin alphabet No. 5 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 9: Латинский алфавит N 5) |
[10] | ISO/IEC 8859-10:1998, Information technology - 8-bit single-byte coded graphic character sets - Part 10: Latin alphabet No. 6 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков. - Часть 10: Латинский алфавит N 6) |
[11] | ISO/IEC 8859-11:2001, Information technology - 8-bit single-byte coded graphic character sets - Part 11: Latin/Thai alphabet (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 11: Латинский/Тайский алфавит) |
[12] | ISO/IEC 8859-13:1998, Information technology - 8-bit single-byte coded graphic character sets - Part 13: Latin alphabet No. 7 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 13: Латинский алфавит N 7) |
[13] | ISO/IEC 8859-14:1998, Information technology - 8-bit single-byte coded graphic character sets - Part 14: Latin alphabet No. 8 (Celtic) (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 14: Латинский алфавит N 8 (Кельтский)) |
[14] | ISO/IEC 8859-15:1999, Information technology - 8-bit single-byte coded graphic character sets - Part 15: Latin alphabet No. 9 (Информационные технологии. 8-битовые однобайтовые кодированные наборы графических знаков. Часть 15: Латинский алфавит N 9) |
[15] | ISO/IEC 8859-16:2001, Information technology - 8-bit single-byte coded graphic character sets - Part 16: Latin alphabet No. 10 (Информационные технологии - 8-битовые однобайтовые кодированные наборы графических знаков - Часть 16: Латинский алфавит N 10) |
[16] | ISO/IEC 15416 <3>, Information Technology - Automatic identification and data capture techniques - Bar code print quality test specification - Linear symbols (Информационные технологии - Технологии автоматической идентификации и сбора данных - Спецификация испытаний штрихового кода на соответствие качества печати - Линейные символы) |
--------------------------------
<1> Действует ГОСТ 34.302.2-91 "Информационная технология. Наборы 8-битовых однобайтовых кодированных графических символов. Латинский алфавит N 2".
ИС МЕГАНОРМ: примечание. В официальном тексте документа, видимо, допущена опечатка: имеется в виду приложение ДА, а не приложение ДБ. |
<2> В приложении ДБ настоящего стандарта приведен набор знаков по ИСО/МЭК 8859-5 (ISO/IEC 8859-5).
<3> ГОСТ 30832-2002 (ИСО/МЭК 15416-2000)/ГОСТ Р 51294.7-2001 (ИСО/МЭК 15416-2000) "Автоматическая идентификация. Кодирование штриховое. Линейные символы штрихового кода. Требования к испытаниям качества печати" модифицирован по отношению к ИСО/МЭК 15416-2000.
[17] | ISO/IEC 15417 <1>, Information technology - Automatic identification and data capture techniques - Bar code symbology specification - Code 128 (Информационные технологии - Технологии автоматической идентификации и сбора данных - Спецификация символики штрихового кода - Code 128) |
[18] | ИСО/МЭК 15424 <2> Information technology - Automatic identification and data capture techniques - Data Carrier Identifiers (including Symbology Identifiers) (Информационные технологии. Технологии автоматической идентификации и сбора данных. Идентификаторы носителей данных (включая идентификаторы символик)) |
[19] | ISO/IEC 15434 <3>, Information technology - Automatic identification and data capture techniques - Syntax for high capacity ADC media (Информационные технологии - Синтаксис передачи для средств автоматического сбора данных (ADC) большой емкости) |
[20] | ISO/IEC TR 29158 <4>, Information technology - Automatic identification and data capture techniques - Direct Part Mark (DPM) Quality Guideline (Информационные технологии - Технологии автоматической идентификации и сбора данных - Руководство по оценке качества прямого маркирования изделий) |
AIM ITS 97-001 International Symbology Specification - QR Code, AIM Inc (Международная спецификация символики - QR Code) | |
AIM International Technical Specification, Extended Channel Interpretations: - Part 1, Identification Schemes and Protocols (Международная техническая спецификация. Интерпретации в расширенном канале. Часть 1. Схемы идентификации и протокол) | |
[23] | AIM International Technical Specification, Extended Channel Interpretations: - Part 2, Registration Procedure for Coded Character Sets and Other Data Formats (Международная техническая спецификация. Интерпретации в расширенном канале. Часть 2. Процедура регистрации наборов кодированных знаков и других форматов данных) |
[24] | AIM International Technical Specification, Extended Channel Interpretations: - Character Set Register (Международная техническая спецификация. Интерпретации в расширенном канале. Регистр наборов знаков) |
[25] | GS1 General Specifications, GS1 (Общие спецификации GS1) |
[26] | JIS X 0208:2012, 7-bit and 8-bit double byte coded KANJI sets for information interchange (7-битовые и 8-битовые двухбайтовые кодированные наборы знаков КАНДЗИ для обмена информацией) |
--------------------------------
<1> ГОСТ ISO/IEC 15417-2013 "Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода Code 128" идентичен по отношению к ИСО/МЭК 15417.
<2> Может быть использован ГОСТ Р 51294.1-99 "Автоматическая идентификация. Кодирование штриховое. Идентификаторы символик".
ИС МЕГАНОРМ: примечание. ГОСТ Р ИСО/МЭК 15434-2007 утратил силу с 01.06.2022 в связи с введением в действие ГОСТ 34731-2021 (Приказ Росстандарта от 22.06.2021 N 571-ст). |
<3> ГОСТ Р ИСО/МЭК 15434-2007 "Автоматическая идентификация. Синтаксис для средств автоматического сбора данных высокой емкости" идентичен по отношению к ISO/IEC 15434:2006.
<4> Р 50.1.081-2012 "Информационные технологии. Технологии автоматической идентификации и сбора данных. Рекомендации по прямому маркированию изделий (ПМИ)" идентичен ИСО/МЭК ТО 29158 (ISO/IEC TR 29158).