МИНИСТЕРСТВО
ПРИРОДНЫХ РЕСУРСОВ И ЭКОЛОГИИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральная служба по гидрометеорологии и
мониторингу
окружающей среды (Росгидромет)
|
РЕКОМЕНДАЦИИ |
Р |
МЕТОДЫ ПРОГНОЗИРОВАНИЯ ИЗМЕНЕНИЯ
СОДЕРЖАНИЯ
ЗАГРЯЗНЯЮЩИХ ВЕЩЕСТВ В ВОДНЫХ ОБЪЕКТАХ
ВО ВРЕМЕНИ ПО РЕЗУЛЬТАТАМ СИСТЕМАТИЧЕСКИХ
ГИДРОХИМИЧЕСКИХ НАБЛЮДЕНИЙ
Ростов-на-Дону
2011
Предисловие
1 РАЗРАБОТАНЫ Государственным учреждением Гидрохимический институт (ГУ ГХИ)
2 РАЗРАБОТЧИКИ О.А. Клименко, канд. хим. наук; В.Ф. Геков, канд. тех. наук; О.В. Сергеева; В.А. Максимова (ГУ «Нижегородский ЦГМС-Р»)
3 СОГЛАСОВАНЫ с ГУ «НПО «Тайфун» 24.02.2011
и УМЗА Росгидромета 11.04.2011
4 УТВЕРЖДЕНЫ Заместителем Руководителя Росгидромета 12.04.2011
5 ЗАРЕГИСТРИРОВАНЫ ГУ «НПО «Тайфун» за номером РД 52.24.755-2011 от 22.04.2011
6 ВВЕДЕНЫ ВПЕРВЫЕ
СОДЕРЖАНИЕ
Р 52.24.755-2011
РЕКОМЕНДАЦИИ
МЕТОДЫ ПРОГНОЗИРОВАНИЯ ИЗМЕНЕНИЯ
СОДЕРЖАНИЯ
ЗАГРЯЗНЯЮЩИХ ВЕЩЕСТВ В ВОДНЫХ ОБЪЕКТАХ
ВО ВРЕМЕНИ ПО РЕЗУЛЬТАТАМ СИСТЕМАТИЧЕСКИХ
ГИДРОХИМИЧЕСКИХ НАБЛЮДЕНИЙ
Дата введения - 2011-05-25
1 Область применения
Настоящие рекомендации распространяются на методы прогнозирования изменения содержания загрязняющих веществ в водных объектах во времени по результатам систематических гидрохимических наблюдений и предназначены для наблюдательных подразделений управлений и центров по гидрометеорологии и мониторингу окружающей среды Федеральной службы по гидрометеорологии и мониторингу окружающей среды, осуществляющих организацию и проведение наблюдений за состоянием поверхностных вод суши, а также оценку изменения качества воды водных объектов во времени.
Настоящие рекомендации могут быть использованы и в других заинтересованных организациях и учреждениях Росгидромета.
2 Нормативные ссылки
В настоящих рекомендациях имеются ссылки на следующие документы:
РД 52.24.622-2001 Методические указания. Проведение расчетов фоновых концентраций химических веществ в воде водотоков
Р 52.24.627-2007 Рекомендации. Усовершенствованные методы прогностических расчетов распространения по речной сети зон высокозагрязненных вод с учетом форм миграции наиболее опасных загрязняющих веществ.
3 Термины и определения
3.1 В настоящих рекомендациях применены следующие термины с соответствующими определениями:
3.1.1
|
водный объект: Сосредоточение природных вод на поверхности суши либо в горных породах, имеющее характерные формы распространения и черты режима. (ГОСТ 19179-73, пункт 6] |
3.1.2
|
водозабор: Забор воды из водоема, водотока или подземного водоисточника. [ГОСТ 19185-73, пункт 8] |
3.1.3
|
водоток: Водный объект, характеризующийся движением воды в направлении уклона в углублении земной поверхности. [ГОСТ 19179-73, пункт 15] |
3.1.4
|
загрязняющее воду вещество (загрязняющее вещество): Вещество в воде, вызывающее нарушение норм качества воды. [ГОСТ 17.1.1.01-77, пункт 40] |
3.1.5 ингредиент: Вещество или показатель, входящие в состав наблюденных характеристик водного объекта.
3.1.6
|
качество воды: Характеристика состава и свойств воды, определяющая пригодность ее для конкретных видов водопользования. [ГОСТ 17.1.1.01-77, пункт 4] |
3.1.7
|
нормы качества воды: Установленные значения показателей качества воды для конкретных видов водопользования. [ГОСТ 27065-86, пункт 3] |
3.1.8
|
река: Водоток значительных размеров, питающийся атмосферными осадками со своего водосбора и имеющий четко выраженное русло. |
3.1.9 створ водотока (реки): Условное поперечное сечение водотока, используемое для оценок и прогноза качества воды.
3.2 В настоящих рекомендациях приняты следующие сокращения:
БПК5 - биохимическое потребление растворенного кислорода содержащимися в воде органическими веществами в течение пяти суток;
ГСН - государственная сеть наблюдений;
ГУ УГМС - государственное учреждение «Управление по гидрометеорологии и мониторингу окружающей среды»;
ГУ ЦГМС - государственное учреждение «Центр по гидрометеорологии и мониторингу окружающей среды»;
ГХЦГ - гексахлорциклогексан;
ДДТ - дихлордифенилтрихлорэтан;
ЗВ - загрязняющее вещество;
КПХ - каталог постоянных характеристик;
ПДК - предельно допустимая концентрация;
ПК - персональный компьютер;
ПКН - перечень координатных номеров;
СПАВ - синтетические поверхностно активные вещества;
ХПК - химическое потребление кислорода.
4 Общие положения
4.1 В настоявших рекомендациях рассмотрены методы прогнозирования изменения содержания ЗВ во времени на основе накопленной ретроспективной информации о режиме химических веществ и показателей качества воды водного объекта в местах (точках) систематических гидрохимических наблюдений.
Ранее опубликованные работы [1], [2], и Р 52.24.627, посвященные методам оперативного прогнозирования изменения химического состава воды в водных объектах, были направлены, главным образом, на прогнозирование появления возможных опасных уровней загрязнения воды на контролируемых участках водных объектов в связи со стационарным и нестационарным поступлением ЗВ со сточными водами и водами притоков.
4.2 Используя результаты ретроспективных и текущих систематических гидрохимических наблюдений в створах, вертикалях и горизонтах, контролируемых ГУ УГМС (ГУ ЦГМС), на основе анализа закономерностей изменения содержания ЗВ во времени выбирают методы прогнозирования, а также заблаговременность прогноза изменения содержания этих веществ.
4.3 Для осуществления прогнозирования изменения во времени содержания ЗВ в водных объектах по результатам систематических наблюдений рекомендуется привлекать максимум накопленной ретроспективной и текущей информации по гидрохимическим и гидрологическим показателям.
4.4 С помощью разработанного программного комплекса, являющегося неотъемлемым приложением к данным рекомендациям, имеющуюся информацию о результатах наблюдения на водном объекте переносят в специализированную базу данных, на основе которой разрабатывают прогнозы изменения во времени значений отдельных интересуемых химических веществ и показателей качества воды.
4.5 Целью прогнозирования является определение на расчетный период (сутки, декада, месяц, год) ожидаемых осредненных концентраций заданных химических веществ с указанием возможного доверительного интервала их варьирования.
4.6 Результат прогноза следует считать неоправдавшимся, если по результатам наблюдения за расчетный период будет получена осредненная концентрация рассматриваемого вещества, выходящая за пределы указанного в результате прогноза доверительного интервала ее варьирования.
В конце года или другого специально оцениваемого периода оправдываемость совокупности составленных за этот период прогнозов η, %, может быть рассчитана по формуле
![]() (1)
(1)
где nпр - число оправдавшихся прогнозов;
Nпр - общее число прогнозов.
Расчеты по формуле (1) целесообразно проводить за периоды с общим числом прогнозов десять и более.
4.7 По материалам и алгоритмам, приведенным в разделах 5 - 7, разработан программный комплекс для ПК - «ГХМ-прогноз», который является неотъемлемой частью настоящих рекомендаций. В приложении А представлена инструкция для пользователей данного программного комплекса. В приложении Б приведены примеры прогнозирования изменения содержания ЗВ в водных объектах во времени.
5 Организация специализированной базы данных для проведения прогнозирования изменения содержания ЗВ в водных объектах во времени
5.1 Общие замечания
5.1.1 База данных - это совокупность сведений относящихся к определенной задаче, организованная таким образом, чтобы обеспечить удобное представление этой совокупности, как в целом, так и любой ее части.
Создаваемая для решения задач прогнозирования изменения содержания химических веществ в водных объектах по результатам систематических гидрохимических и гидрологических наблюдении специализированная база данных представляет собой множество взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного типа.
5.1.2 Для выполнения прогнозирования с помощью программных средств, всю совокупность требуемой информации можно разделить на следующие виды:
- справочная информация - это виды информации, которые редко изменяются (а если изменяются, то только в сторону добавления и расширения характеристик), и используются в основном для краткого представления сведений как некоторых цифровых кодов;
- основные данные - измеренные значения физико-химических и химических свойств воды водного объекта, на основе которых и осуществляется прогнозирование;
- вспомогательные данные - данные, описывающие и идентифицирующие основной вид информации, например, по географическому положению.
Представление данных в задачах прогнозирования как базы данных позволяет систематизировать информацию по ее назначению, обеспечивать подготовку и надежное хранение структурированной информации в соответствии с текущими задачами.
5.2 Требования к содержанию и структуре специализированных баз данных
5.2.1 В настоящее время в качестве системы управления, хранения и обработки гидрохимических данных в ГУ УГМС (ГУ ЦГМС) применяется программный комплекс «ГидрохимПК» (далее «ГидрохимПК»). База данных в этом комплексе имеет специальную структуру и недоступна для непосредственного просмотра в обычном текстовом редакторе. В связи с этим для обмена информации с другими базами такого же типа разработана стандартизованная структура текстового файла для данных и линейная структура для КПХ. Дополнительно в данном комплексе для функционирования базы данных применяется еще два текстовых файла, являющихся справочниками кодов ингредиентов и признаков качества измерений.
Файл базовых данных в «ГидрохимПК» сформирован по пробам воды, которые характеризуются местом и временем отбора пробы, причем время отбора указано с точностью до минуты.
Такая структура файла с указанием точного времени проведенного отбора проб воды существенно затрудняет дополнение первоначально зарегистрированных результатов наблюдения новыми значениями ингредиентов. Кроме того, при представлении данных, скомпонованных в виде проб воды, автоматизированное восполнение пробелов в наблюдениях становится невозможным. Учитывая, что для задач прогнозирования время измерения значений ингредиентов можно указывать не точнее, чем текущие сутки, и при обработке данных имеет значение только временной ряд ингредиента без разделения на пробы, целесообразно работать с упрощенной структурой данных, представленной в более простой форме - в виде строк, где приводятся значения ингредиента и характеризующие его параметры.
5.2.2 В целом разрабатываемые специализированные базы данных, предназначены для целей сохранения на диске подготовленных для прогнозирования результатов наблюдений в виде следующих текстовых файлов:
- справочник кодов ингредиентов;
- справочник характеристик качества измерений;
- справочник признаков значений;
- перечень координатных номеров (ПКН);
- результаты гидрохимических наблюдений.
Результаты гидрохимических наблюдений для использования в прогнозировании могут быть подготовлены в четырех видах:
а) как выборка из «ГидрохимПК» в формате файла обмена;
б) в виде специально подготовленных в «Microsoft Excel» (входящего в состав MS Office) таблиц с ежедневными расходами или значениями температуры речной воды (если таковые имеются) по данным наблюдений в ближайших створах гидрологических наблюдений (в створах гидропостов), в формате «*.xls»;
в) в виде специально подготовленных в «Microsoft Excel» таблиц с результатами систематических гидрохимических наблюдений в формате «*.xls»;
г) подготовленные выборки исходных данных в рассматриваемой внутренней базе данных программы прогнозирования с расширением «*.dan».
5.2.3 Подготовленные для выполнения прогнозирования данные рекомендуется хранить в формате с расширением «*.dan». Следует отметить, что используемые данные могут быть сформированы из данных, полученных в близлежащих створах, контролируемых с различной частотой отбора проб воды, но при условии использования методов химического анализа с равноточной чувствительностью.
5.2.4 Используемый в специализированной базе данных справочник кодов ингредиентов по содержанию и кодировке аналогичен справочнику кодов ингредиентов в «ГидрохимПК». Однако, такой справочник в «ГидрохимПК» представлен в кодировке 866 DOS Cyrillic, для рассматриваемой же системы прогностических оценок - в кодировке 1251 Cyrillic Windows.
Имя файла справочника кодов ингредиентов - «kod_ingr.win».
Содержание файла справочника кодов ингредиентов приведено в таблице 1.
Таблица 1 - Справочник кодов ингредиентов, используемых в специализированной базе данных результатов гидрохимических наблюдений
|
Полное наименование ингредиента |
Единица измерений ингредиента |
ПДК |
Код ингредиента |
|
|
Номер створ. |
Номер створа и вертикали |
- |
- |
1 |
|
Расход/уров. |
Расход/уровень |
куб.м/с |
- |
13 |
|
Прозрачн. |
Прозрачность |
см |
- |
25 |
|
Цвет. р-со. |
Цветность по р-со шкале |
градус |
- |
27 |
|
Температура |
Температура |
°С |
- |
29 |
|
Взвеш. в-ва |
Взвешенные вещества |
мг/л |
- |
31 |
|
рН |
рН |
- |
- |
33 |
|
Кислород |
Растворенный кислород |
мг/л |
6,0 |
35 |
|
Нас. кислор. |
Степень насыщения кислородом |
% |
37 |
|
|
Магний |
Магний |
мг/л |
40,0 |
43 |
|
Хлориды |
Хлориды |
мг/л |
300,0 |
45 |
|
Сульфаты |
Сульфаты |
мг/л |
100,0 |
47 |
|
Сумма ионов |
Сумма ионов |
мг/л |
1000 |
49 |
|
Жесткость |
Жесткость общая |
мг-экв/л |
- |
51 |
|
НСО3 |
Гидрокарбонаты |
мг/л |
- |
53 |
|
Натрий |
Натрий |
мг/л |
120 |
57 |
|
Калий |
Калий |
мг/л |
50,0 |
59 |
|
Кальций |
Кальций |
мг/л |
180 |
61 |
|
Окисл. перм. |
Окисляемость перманганатная |
мг/л |
- |
63 |
|
ХПК |
Окисляемость бихроматная |
мг/л |
30 |
65 |
|
БПК5 |
Биохимическое потребление кислорода за 5 суток |
мг/л |
2,0 |
67 |
|
Азот аммон. |
Азот аммонийный |
мг/л |
0,39 |
71 |
|
Азот нитрит. |
Азот нитритный |
мг/л |
0,02 |
73 |
|
Азот нитрат. |
Азот нитратный |
мг/л |
9,0 |
75 |
|
Фосфаты (Р) |
Фосфор фосфатов |
мг/л |
0,2 |
79 |
|
Эл-проводн. |
Электропроводность |
см/см |
- |
85 |
|
Фосфор общ. |
Фосфор общий |
мг/л |
- |
93 |
|
Железо общ. |
Железо общее |
мг/л |
0,1 |
111 |
|
Медь |
Медь |
мкг/л |
1,0 |
115 |
|
Цинк |
Цинк |
мкг/л |
10,0 |
117 |
|
Никель |
Никель |
мкг/л |
10,0 |
119 |
|
Хром общий |
Хром общий |
мкг/л |
30,0 |
121 |
|
Хром 6+ |
Хром 6+ |
мкг/л |
20,0 |
123 |
|
Хром 3+ |
Хром 3+ |
мкг/л |
70,0 |
125 |
|
Свинец |
Свинец |
мкг/л |
6,0 |
127 |
|
Ртуть |
Ртуть |
мкг/л |
0,01 |
137 |
|
Кадмий |
Кадмий |
мкг/л |
1,0 |
139 |
|
Алюминий |
Алюминий |
мкг/л |
40,0 |
147 |
|
Марганец |
Марганец |
мкг/л |
10,0 |
149 |
|
Мышьяк |
Мышьяк |
мкг/л |
50,0 |
151 |
|
Фенолы |
Фенолы |
мг/л |
0,001 |
177 |
|
Нефтепрод. |
Нефтепродукты |
мг/л |
0,05 |
181 |
|
СПАВ |
СПАВ анионактивные |
мг/л |
0,1 |
187 |
|
Фториды |
Фториды |
мг/л |
0,75 |
189 |
|
Цианиды |
Цианиды |
мг/л |
0,05 |
195 |
|
Сульфиты |
Сульфиты |
мг/л |
1,9 |
201 |
|
СПАВ неион. |
СПАВ неионогеннные |
мг/л |
0,5 |
213 |
|
Формальдег. |
Формальдегид |
мг/л |
0,01 |
243 |
|
Трихлорфон |
Хлорофос |
мкг/л |
0,02 |
309 |
|
ДДТ |
ДДТ |
мкг/л |
0,01 |
337 |
|
ГХЦГ |
ГХЦГ |
мкг/л |
0,01 |
343 |
|
Альфа-ГХЦГ |
Альфа-гексахлоран |
мкг/л |
0,01 |
349 |
|
Гамма-ГХЦГ |
Линдан |
мкг/л |
0,01 |
357 |
|
2,4-Д |
Даминовая соль |
мкг/л |
100 |
383 |
|
4-хлори угл. |
4-хлористый углерод |
мг/л |
10 |
410 |
|
Дихлорэтил. |
Дихлорэтилен |
мг/л |
0,1 |
412 |
|
Трихлорэтил. |
Трихлорэтилен |
мг/л |
0,1 |
413 |
|
Тетрахлорэт. |
Тетрахлорзтилен |
мг/л |
0,1 |
414 |
|
Щелочность |
Щелочность |
мг/л |
- |
418 |
Имя файла справочника характеристик качества измерений - «kach.win».
Содержание файла справочника характеристик качества измерений, приведено в таблице 2.
Таблица 2 - Характеристики качества измерений
|
Характеристика качества измерений |
|
|
0 |
Значение корректно |
|
1 |
Значение восстановлено |
|
2 |
Значение сомнительно |
|
3 |
Значение забраковано |
|
9 |
Контроль не проводился |
5.2.6 Включенный в специализированную базу данных справочник признаков представляет собой перечень характеристик, учитывающих степень пригодности исходных данных для прогнозирования, а также их коды.
Имя файла справочника признаков значений - «prizn.win».
Состав справочника приведен в таблице 3.
Таблица 3 - Характеристика признака значения ингредиента
|
Характеристика признака значения |
|
|
0 |
Нормальное |
|
1 |
Восстановленное |
|
2 |
Сомнительное |
|
3 |
Забракованное |
|
4 |
Не использовать для прогноза |
|
5 |
Временно восстановленное |
5.2.7 Файл перечня координатных номеров должен содержать описания, характеризующие створы отбора проб воды в водном объекте и соответствующие им координатные номера. Следует отметить, что массивы данных измерений концентраций веществ, температуры и расхода воды могут быть получены разными ведомствами, имеющими свои системы характеристик мест наблюдения. Это не позволяет применять каталоги поисковых характеристик (КПХ), которые используют в настоящее время в базе данных в системе Росгидромета.
Файл перечня координатных номеров готовят в любом текстовом редакторе Windows и затем первый раз загружают в программный комплекс.
Файлу перечня координатных номеров присваивают расширение вида *.pkn.
Примечание - Для правильного составления файла перечня координатных номеров достаточно привести на первом месте в строке координатный номер и отделить от текста, характеризующего вертикаль отбора пробы, пробелом. Текст же в строке файла не должен превышать 80 символов. Индексы при координатных номерах ГСН обозначают следующее: р - поверхностный горизонт; s - средний по глубине горизонт; d - придонный горизонт.
Пример файла перечня координатных номеров створов наблюдения, выполняемых разными ведомствами, приведен в таблице 4.
Таблица 4 - Перечень координатных номеров створов, включенных в специализированную базу данных
|
102000000р р. Ока, г. Богородск, Богородский водозабор 543003940s р. Ока, г. Рязань, Рязанский водозаб., 13 км выше гор. 552004300р р. Ока, г. Павлово, в черт. гор., в 0,8 км ниже водозаб. 553004200р р. Ока, г. Муром, 4 км выше гор., 9 км выше гидроп. 560004300р р. Ока, г. Горбатов, створ гидропоста в черте города 561004333р р. Ока, г. Дзержинск, 5 км выше города 561004350р р. Ока, г. Н. Новгород, 16 км выше города |
5.2.8 Данные гидрохимических наблюдений - это данные, на основе которых осуществляется прогнозирование. Эти данные могут быть представлены в различных форматах, в зависимости от условий их подготовки. Наличие нескольких форматов понимаемых программой исходных данных увеличивает удобство использования программного комплекса и расширяет область его применимости.
6 Методика прогнозирования изменения содержания ЗВ в водных объектах во времени по результатам систематических гидрохимических наблюдений
6.1 Выборка из системы «ГидрохимПК» в формате файла обмена
В системе Росгидромета основным форматом для данных о загрязнении поверхностных вод суши является файл с расширением [*.dat] для обмена данными в «ГидрохимПК». Для подготовки данных, используемых в прогнозировании, осуществляется их выборка из «ГидрохимПК» по правилам, указанным в описании пользования этой системой. Полученный файл может быть загружен в программу прогнозирования. При этом произойдет изменение формата данных и дополнение их недостающими характеристиками (признаками значений по умолчанию).
6.2 Специально подготовленные таблицы в «Excel»
Ежедневные данные, полученные любым ведомством, могут быть подготовлены для ввода в специализированную базу в виде таблиц Excel. Этот формат применяется для быстроты ввода, контроля полноты данных, а также удобства работы оператора, вводящего данные. В рассматриваемом программном комплексе также предусмотрено автоматическое приведение указанного формата к основному и дополнение его новой недостающей информацией.
Образец структуры информации в виде таблиц Excel для расходов речной воды приведен в приложении В, для гидрохимической информации такой образец в виде файла «Образец занесения гидрохимических данных в Excel» прилагается к программному обеспечению.
6.3 Формат гидрохимических данных в программе прогнозирования
Рассматриваемый формат файла формируется при выборках из внутренней базы данных программы. Структура файла следующая:
- тип файла - текстовый;
- каждое значение ингредиента представляется отдельной строкой;
- каждый элемент строки отделяется, по крайней мере, одним пробелом от последующего;
- значение и строка ингредиента в структуре текстового файла характеризуется координатным номером (координатный номер описывается в файле перечня координатных номеров);
- код ингредиента устанавливается в соответствии с «kod ingr.win»;
- дата отбора пробы воды, содержащей данный ингредиент; представляет собой вещественное число, в целой части которого содержится количество суток, прошедших с 30 декабря 1899 г., а дробная часть - доля текущих суток; данный формат типовой для Windows;
- значение ингредиента - строка ингредиента в структуре текстового файла, идентифицируется кодом ингредиента (код в соответствии со справочником кодов ингредиентов);
- каждое значение ингредиента характеризуется качеством измерений;
- каждое значение ингредиента характеризуется его признаком для целей прогнозирования.
7 Теоретические основы проведения прогнозирования изменения содержания ЗВ в водных объектах во времени по результатам ретроспективных и текущих наблюдений
7.1 Общие замечания
7.1.1 Вид результата и задаваемые сроки заблаговременности расчета ожидаемых по прогнозу значений ингредиента зависят от полноты полученной исходной информации об изменении этого ингредиента во времени.
Если в наличии имеются результаты ежедневных наблюдений, то возможно прогнозирование суточных, среднедекадных, среднемесячных, среднесезонных и среднегодовых значений контролируемых ингредиентов. При наличии многолетних ежемесячных наблюдений (в том числе с учетом восстановленных данных) возможно прогнозирование среднесезонных, среднегодовых и ориентировочный прогноз ожидаемых среднемесячных значений ингредиентов. При наличии многолетних сезонных наблюдений (не более четырех - пяти раз в год) возможен только ориентировочный прогноз среднегодовых значений ингредиента и весьма ориентировочный прогноз ожидаемых его значений для тех календарных месяцев, в которых имеется непрерывный (по годам) временной ряд данных. По полученным разрозненным прогнозным месячным значениям возможен весьма ориентировочный прогноз ожидаемых среднесезонных значений.
При наличии результатов ежедневных наблюдений (с учетом восстановленных данных) для прогнозирования среднемесячных данных можно использовать как модальные, так и медианные (данные с обеспеченностью Р = 50 %) значения ингредиента, полученные в каждом привлекаемом для расчета календарном месяце. В случае меньшего (малого) количества исходных данных для указанной цели рекомендуется использовать только медианные месячные значения. Если для экстраполяции берется исходный временной ряд, в котором в каждом месяце число данных равно трем или двум, то для прогнозирования используют среднеарифметические месячные данные. При наличии не более одного наблюдения в месяц (с учетом восстановленных рядов месячных данных) для составления ориентировочных прогнозов разовые наблюдения в месяце условно принимаются за среднемесячные.
7.1.2 В тех случаях, когда в одном или в нескольких близкорасположенных створах систематических наблюдений имеются часто и редко контролируемые ингредиенты, то в целях расширения возможностей прогнозирования рекомендуется проведение корреляционного анализа для определения наличия и тесноты статистический связей между значениями часто и редко контролируемых ингредиентов. При наличии достоверных статистических связей между указанными компонентами имеется возможность проводить прогнозирование изменения во времени значений редко измеряемых ингредиентов с той же заблаговременностью, что и часто измеряемых.
7.1.3 В качестве погрешности результата прогноза (возможного доверительного интервала варьирования ожидаемого по прогнозу значения ингредиента) рекомендуется:
- при прогнозировании среднедекадных, среднемесячных и среднегодовых значений ингредиента использовать полученные путем экстраполяции выбранным методом прогноза на заданный срок обеспеченные на 20 % и 80 % его значения (соответственно в каждой декаде или месяце должно быть не менее четырех измерений);
- при прогнозировании суточных значений ингредиента использовать погрешность его значений, полученную по выбранному для экстраполяции уравнению регрессии при доверительной вероятности Р = 0,95;
- при любых видах прогнозирования при отсутствии достоверной статистической связи между значениями ингредиента и временем измерения (или значениями другого часто измеряемого ингредиента) и наличии в рассматриваемом ряду менее четырех его значений использовать крайние интервалы варьирования значений ингредиента.
7.1.4 Для прогнозирования весьма желательно использовать не один, а несколько методов экстраполяции, каждый из которых достаточно объективно аппроксимирует на ретроспективных данных изменение значений рассматриваемого ингредиента во времени на интересуемую дату расчета. При этом в качестве окончательного результата прогноза представляют непротиворечивые по результатам визуального контроля осредненные данные, рассчитанные по нескольким использованным методам прогнозирования.
7.2 Корректировка исходных данных
7.2.1 Выделение и изъятие аномальных и ошибочных значений ингредиентов. Восполнение пробелов в результатах наблюдений
7.2.1.1 Корректировка первичных данных является очень важным и ответственным этапом при подготовке исходной информации для прогнозирования. Основная цель ее заключается в том, чтобы исключить и не включать в прогноз и расчеты по восполнению пробелов данных ошибочные и нехарактерные значения контролируемых веществ и показателей химического состава воды водного объекта.
7.2.1.2 Для корректировки исходной информации выполняется визуальный просмотр временных рядов данных, представленных в виде таблиц или точечных графиков. Нехарактерные данные выделяются («флагируются») путем присвоения кодового признака в соответствии с характеристиками наблюденных значений ингредиента, приведенными в таблице 3.
7.2.1.3 Если сомнительное значение ингредиента во временном ряду данных занимает место до или после отсутствующего результата наблюдений, то это значение целесообразно изъять из ряда данных, поскольку в процессе восстановления данных будут получены некорректные восстановленные значения ингредиента.
7.2.1.4 Восполнение пробелов в наблюденных значениях ингредиентов необходимо:
- для возможности достаточно обоснованно применять при прогнозировании адаптивные методы экстраполяции возможных изменений значений ингредиентов;
- для возможности более корректно рассчитывать и использовать в оценках качества воды такие статистические характеристики как средняя, мода и медиана.
7.2.1.5 После изъятия из временного ряда нехарактерных значений рассматриваемого вещества можно провести восполнение пробелов в результатах наблюдений.
Для начала работы по восстановлению данных составляют (программными средствами) и просматривают таблицу со сроками и количеством пропущенных данных.
На следующем этапе устанавливают, какой временной ряд данных целесообразно использовать для прогнозирования: в виде среднесуточных, среднедекадных, среднемесячных, среднесезонных или среднегодовых значений.
Далее решают следующие задачи:
- выбирают интервалы времени внутри конкретного года или многолетия (ряд лет), в которых будет выполняться восстановление данных;
- определяют вначале ориентировочно, а затем на основании табличных данных минимально и максимально допустимый во времени интервал пропусков данных и устанавливают временной шаг для восстановления данных. При суточных наблюдениях временной шаг можно принять равным одним суткам, при примерно декадных наблюдениях - 10 сут, при месячных - 30 сут;
- исходя из графика изменения концентрации вещества во времени, устанавливают количество данных до и после пропуска для проведения интерполяционных расчетов с использованием различных способов линеаризации временного ряда данных с помощью статистических зависимостей типа «концентрация - время». Лучшую из таких статистических связей автоматически (программными средствами) выбирают и используют для восстановления пропущенных данных. Далее на графике просматривают восстановленные данные (отмеченные красным цветом) и подтверждают или отменяют проведенное восстановление. Если необходимо, восстановление данных повторяют несколько раз, изменив или оставив тот же временной шаг и количество учитываемых данных до и после пропуска наблюдений.
Сформированные (откорректированные) временные ряды данных по отдельным ингредиентам желательно запомнить в виде новых отдельных файлов с расширением «*.dan».
При проведении восстановления данных программными средствами рекомендуется учитывать следующее:
- для ежедневных данных восстановление теряет смысл при пропусках подряд более декады; при наличии таких пропусков нужно переходить на среднедекадный шаг восстановления данных и прогнозирования (тем не менее, по инициативе оператора в таблице исходных данных восстановление таких пропусков на основе экспертных оценок может быть выполнено «вручную»);
- восстановление программными средствами подекадного ряда данных целесообразно, если в период половодья подряд имеются пропуски не более двух, а в остальной период не более трех декад; при наличии пропусков большей продолжительности целесообразен переход к восстановлению и прогнозированию среднемесячных данных (тем не менее, по инициативе оператора возможно восстановление таких пропусков «вручную» на основе экспертных оценок);
- восстановление программными средствами помесячного ряда данных целесообразно, если в период половодья подряд имеются пропуски не более одного, а в остальной период не более трех месяцев; при наличии пропусков большей длительности целесообразен переход на восстановление и прогнозирование среднегодовых данных (по инициативе оператора возможно восстановление указанных пропусков «вручную» на основе экспертных оценок).
7.3 Рекомендуемые методы прогнозирования
7.3.1 Метод прогнозирования по результатам анализа тенденций (трендов) изменения значений ингредиента во времени
7.3.1.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения интересуемого створа систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (включая его код), для которого будет выполняться прогностический расчет;
в) временной ряд значений ингредиента (данные могут быть представлены в виде суточных, среднедекадных, среднемесячных или среднегодовых значений) с указанием в соответствии с усреднением данных даты съемки в годовом цикле, месяца или года, к которому относится значение ингредиента в ряду исходных данных;
Примечание - Если задачей является определение статистической связи между значениями двух ингредиентов, то в роли функции выступает редко измеряемый ингредиент, в роли аргумента - часто измеряемый ингредиент.
г) заданный срок, на который требуется составить прогноз.
Примечание - Если для прогнозирования используется статистическая связь между ингредиентами, то в качестве дополнительной информации может быть указано прогнозное значение часто измеряемого ингредиента.
В основу метода положен корреляционный анализ зависимости между значениями рассматриваемого ингредиента и значениями временных характеристик (конкретные годы, календарные месяцы, декады или сутки).
Примечание - В статистических связях во временном ряду данных в качестве временных характеристик используют: в декадах - значения середины календарной декады, в месяцах - значения середины календарного месяца.
7.3.1.2 Выполняют поиск уравнения регрессии, которое наиболее представительно характеризует линеаризированную статистическую связь между коррелируемыми признаками (между значениями ингредиента и значениями времени или между значениями часто и редко измеряемых ингредиентов), с использованием 16 видов уравнений [2], [3] и РД 52.24.622:
|
l) y = a + bx, |
7) |
13) |
|
|
2) y = a + bx2, |
8) |
14) |
|
|
3) |
9) y = abx, |
15) |
(2) |
|
4) y = a + blgx, |
10) |
16) |
|
|
5) |
11) y = ab1/x, |
||
|
6) |
12) y = axb, |
7.3.1.3 Статистическую связь принимают значимой, если она удовлетворяет параметрам, приведенным в таблице 5.
Таблица 5 - Критерии оценки качества статистических связей
|
Коэффициент корреляции r |
|
Категория качества |
|
|
≤ 15 |
≥ 0,91 |
≤ 0,40 |
Хорошая |
|
0,80 - 0,70 |
0,41 - 0,70 |
Удовлетворительная |
|
|
15 < n < 25 |
≥ 0,89 |
≤ 0,45 |
Хорошая |
|
0,88 - 0,66 |
0,46 - 0,75 |
Удовлетворительная |
|
|
> 25 |
≥ 0,87 |
≤ 0,50 |
Хорошая |
|
0,86 - 0,60 |
0,51 - 0,80 |
Удовлетворительная |
В таблицу 5 включены параметры:
n - число пар значений зависимой и независимой переменных, использованных для установления статистической связи;
σ - среднее квадратическое отклонение, определяемое для анализируемого ряда значений ингредиента по формуле
 (3)
(3)
![]() - средняя квадратичная погрешность проверочных расчетов значений
ингредиента по найденному уравнению регрессии, определяемая по формуле
- средняя квадратичная погрешность проверочных расчетов значений
ингредиента по найденному уравнению регрессии, определяемая по формуле
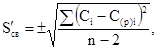 (4)
(4)
где С(p)i - значение ингредиента, полученное по уравнению регрессии на ту дату, когда была зафиксирована величина Сi.
Коэффициент корреляции r при линейной связи между параметрами Сi и Тi определяют по формуле
 (5)
(5)
где Сi, Ti - i-e значения коррелируемых ингредиентов;
Сср, Тср - среднеарифметические значения этих ингредиентов.
Если при линеаризации
статистической связи значения ингредиентов Ci и Тi брались в измененном виде (например: lgCi; ![]()
![]()
![]() ), то в формуле (5) их i-e значения следует брать в таком же измененном виде.
), то в формуле (5) их i-e значения следует брать в таком же измененном виде.
Для выполнения прогнозирования выбирают то уравнение, при расчетах по которому будет получено наименьшее отклонение расчетных данных от измеренных в действительности.
7.3.1.4 Возможную погрешность прогнозных значений ингредиента по найденному уравнению регрессии вычисляют по формуле
где tSt - коэффициент Стьюдента при Р = 0,95.
При использовании данного метода прогнозирования следует обращать внимание на следующее:
- для построения тренда изменения концентраций вещества во времени (на основе осредненных или единичных значений) оператором произвольно выбирается такой исходный предпрогнозный период, в пределах которого имеет место относительно небольшая амплитуда изменения значений ингредиента с однозначной тенденцией изменения концентрации, характеризующей либо её постепенное возрастание, либо снижение;
- указанные периоды для каждого ингредиента специфичны и должны быть заранее определены в пределах годового цикла или многолетия на основе анализа изменчивости концентрации конкретного вещества (при использовании ряда, состоящего из месячных данных, рассматриваемый метод целесообразно применять в пределах годового цикла с учетом особенностей изменения содержания рассматриваемого вещества, например, до прохождения пика половодья или после пика половодья; до или после окончания ледостава);
- оператором произвольно назначается метод прогнозирования среднемесячных значений ингредиента либо с использованием временных рядов данных только по интересуемому календарному месяцу, либо по выбранному временному периоду всего ряда месячных данных (для прогнозирования можно использовать оба метода поочередно).
7.3.2 Методы адаптивного прогнозирования
7.3.2.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения интересуемого створа систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (включая его код), для которого будет проводиться прогнозирование;
в) временной ряд значений ингредиента (данные могут быть представлены в виде суточных, среднедекадных, среднемесячных или среднегодовых значений) с указанием календарной даты суток, календарной даты середины декады, месяца в годовом цикле или года, к которому относится значение ингредиента в ряду исходных данных;
г) заданный срок, на который требуется составить прогноз.
Каждый из временных рядов измеренных значений ингредиента можно представить в виде суммы детерминированного временного ряда (тренда) и случайной составляющей временного ряда с нулевым математическим ожиданием. Для разложения исходного временного ряда на составляющие предпочтителен такой эффективный и наиболее часто применяемый метод как экспоненциальное сглаживание [4]. В основе этого метода лежит расчет экспоненциальных средних. Чем более глубокое сглаживание производят, тем более гладкая долгодействующая закономерность динамики ряда выделяется в тренд, но при этом и большая часть вариаций исходного ряда включается в случайную составляющую. Соответственно, для более глубокого сглаживания необходима и большая длина предыстории исходного временного ряда [4].
Выделяемый тренд, экстраполяцией которого осуществляется прогнозирование на небольшое количество интервалов измерений, представляет собой достаточно гладкую функцию времени и с приемлемой точностью может быть представлен полиномом. Для осуществления прогнозирования с упреждением на малое число интервалов измерений с удовлетворительной оправдываемостью выделяемый тренд может быть аппроксимирован полиномами до 2-й степени. В связи с этим для прогнозирования изменений значений контролируемых ингредиентов во времени были использованы методы, основанные на экспоненциальном сглаживании исходных временных рядов с экстраполяцией полиномами не выше второй степени. Р. Брауном [4] разработана процедура адаптации коэффициентов полиномов при каждом получении новой фактической точки временного ряда. При этом за начало отсчета времени принимают текущий момент составления прогноза. Прогнозируемое на число периодов времени измерения Т значение временного ряда X определяют:
- для полиномиальной модели нулевого порядка в соответствии с выражением
Х(Т) = В1; (7)
- первого порядка
Х(Т) = В1 + В2Т; (8)
- второго порядка
Х(Т) = В1 + В2Т + 0,5В3Т(Т - 1). (9)
Адаптацию коэффициентов полиномиальных моделей В1, В2 и В3, а также пересчет начала отсчета для получения при прогнозировании очередного значения временного ряда осуществляют следующим образом:
- для модели нулевого порядка
В1 = В1с + αЕt; (10)
- для модели первого порядка
В1 = В1с + В2с + α(2 - α)Еt, (11)
В2 = В2с + α2Еt; (12)
- для модели второго порядка
B1 = B1c + B2c + (3α - 3α2 + α3)Et, (13)
В2 = B2c + B3c + (3α2 - α3)Еt, (14)
B3 = B3c + α3Et; (15)
где В1, В2, В3 - «новые» значения коэффициентов;
B1c; B2c; B3c - «старые» значения коэффициентов;
Еt - ошибка прогноза, при получении очередной точки временного ряда на 1 шаг вперед (Т = 1);
α - константа сглаживания.
Для быстрой подстройки коэффициентов модели прогнозирования, в моменты резких изменений среднего уровня временного ряда используют модификацию Тригга-Лича [4], заключающуюся в подсчете величины следящего контрольного сигнала. Следящий контрольный сигнал К представляет собой сумму сглаженных ошибок прогнозирования D1 деленную на сумму сглаженных модулей ошибок прогнозирования D2:
K = |D1/D2|, (16)
D1 = (1 - γ)D1 + γEt, (17)
D2 = (l - γ)D2 + γ|Et|; (18)
где γ - постоянная сглаживания (γ = 0,35).
В рассматриваемом случае обновление коэффициентов полиномиальных моделей выполняют в соответствии с выражениями:
- для моделей нулевого порядка
В1 = В1с + КЕt, (19)
- для моделей первого порядка
В1 = В2с + В2,с + КЕt, (20)
В2 = В2с + α2Еt; (21)
- для моделей второго порядка
B1 = B1c + B1c + KEt, (22)
В2 = В2c + В3с + α2(3 - α)Et, (23)
B3 = B3c + α3Et. (24)
Величина следящего контрольного сигнала при резких (внезапных) значительных изменениях среднего уровня ряда становится близка к единице и при обновлении коэффициента В1 максимально учитывается ошибка прогноза на один шаг - Еt.
К положительным свойствам реализации данного метода прогнозирования на один или несколько шагов вперед можно отнести следующее: в основе метода лежит простая, логичная и легко понимаемая концепция, оптимальное значение единственного параметра α можно быстро найти эмпирическим путем (по результатам оценочных прогнозов на различных водных объектах оптимальный результат чаще всего получался при значениях α = 0,7 и γ = 0,35), коэффициенты полиномов оцениваются совместно таким образом, чтобы уменьшить автокорреляцию в остатках. Анализируя результаты апробации разработанного программного комплекса на основе различных видов исходной ретроспективной информации, можно констатировать, что для снижения погрешности результатов прогнозирования нередко (особенно в пределах периодов, когда меняется направленность изменения концентраций ЗВ) оказывается целесообразным снижение численного значения параметра α до появления устойчивых более низких значений погрешности прогноза, не противоречащих изменчивости и дисперсии данных в исходном временном ряду (анализ погрешностей выполняют визуально по результатам прогноза, которые при использовании программных средств появляются на графике рассматриваемого временного ряда).
7.3.2.2 Для ингредиента, выбранного для прогнозирования, по данным начального временного ряда программными средствами находят начальные значения коэффициентов выбранной полиномиальной модели методом наименьших квадратов. После получения очередного значения ингредиента, коэффициенты выбранной полиномиальной модели программными средствами пересчитывают (адаптируют) и, считая момент времени последнего измерения за начало отсчета, осуществляют прогноз значения ингредиента на заданный период.
7.3.2.3 Доверительный интервал результатов прогноза получают следующим образом:
а) рассчитывают среднее квадратическое отклонение наблюденных данных от расчетных S'св, полученных для каждого элемента рассматриваемого динамического ряда по формуле (4);
б) в случае использования полиномиальной модели Брауна нулевого порядка дисперсия результатов прогноза определяют по выражению
в) в случае использования модели первого порядка дисперсия результатов прогноза составит
D1 = [1 + 1,25α(2 - α) + α2(2 - α)2τ](S'св)2; (26)
г) для модели второго порядка -
D2 = (1 + 2α1 + 3α12τ + 3α13τ2)(S'cв)2. (27)
В формулах (25) - (27): α - постоянная сглаживания; τ - время упреждения (число шагов);
α1 = α[3 - α(3 - α)]. (28)
Доверительный интервал результата прогноза определяется как
![]() ; i
= 0, 1, 2 (29)
; i
= 0, 1, 2 (29)
где tSt - коэффициент Стьюдента при Р = 0,95 (таблица 6);
Таблица 6 - Значения коэффициента Стьюдента tSt при односторонней доверительной вероятности Р = 0,95
|
n - 1 |
tSt |
n - 1 |
tSt |
n - 1 |
tSt |
|
5 |
2,02 |
20 |
1,72 |
40 |
1,68 |
|
6 |
1,94 |
21 |
1,72 |
42 |
1,68 |
|
7 |
1,90 |
22 |
1,72 |
44 |
1,68 |
|
8 |
1,86 |
23 |
1,71 |
46 |
1,68 |
|
9 |
1,83 |
24 |
1,71 |
48 |
1,68 |
|
10 |
1,81 |
25 |
1,71 |
50 |
1,68 |
|
11 |
1,80 |
26 |
1,71 |
55 |
1,67 |
|
12 |
1,78 |
27 |
1,70 |
60 |
1,67 |
|
13 |
1,77 |
28 |
1,70 |
65 |
1,67 |
|
14 |
1,76 |
29 |
1,70 |
70 |
1,67 |
|
15 |
1,75 |
30 |
1,70 |
80 |
1,66 |
|
16 |
1,75 |
32 |
1,69 |
90 |
1,66 |
|
17 |
1,74 |
34 |
1,69 |
100 |
1,66 |
|
18 |
1,73 |
36 |
1,69 |
120 |
1,66 |
|
19 |
1,73 |
38 |
1,69 |
||
|
Примечание - При n < 5 принимается tSt = 1. |
|||||
Адаптивный метод нулевого порядка рекомендуется использовать в тех случаях, когда изменение значений ингредиента в пределах рассматриваемого периода имеет горизонтальную направленность (достоверная статистическая связь изменения значений ингредиента во времени, как правило, отсутствует). Уровень такой направленности во времени может претерпевать некоторые изменения (например, резкий переход значений временного ряда на новый горизонтальный уровень без изменения какой-либо устойчивой вертикальной динамики тенденции).
Адаптивный метод первого порядка рекомендуется использовать в тех случаях, когда угол направленности тенденции линейного изменения значений ингредиента во времени меняется медленно (нет больших отклонений от характерной направленности значений временного ряда в пределах выбранного периода). Характеру изменения значений ингредиента к концу периода придается более высокое значение путем присвоения более высоких значений весовых коэффициентов перед соответствующими слагаемыми в полиномиальной связи. Обычно этот метод можно использовать совместно с методом построения тренда изменения концентраций вещества во времени.
Адаптивный метод второго порядка рекомендуется использовать в тех случаях, когда имеет место высокие темп смены направленности тенденции изменения значений ингредиента во времени (часто встречаются большие отклонения от общей направленности значений временного ряда в пределах выбранного периода). Результат прогноза чаще всего отражает максимально возможный рост или снижение значений ингредиента на заданную дату прогнозирования.
7.3.3 Метод прогнозирования по тренду с учетом сезонной - составляющей
7.3.3.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (включая его код), для которого будет осуществляться прогнозирование;
в) временной ряд значений ингредиента (данные должны быть представлены в виде суточных или среднедекадных значений) с указанием календарной даты суток или декады (середины соответствующей декады) в годовом цикле;
г) заданный срок, на который требуется составить прогноз.
Использование данного метода прогнозирования возможно только при наличии сведений о ежедневных или среднедекадных данных (в том числе восстановленных) за период не менее полных трех лет. При выделении сезонной составляющей рекомендуется брать периодичность сезонов - один год. Для исходного временного ряда в сутках это составляет 365 значений ингредиента на один временной период, в декадах - 36.
7.3.3.2 Предварительно до выполнения прогнозирования строят точечный график «значение ингредиента - время». По графику визуально выбирают временной период продолжительностью не менее трех последних лет, включающий все результаты текущих наблюдений.
7.3.3.3 Для определения сезонной составляющей на основе исходного временного ряда значений ингредиента сначала определяют типовую сезонную составляющую на 1 год, а затем на ее основе сезонную составляющую пролонгируют на весь выбранный срок наблюдений. Данную процедуру выполняют следующим образом. На основе всех значений выбранного временного ряда вычисляют среднее арифметическое значение ингредиента. Затем формируют массивы значений ингредиента для типового сезона, начиная с первой точки (значение ингредиента в ней соответствует определенной дате годового цикла). Массив для первой точки формируют из значений ингредиента на рассматриваемую дату за все годы выбранного срока наблюдений с шагом, равным одному периоду (1 году). По построенному массиву определяют среднюю величину этого массива и из нее вычитают среднее значение ингредиента всего исходного временного ряда. Так определяют первую точку выделяемой типовой сезонной составляющей. Далее аналогичным образом определяют значения для всех точек в годовом цикле. В результате расчета получают все значения типовой сезонной составляющей в годовом цикле.
Для получения сезонной составляющей всего исходного временного ряда точки типового сезона повторяют сдвигом типового сезона на его период (1 год), сдвиг повторяют до тех пор, пока сезонная составляющая не заполнит весь исходный временной период.
7.3.3.4 В целях определения временного ряда «остатков» из каждого значения исходного временного ряда вычитают соответствующее ему рассчитанное значение сезонной составляющей.
Для получения всех характеристик исходного временного ряда, которые можно использовать для прогнозирования, дополнительно следует разложить временной ряд «остатков» на тренд и случайный временной ряд, имеющий нормальное распределение с нулевым значением средней. При этом тренд можно выделить как выбором оптимальной кривой на основе метода наименьших квадратов, так и одним из методов адаптивного прогнозирования.
7.3.3.5 В результате рассмотренной выше процедуры исходный временной ряд разделяется на три составляющих: сезонную составляющую, тренд и случайный временной ряд остатков. Непосредственно прогнозирование выполняют пролонгированием сезонной составляющей и тренда на заданный период (шаг) прогнозирования изменения значения ингредиента. Ожидаемое по прогнозу значение ингредиента определяют как сумму рассчитанных значений по сезонной составляющей и по тренду.
В качестве возможной погрешности прогноза берут границы варьирования значений временного ряда остатков.
7.3.3.6 Значимость сезонной составляющей в изменении значений интересуемого ингредиента (и, соответственно, необходимости выделения сезонной составляющей для повышения точности прогноза) оценивают следующим образом. По данным исходного временного ряда выделяют тренд и дисперсию отклонений от него значений временного ряда (в общем случае нелинейного). Затем определяют тренд временного ряда «остатков» и дисперсию отклонений от него значений временного ряда «остатков» (также в общем случае нелинейного). Значимость вклада сезонной составляющей оценивают путем проверки гипотезы о равенстве двух дисперсий, опираясь на совместный закон распределения оценок двух дисперсий, которым является F-распределение, называемое распределением Фишера-Снедекора, при доверительной вероятности Р = 90 %:
![]() (30)
(30)
где ![]() - дисперсия
отклонений исходных (наблюденных) данных от полученных по уравнению тренда
временного ряда этих данных;
- дисперсия
отклонений исходных (наблюденных) данных от полученных по уравнению тренда
временного ряда этих данных;
![]() - дисперсия значений
временного ряда «остатков» с учетом выделения сезонной составляющей.
- дисперсия значений
временного ряда «остатков» с учетом выделения сезонной составляющей.
Полученное значение F-критерия сравнивают с табличным при Р = 0,90 (уровень значимости q = 0,1) и при условном обеспеченном минимуме числа исходных данных (величина степеней свободы), равном 100. Для указанных условий табличное значение F-критерия равно 1,26. Если рассчитанное значение F-критерия оказывается выше 1,26, то принимают условие, что сезонная составляющая имеет существенное влияние на изменение значений рассматриваемого ингредиента во времени и ее надо учитывать при прогнозировании.
Анализ хода изменения сезонной составляющей и остатков за весь период наблюдений позволяет определить наиболее вероятное изменение концентрации ингредиента на интересуемом шаге прогнозирования. При произвольном выборе оператором метода аппроксимации изменения значений остатков во времени следует учитывать характер их изменчивости (визуально по точечному графику) и особенность обобщения данных по тому или иному выбираемому методу их аппроксимации (см. описание используемых методов прогнозирования в 7.3.2.1, 7.3.2.2).
8 Алгоритмы прогнозирования изменения содержания ЗВ в водных объектах по результатам систематических гидрохимических наблюдений
8.1 Прогнозирование изменения суточных значений ЗВ и показателей химического состава воды водного объекта
8.1.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (включая его код), для которого будет составляться прогноз;
в) наличие временного ряда результатов ежесуточных наблюдений (включая восстановленные данные) по интересуемому ингредиенту за период не менее трех лет.
г) заданный срок, на который требуется провести прогноз.
Для дополнительного варианта прогнозирования, кроме указанного в трех первых пунктах, требуется наличие установленной достоверной статистической связи между интересуемым редко определяемым ингредиентом (зависимая переменная) и одним из ингредиентов, по которому имеется ежесуточный ряд наблюдений (независимая переменная). Данный вид расчета используют как отдельную задачу в 8.4, 8.5.
8.1.2 Прогнозирование следует начинать с построения и анализа точечного графика «значение ингредиента - время».
Если изменение значений ингредиента во времени имеет заметные сезонные колебания, то для прогнозирования следует использовать метод экстраполяции данных с выделением и учетом сезонной составляющей (переход к 8.1.3). В противном случае переходят к 8.1.4.
8.1.3 Процедуру выделения сезонной составляющей выполняют в соответствии с указаниями в 7.3.3 и далее осуществляют переход к 8.1.5.
Если по критерию (30) сезонность изменения значений признана несущественной, то осуществляют переход к выбору метода прогнозирования без учета сезонной составляющей (переход к 8.1.4).
8.1.4 Выбор одного из методов прогнозирования значений ингредиента оператор выполняет произвольно (вручную) с учетом рекомендаций по использованию каждого из них (см. 7.3.1, 7.3.2).
8.1.5 Результат прогнозирования на конкретную дату в виде ожидаемого значения ингредиента и доверительного интервала его варьирования заносят в итоговую сводку результатов прогноза, которые могут быть представлены (распечатаны) как окончательный результат. В противном случае, если предполагается использовать несколько методов прогнозирования, полученный результат запоминают с целью выполнения в дальнейшем его осреднения совместно с другими результатами прогноза (неудачный вариант прогноза оставляют без внимания и не запоминают для последующего осреднения).
8.1.6 Если прогнозирование выполнено по ряду методов с соответствующим запоминанием, то выполняют осреднение результатов расчета (путем вычисления среднеарифметического значения) и представление (распечатку) окончательного результата. В противном случае осуществляют переход к 8.1.4.
8.2 Прогнозирование изменения декадных значений ЗВ и показателей химического состава воды водного объекта
8.2.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (в том числе его код), для которого будет выполняться прогнозирование;
в) наличие временного ряда результатов ежедекадных наблюдений (включая восстановленные данные) по заданному ингредиенту за период не менее трех лет.
г) заданный срок, на который требуется получить прогноз.
Для дополнительного варианта прогнозирования, кроме указанного в двух первых пунктах, требуется наличие установленной достоверной статистической связи между заданным редко определяемым ингредиентом (зависимая переменная) и одним из ингредиентов, по которому имеется ежедекадный ряд наблюдений (независимая переменная). Данный вид расчета рассмотрен как отдельная задача в 8.4, 8.5.
8.2.2 Расчет медианных значений ингредиента для каждой декады анализируемого временного ряда данных осуществляют по формулам:
m50% = 0,5(n + 1), (31)
С50% = С(m50% - Δm) - ΔmΔC, (32)
где m50% - порядковый номер величины Сi в ранжированном убывающем ряду данных в рассматриваемой декаде;
n - число значений Сi, взятых для расчета C50%;
Δm - дробная часть значения m50% (Δm = 0,5);
ΔC - разница между значениями Ci, которые соответствуют номерам (m50% - Δm) и (m50% - Δm + 1).
8.2.3 Расчет значений ингредиента 20 %-й обеспеченности С20% выполняют по формулам:
m20% = 0,2(n + 1,9), (33)
С20% = С(m20% - Δm) - ΔmΔC, (34)
где m20% - порядковый номер величины Сi в ранжированном убывающем ряду;
n - число значений Ci, взятых для расчета С20%;
Δm - дробная часть значения m20% (например, при m20% = 2,25 Δm = 0,25);
ΔC - разница между значениями Ci, которые соответствуют номерам (m20% - Δm) и (m20% - Δm + 1);
8.2.4 Значения концентрации вещества 80 %-й обеспеченности C80% рассчитывают по формулам:
m80% = 0,80(n + 0,78), (35)
С80% = С(m80% - Δm) - ΔmΔC, (36)
где m80% - порядковый номер величины Сi в ранжированном убывающем ряду;
ΔC - разница между значениями Сi, которые соответствуют номерам (m80% - Δm) и (m80% - Δm + 1).
8.2.5 Процедура прогнозирования значений ингредиента по получившемуся временному ряду среднедекадных (медианных) и обеспеченных на 20 % и 80 % значений ингредиента не отличается от прогнозирования среднесуточных значений. В частности, на основе временного ряда из среднедекадных (медианных) значений ингредиента за выбранный период времени выполняют ту же последовательность шагов, что указана в 8.1.1 - 8.1.6. При отсутствии сезонной составляющей среднедекадные (медианные) и обеспеченные значения ингредиента экстраполируют (прогнозируют) так, как указано в 8.1.4 - 8.1.6.
8.3 Прогнозирование изменения среднемесячных и среднегодовых значений ЗВ и показателей химического состава воды водного объекта
8.3.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода (координатного номера) местоположения систематических гидрохимических наблюдений (в рамках используемой базы данных);
б) наименование ингредиента (в том числе его код), для которого будет выполняться прогнозирование;
в) наличие временного ряда исходных результатов наблюдений (включая восстановленные данные).
г) заданный срок, на который требуется получить прогноз (число шагов от конца временного ряда помесячных или годовых данных).
Для дополнительного варианта прогнозирования, кроме указанного в трех первых пунктах, требуется наличие установленной достоверной статистической связи между заданным редко определяемым ингредиентом (зависимая переменная) и одним из ингредиентов, по которому имеется ежесуточный ряд наблюдений (независимая переменная). Данный вид расчета рассмотрен как отдельная задача в 8.4 и 8.5.
В рассматриваемом методе прогнозирования среднемесячные и среднегодовые значения ингредиента рекомендуется по возможности (при достаточном количестве исходных данных) определять и представлять в виде двух вариантов: отдельно в виде модальных и отдельно в виде медианных значений, а доверительный интервал их варьирования и в том, и другом случае - в виде обеспеченных на 20 % и 80 % значений ингредиента.
8.3.2 По имеющейся (в том числе восстановленной) информации для каждого календарного месяца в соответствующем году рассчитывают отдельно модальные, медианные и обеспеченные на 20 % и 80 % значения рассматриваемого ингредиента.
8.3.3 Прогнозирование на основе использования модальных месячных и годовых значений ингредиента возможно только в том случае, если имеются результаты (в т.ч. восстановленные) ежесуточных наблюдений. Для данной цели по результатам наблюдений предварительно рассчитывают модальные значения для каждого календарного месяца в соответствующем году и по модальным месячным значениям - среднегодовые (медианные) данные за каждый конкретный год. Указанные рассчитанные характеристики сводят в таблицу для последующих этапов прогнозирования (пример программного представления рассчитанных характеристик показан в таблице 7).
Таблица 7 - Исходные для прогнозирования обобщенные значения ингредиента
|
1998 |
1999 |
2000 |
2001 |
2002 |
2003 |
|
|
1 |
31/4,07 |
31/6,39 |
31/4,77 |
31/6,67 |
31/3,61 |
31/4,81 |
|
2 |
26/4,61 |
28/6,58 |
29/2,67 |
28/5,68 |
28/3,44 |
28/4,01 |
|
3 |
31/6,83 |
31/6,57 |
31/2,92 |
31/4,63 |
31/5,83 |
31/3,98 |
|
4 |
30/5,91 |
30/7,7 |
30/5,5 |
30/9,76 |
30/8,93 |
30/8,09 |
|
5 |
31/7,88 |
31/8,26 |
31/6,85 |
31/10,81 |
31/8,03 |
31/9,54 |
|
6 |
30/7,9 |
30/7,48 |
30/5,79 |
30/8,23 |
30/6,89 |
30/9,21 |
|
7 |
31/7,17 |
31/7,07 |
31/5,6 |
31/9,77 |
31/6,93 |
31/9,69 |
|
8 |
31/7,2 |
31/5,25 |
31/5,9 |
31/7,6 |
31/6,06 |
31/6,76 |
|
9 |
36/7,4 |
30/5,5 |
30/6,55 |
30/6,68 |
30/5,95 |
30/7,47 |
|
10 |
31/6,38 |
31/5,52 |
31/6,51 |
31/4,13 |
31/4,29 |
31/9,02 |
|
11 |
30/7,53 |
30/4,76 |
30/3,89 |
30/4,12 |
30/8,64 |
30/8,06 |
|
12 |
31/7,48 |
31/5,04 |
31/5,66 |
31/4,16 |
31/7,12 |
30/6,88 |
|
Годов. |
12/6,68 |
12/6,51 |
12/5,33 |
12/6,68 |
12/6,31 |
12/7,29 |
Примечание - В таблице в числителе указано число имеющихся значений ингредиента в соответствующем месяце года, в знаменателе - осредненное значение ингредиента (в зависимости от поставленной задачи и полноты информации это может быть модальное, медианное, среднеарифметическое или единичное значение ингредиента).
Исходную информацию в таблице 7 независимо от ее полноты приводят помесячно. При наличии в результатах какого-либо месяца менее 28 данных расчет модальных значений в этом месяце проводиться не будет (ячейки останутся пустыми). Чтобы избежать этого, нужно либо вернуться в раздел редактирование данных и восстановить недостающие суточные значения (что более предпочтительно), либо восстановить модальные месячные значения, используя ряд уже известных модальных месячных значений в рассматриваемой таблице (см. 7.2.1.5).
8.3.3.1 Расчет модальных и обеспеченных месячных и годовых значений ингредиента выполняют следующим образом:
а) вариационный ряд значений интересуемого ингредиента в рассматриваемом месяце разбивают на классы; шаг класса Δх определяют по формуле Стерджесса
![]() (37)
(37)
где Сmax, Cmin - соответственно максимальное и минимальное значения (концентрации) ингредиента в вариационном ряду;
N - число данных (членов) в этом ряду;
б) для каждого класса определяют число попавших в него значений (концентраций) вариационного ряда (частоты класса);
в) класс, в котором имеется наибольшее количество частот называется модальным. Для расчета моды используют:
- значение (концентрация) ингредиента в
начале модального класса ![]()
- частоты в классе, предшествующем модальному классу, p1;
- частоты в модальном классе р2;
- частоты в классе, следующим за модальным, р3;
значение моды определяют по формуле
![]() (38)
(38)
Примечание - Если в рассматриваемый год попадает месяц не с ежедневными данными, то расчет моды для него не производят.
г) расчет значений ингредиента 20 %-й обеспеченности С20% выполняют по формулам (33) и (34);
д) значения концентрации вещества 80 %-й обеспеченности С80% рассчитывают по формулам (35) и (36).
8.3.3.2 Если в каком-либо отдельном месяце данные отсутствуют (мода не может быть рассчитана), то эти пропуски восстанавливают. Число пропусков в весенний период не должно быть более одного месяца, в остальной период - не более двух месяцев.
8.3.3.3 По ежемесячным модальным значениям рассчитывают среднегодовые (медианные) данные в отдельные рассматриваемые годы наблюдений по формулам (31), (32).
8.3.3.4 Для каждого года наблюдений по месячным данным 20 %-й и 80 %-й обеспеченности рассчитывают средние (медианные) годовые значения той же обеспеченности по формулам, аналогичным формулам (31), (32).
8.3.3.5 На основе получившихся временных рядов статистических характеристик за каждый год наблюдений рассчитывают ожидаемое по прогнозу в соответствии с заданной задачей модальное значение ингредиента в конкретном заданном календарном месяце или модальное годовое значение ингредиента с соответствующими для них доверительными интервалами варьирования.
Для указанных методов прогнозирования вначале строят точечный график «значение ингредиента - время» и анализируют характер изменения во времени рассматриваемых модальных значений ингредиента. Затем выбирают и используют для экстраполяции один или несколько (последовательно) наиболее подходящих методов прогнозирования (см. 7.3.1, 7.3.2).
8.3.4 Расчет месячных и годовых медианных значений ингредиента, а также доверительных интервалов их варьирования проводят в следующей последовательности.
8.3.4.1 В зависимости от количества измеренных значений ингредиента в рассматриваемом месяце рассчитывают либо медианное, либо среднее арифметическое значение ингредиента: если число значений в месяце более трех, то определяют медианное месячное значение ингредиента по формулам, аналогичным (31), (32), в противном случае - среднее арифметическое значение по формуле
![]() (39)
(39)
где Хср - среднемесячное значение ингредиента;
Xi - i-e значение ингредиента;
n - число значений Xi, взятых для определения Хср.
В случае наличия в месяце всего одного значения ингредиента это значение «идеализируют» и принимают за среднемесячное.
8.3.4.2 По полученным месячным значениям в каждом календарном году рассчитывают среднегодовые значения, в качестве такого значения в каждом году берут медиану из ряда рассчитанных месячных значений ингредиента.
Расчет медианы выполняют по формулам, аналогичным формулам (31), (32).
8.3.4.3 По результатам расчетов составляют исходную для прогнозирования таблицу в виде таблицы 7. Если в таблице имеются пропуски месячных данных их восстанавливают.
8.3.4.4 Пользуясь массивами временных данных (рядов), подготовленных в виде таблицы 7, выполняют прогнозирование:
а) ожидаемого среднемесячного значения ингредиента в заданном календарном месяце в очередном году (или на более дальнюю перспективу) по данным этого календарного месяца в рассматриваемом многолетии;
б) ожидаемого в заданном конкретном месяце среднемесячного значения ингредиента в очередном году (или на более дальнюю перспективу) по данным всех или выбранной части ряда среднемесячных значений за предыдущий период наблюдений;
в) ожидаемого среднегодового значения ингредиента в очередном году (или на более дальнюю перспективу) по среднегодовым данным, полученным за предыдущий период наблюдений.
Примечание - Если требуется провести прогнозирование среднесезонных значений ингредиента в заданном сезоне, то из таблицы 7 удаляются его значения за все месяцы, кроме месяцев в интересуемом сезоне. В результате вместо среднегодовых значений будут рассчитаны среднесезонные значения и выполнен прогноз среднесезонных значений ингредиента на заданную перспективу.
Любую из перечисленных задач прогнозирования выполняют по одному произвольно выбранному методу расчета (или путем последовательного использования нескольких методов с последующим осреднением результатов прогнозирования). Особенности использования отдельных методов изложены в 7.3.1, 7.3.2.
8.3.4.5 Для получения доверительного интервала варьирования рассчитанных по прогнозу среднемесячных или среднегодовых значений ингредиента используют следующие варианты.
В случае прогнозирования с использованием метода наименьших квадратов и наличии найденной достоверной статистической связи доверительный интервал результата прогноза принимается равным погрешности расчетов по найденному уравнению регрессии с доверительной вероятностью Р = 0,95 (см. 7.3.1).
В противном случае (при отсутствии достоверной статистической связи) доверительный интервал прогнозных значений ингредиента принимают равным его значениям 20 %-ой и 80 %-ой обеспеченности, рассчитанным по данным использованного для прогнозирования ряда среднемесячных или среднегодовых значений (см. формулы (33) - (36)).
Если для прогнозирования использовался один из адаптивных методов, то доверительный интервал результата прогноза принимают равным:
- средним (медианным) значениям среди рассчитанных для каждого месяца или года отклонений концентраций ингредиента 20 %-й и 80 %-й обеспеченности от моды или медианы (в зависимости от рассматриваемой задачи) в используемом для прогноза ряду данных;
- погрешности адаптивного прогноза при Р = 0,95 (см. формулу (29)) только для месячных или годовых данных, если обеспеченные на 20 % и 80 % значения по ретроспективной информации по месяцам не определялись (например, в связи с недостаточным количеством исходных данных).
При использовании в качестве результата прогноза среднеарифметического значения ингредиента (по месячному или годовому ряду данных) и при отсутствии достоверной статистической связи типа «значение ингредиента - время» в качестве доверительного интервала варьирования концентраций ЗВ используют весь интервал изменения его значений от минимальной среднемесячной или среднегодовой концентрации ЗВ Сmin до максимальной среднемесячной или среднегодовой концентрации Сmax.
8.4 Прогнозирование с использованием парной статистической связи значений ингредиентов
8.4.1 В качестве исходной информации для решения задачи требуется:
а) наличие кода интересуемого створа местоположения систематических гидрохимических наблюдений (в рамках используемой базы данных) за часто измеряемым ингредиентом, выбранным в качестве независимой переменной;
б) наличие кода (координатного номера) местоположения интересуемого створа систематических гидрохимических наблюдений (в рамках используемой базы данных) за редко измеряемым ингредиентом, выбранным в качестве зависимой переменной;
в) наименование ингредиента (в том числе его кода), выбранного в качестве независимой переменной;
г) наименование ингредиента (в том числе его кода), выбранного в качестве зависимой переменной;
д) наличие временного ряда результатов ежедневных наблюдений за ингредиентом, выбранным в качестве независимой переменной;
е) наличие временного ряда результатов наблюдений за ингредиентом, выбранным в качестве зависимой переменной;
ж) заданный срок, на который требуется получить прогноз.
8.4.2 Используя разработанный программный комплекс, для рассматриваемого метода прогнозирования осуществляют следующий ряд процедур.
8.4.2.1 Предварительно по любому из вышерассмотренных методов выполняют прогнозирование часто измеряемого ингредиента, выбранного в качестве независимой переменной, на заданную дату. Полученные результаты в виде ожидаемого по прогнозу значения ингредиента (независимая переменная) и его доверительного интервала варьирования запоминают для последующей процедуры прогнозирования.
8.4.2.2 Составляют по совпадающим датам измерений временной ряд парных данных независимой и зависимой переменных.
8.4.2.3 По временному ряду парных данных в виде приведенных значений (отношение измеренного значения к его среднему значению) выполняют построение точечного графика изменения зависимой и независимой переменных во времени.
8.4.2.4 По точечному графику визуально определяют и удаляют явно нехарактерные пары данных (например, когда имеется ошибочнее значение по одному из ингредиентов в паре), а также определяют начало временного ряда, с которого целесообразно оценивать статистическую связь между значениями часто и редко измеряемым ингредиентами.
8.4.2.5 После выполнения процедуры, указанной в 8.4.2.4, по выбранному временному ряду парных данных по методу наименьших квадратов с использованием всего ряда предложенных к использованию уравнений линеаризованной связи определяют наилучшее уравнение статистической связи между зависимой и независимой переменными (см. данную процедуру в 7.3.1).
8.4.2.6 По рассчитанному уравнению регрессии по ранее полученному прогнозному значению независимой переменной на заданную дату выполняют расчет ожидаемого значения зависимой переменной.
8.4.2.7 По установленному уравнению регрессии по ранее полученным значениям доверительного интервала независимой переменной на заданную для прогноза дату вычисляют доверительный интервал возможного варьирования значений зависимой переменной по формулам:
а) верхнее значение интервала -
Cpв = Cp + ΔSв, (40)
где Ср - прогнозное значение зависимой переменной;
![]() (41)
(41)
Св - полученное по прогнозу максимальное значение зависимой переменной с использованием верхнего или нижнего предела доверительного интервала изменения значений независимой переменной;
Sсв - погрешность определения значений зависимой переменной по полученному уравнению статистической связи между зависимой и независимой переменными, определяемая по формуле, аналогичной формуле (6);
в) нижнее значение интервала -
Cрн = Cр - ΔSH, (42)
где ![]() (43)
(43)
Сн - полученное по прогнозу минимальное значение зависимой переменной с использованием верхнего или нижнего предела доверительного интервала изменения значений независимой переменной.
9 Представление в возможное использование результатов прогноза
9.1 Результат прогноза изменения концентраций интересуемого ЗВ на заданный срок в рассматриваемом створе систематических гидрохимических наблюдений водного объекта представляют в виде ожидаемого среднего значения этого ЗВ, в роли которого в зависимости от полноты исходной информации выступает его единичное, среднеарифметическое, медианное или модальное значение. Кроме этого, указывают погрешность результата прогноза в виде возможного доверительного интервала варьирования концентраций ЗВ в заданный для прогнозирования период года (день, сезон, декада, месяц или год). Для ориентации в степени ухудшения или улучшения ожидаемого по результатам прогноза качества воды представляемые значения по рассматриваемому ЗВ указывают также в виде кратности превышения действующих ПДК или специально установленных региональных нормативов концентраций.
9.2 Если оценка ожидаемого изменения концентраций ЗВ на заданный срок проводилась несколькими методами прогнозирования, каждый из которых признан достаточно приемлемым для поставленной задачи, то в качестве окончательного результата представляют среднее значение ЗВ и доверительный диапазон его варьирования, полученные по результатам использованных методов прогнозирования.
9.3 Результаты прогноза ожидаемых изменений концентраций ЗВ, прежде всего, могут быть использованы для следующих целей:
- информационного обеспечения заинтересованных организаций (особенно связанных с планирования водоохранных мероприятий) и населения об ожидаемом изменении качества речной воды в створах систематических гидрохимических наблюдений по интересуемым ЗВ;
- корректировки сроков отбора проб воды, в том числе назначения и проведения дополнительного или повторного отбора проб воды в случае ранее полученного сомнительного результата;
- корректировки частоты и сроков отбора проб воды с учетом характера изменения выделенной сезонной составляющей (повышение частоты наблюдений в периоды существенных изменений концентрации ЗВ);
- корректировки методов обработки информации для оценок состояния водного объекта (например, для выделения характерных многолетий для расчета в них осредненных и обеспеченных концентраций ЗВ).
9.4 Если для какого-либо ЗВ выявлено наличие сезонной составляющей, то при оценках существенности и характера изменения концентраций этого ЗВ во времени следует анализировать весь имеющийся временной ряд равноточных данных, поскольку по срокам в разные годы начало и конец сезонных изменений значении ЗВ могут не совпадать.
9.5 Если неоднократно не удается получить достоверные результаты прогноза, то это может являться следствием следующих причин:
- резко изменились (изменяются) условия формирования в речной воде концентрации рассматриваемого ЗВ или показателя химического состава воды;
- частота отбора проб воды не адекватно учитывает изменчивость концентраций ЗВ в водном объекте во времени (при этом не следует исключать возможное влияние на качество результатов прогноза отсутствие учета при отборе проб воды внутрисуточных колебаний значений ЗВ).
Приложение А
(обязательное)
А.1 Общие сведения
Программный комплекс «ГХМ-прогноз» предназначен для оперативного прогнозирования на ПК изменения во времени содержания ЗВ в водных объектах с использованием накопленной ретроспективной и текущей информации в базе гидрохимических данных ГУ УГМС (ГУ ЦГМС).
Программа комплекса разработана в среде Delphi 7 для работы на ПК под управлением операционной системы Windows.
Для установки программного комплекса на выбранном диске ПК создают папку для основных файлов комплекса, в которую простым копированием записывают файлы: «ГХМ-прогноз.ехе», «Kod_ingr.win», «kach.win» и «prizn.win». Кроме того, в этой папке рекомендуется создать вложенные папки для решаемых задач, которые будут содержать файлы с исходными данными и файлы с результатами расчетов для каждой задачи.
Для нормальной работы программы необходимо проверить (настроить) параметры отображения чисел (см. в компьютере разделы «Панель управления»; «Настройка языковых параметров, представления чисел, денежных единиц, времени и дат»):
- разделитель целой и дробной части числа - десятичная точка;
- разделитель групп разрядов - должен отсутствовать;
- группировка цифр по разрядам - должна отсутствовать.
Рекомендуется создать ярлык на рабочем столе для удобного запуска программного комплекса. Создание ярлыка выполняют стандартными действиями работы в Windows.
Исходные данные (особенно значительного объема), содержащие результаты текущих гидрохимических наблюдений в интересуемых створах водного объекта, рекомендуется формировать с использованием программного комплекса «ГидрохимПК». Исходные данные небольших объемов можно вводить непосредственно в программе «ГХМ-прогноз».
Запуск программного комплекса осуществляют в соответствии с правилами работы с приложениями в среде Windows - запуском файла «ГХМ-прогноз.ехе».
А.2 Основные операции, выполняемые в программном комплексе
А.2.1 Предварительная подготовка данных:
- подготовка файла «Перечень координатных номеров» (ПКН);
- выборка данных из «ГидрохимПК»;
- подготовка данных, получаемых из других организаций и ведомств.
А.2.2 Загрузка данных в БД программы «Прогноз»:
- загрузка файла ПКН;
- загрузка из Excel данных о ежедневных расходах речной воды или имеющихся данных других ингредиентов;
- загрузка данных от «ГидрохимПК».
А.2.3 Проверка и корректировка информации по данным временного ряда:
- визуализация интересуемой информации на графике временного ряда;
- редактирование данных временного ряда (в том числе дублированных значений ингредиентов).
А.2.4 Проверка и корректировка информации путем построения и анализа парных зависимостей:
- выбор двух ингредиентов (с соответствующей сопровождающей их «ключевой» информацией) за заданный временной период;
- построение массива совмещенных по датам измерения данных для выбранных ингредиентов;
- определение параметров статистической зависимости между значениями двух ингредиентов;
- построение графика статистической связи;
- редактирование массива совмещенных данных двух ингредиентов по результатам анализа парной статистической связи.
А.2.5 Восполнение пропусков временного ряда:
- покомпонентное восполнение пропусков в результатах ежедневных, подекадных, помесячных наблюдений в створах систематических наблюдений;
- проверка влияния результатов восполнения данных на параметры статистической зависимости между значениями двух ингредиентов и характер изменения временного ряда данных.
А.2.6 Запоминание откорректированной информации в виде нового файла с расширением «*.dan».
А.2.7 Прогнозирование изменения значений статистических характеристик рассматриваемого ингредиента в заданном створе систематических наблюдений:
- среднегодовых значений;
- среднемесячных значений;
- среднедекадных значений;
- среднесуточных значений (на заданную календарную дату).
Перечисленные характеристики могут быть получены с расчетом и использованием парной статистической связи между значениями часто (независимая переменная) и редко (зависимая переменная) измеряемых ингредиентов.
A3 Подготовка файлов данных с расширением «*.dan»
А.3.1 Процедура подготовки файлов с расширением «*.dan» необходима в связи с тем, что при прогнозировании значений различных ингредиентов по разным створам наблюдения нецелесообразно пользоваться информацией, сформированной по пробам воды. Использованный подход позволяет рассматривать совместно данные по отдельным ингредиентам, полученные в разных створах наблюдения (например, данные в створах водозабора и близлежащих створах наблюдения ГУ УГМС), а также значительно упрощает корректировку данных, восполнение и дополнение их новыми значениями без потери информативности для целей прогнозирования.
А.3.2 Предварительно до запуска программы «ГХМ-прогноз» в «ГидрохимПК» следует сформировать следующие файлы:
а) перечень используемых для прогнозирования координатных номеров створов систематических гидрохимических наблюдений (перечень координатных номеров, которые потребуются для прогнозирования, формируют путем выборки их из «ГидрохимПК» в разделе КПХ; выбранный перечень координатных номеров записывают в виде файла с расширением «*.pkn», текст в строке файла не должен превышать 80 символов);
б) файлы с результатами наблюдений с расширением «* dat» по всем интересуемым створам;
в) файлы (таблицы) с ежедневными расходами и температурой речной воды (если таковые имеются) в створах гидропостов, ближайших к створам гидрохимических наблюдений в формате «Excel» по образцу представленному в приложении В (см. также прилагаемый к программному комплексу «ГХМ-прогноз» файл «р. Ока. Горбаmoв_pacxoды_2001-2002.xls»).
Примечание - При необходимости в таблице в формате «Excel» переносимые ежедневные расходы из створа водпоста в створ гидрохимических наблюдений корректируют.
Файлы с расширением «*.dat» формируют с использованием «ГидрохимПК» по заданным створам по всем интересуемым ингредиентам за весь период наблюдений.
Файлы (таблицы) с результатами наблюдений в формате «Excel» готовят в соответствии с прилагаемым к программному комплексу образцом (см. файл «Образец занесения гидрохимических данных в Excel»).
Примечание - В таблице в формате «Excel» - 1-я и 2-я строки таблицы - наименование столбцов (для ингредиентов имя и размерность); 3 строка - начиная со столбца «F» - коды ингредиентов; начиная с 4-й строки - содержание столбцов. Первый столбец (А) - координатный номер (для программы обязателен). Второй я третий столбцы (В, С) - «Имя реки» и «Наименование створа» для программы не обязательны, т.е. могут быть незаполненными (пустыми), но для текущей работы с исходной информацией заполнение их крайне желательно. Наличие четвертого столбца (D) и последующих, включая восьмой (Н), является обязательным (заполнение 4 - 7 столбцов является обязательным). Количество и порядок включения ингредиентов с соответствующим содержанием в таблицу, начиная с девятого столбца (I), является произвольным. Содержание каждой таблицы целесообразно ограничивать одним створом реки. Коды ингредиентов должны соответствовать указанным их наименованиям в таблице. Пятый столбец (Е) - время как целое число: состоит из трех или четырех цифр, причем две последние цифры - минуты, а одна или две первые цифры, соответственно, часы (например: 824 - 8 часов 24 минуты, 2255 - 22 часа 55 минут, 0 - 0 часов 0 минут) (формат времени такой же, как в «ГидрохимПК»).
Правила форматирования ячеек листа программы Excel следующие:
а) когда создается новый лист все ячейки по умолчанию имеют формат «Общий»;
б) столбец «Дата» (четвертый столбец) выделяется и ему назначается формат «Дата» типа *14.03.2001.
в) остальные столбцы и ячейки остаются в формате «Общий».
Подготовленные файлы записывают в созданную папку программного комплекса или, если решаемых задач много, в отдельную вложенную дополнительную папку.
А.3.3 Запуск программы «ГХМ-прогноз.ехе» сопровождается появлением на мониторе главного экрана формы программы с горизонтальным меню: «Файл», «Редактирование», «Прогнозирование». Исходный вид главного экрана представлен на рисунке А.1.
А.3.4 Нажатие в меню кнопки «Файл» позволяет открыть закладку для выбора следующих функций:
а) открыть ПКН-Прогноз;
б) открыть данные от «ГидрохимПК»;
в) открыть данные от «Прогноз»;
г) открыть данные от «Excel»
д) открыть данные от водпоста;
е) записать данные в файл (*.dan).
Рисунок А.1 - Главный экран формы программы с горизонтальным меню
А.3.4.1 Процедуры подготовки файлов с расширением «*.dan» касаются функций, приведенных в перечислениях а), б), е) А.3.4. При активизации функции «Открыть ПКН-Прогноз» открывается стандартное для Windows окно выбора каталогов и файлов. Здесь на соответствующем месте жесткого диска отыскивают и выбирают (открывают) ранее сформированный для работы файл с расширением «*.pkn» (содержание файла программно используется только для формирования текста отчетного материла по результатам прогноза). Он должен находиться в той же папке, где находится программа «ГХМ-прогноз.ехе». После открытия выбранного файла в окне «Коорд. номера в ПКН» появляются (загружаются) соответствующие координатные номера точек систематических гидрохимических наблюдений.
А.3.4.2 При активизации функции «Открыть данные от ГидрохимПК» вновь открывается стандартное для Windows окно выбора каталогов и файлов. Здесь также на соответствующем месте жесткого диска отыскивают и выбирают (открывают) нужный для работы файл с расширением «*.dat». После открытия выбранного файла в окне «В данных» появляются координатные номера, содержащиеся в этом файле. В окне «Код. Коорд. номер. ингр. Кол-во» появляются данные о количестве имеющихся в загруженном файле результатов наблюдений по каждому ингредиенту. В окне «Ингредиенты программы» появляется перечень всех ингредиентов с их кодовыми номерами, присутствующих в программе «ГХМ-прогноз.ехе», что проиллюстрировано на рисунке А.2.

Рисунок А.2 - Экранная форма программы после ввода (загрузки) файла с расширением «*.dat»
А.3.4.3 Для запоминания всей или части загруженной в программу информации в файл с расширением «*.dan» активизируют функцию «Записать данные в файл (*.dan)». В появившемся окне Windows «Назначить имя файла для записи данных» выбирают необходимую папку, например вложенную папку по рассматриваемой задаче, для получаемого файла (как это принято в Windows) и дают имя файлу с обязательной записью расширения «*.dan». После назначения имени этого файла и нажатия на кнопку «Сохранить», появляется промежуточная экранная форма «Назначить условия выборки данных» (рисунок А.3). В этой форме для формирования нового файла используется ряд вопросов. Первые два вопроса:
- «Выбрать список координатных номеров?»;
- «Выбрать список ингредиентов?»
целесообразно использовать, когда создается файл с большим количеством координатных номеров, для которых в свою очередь составляется максимально большой или, наоборот, ограниченный, но единый для всех список ингредиентов.

Примечание - Расположенные в правой части данной формы кнопки служат для корректировки ввода отметок, не выходя из этой формы.
Рисунок А.3 - Экранная форма программы, появляющаяся после присвоения имени создаваемому новому файлу с расширением «*.dan»
Для выборки требуемой части информации нужно отметить галочкой пункт «Выбрать список координатных номеров? (иначе все)» и нажать появившуюся кнопку «Выбрать список КН». В появившейся экранной форме проставляют «галочки» в окнах тех створов, которые нужно записать в один файл. Далее нажимают кнопку «Запомнить список» или «Запомнить один». В последнем случае в файл войдет только первый их отмеченных створов.
Далее следует поставить галочку в окне «Выбрать список ингредиентов? (иначе все)» и нажать кнопку «выбрать список ингредиентов». В появившейся экранной форме задают (отмечают) список ингредиентов, который будет использоваться для всех отмеченных ранее координатных номеров.
Работа с четвертым, пятым и шестым вопросами общей формы ввода информации, приведенными на рисунке А.3, позволяет при необходимости еще более ее сузить в создаваемом файле (по периоду времени, по учитываемым признакам качества полученных результатов по отдельным ингредиентам). В случае игнорирования любого из вопросов в файл автоматически будут включены все имеющиеся данные без ограничений по условиям пропущенного вопроса.
После принятия решения по всем перечисленным вопросам для записи имени создаваемого нового файла с расширением «*.dan» в память ПК нажимают кнопку «Сформировать назначенные условия».
В случае, когда создается файл с малым количеством координатных номеров (например, не более трех), целесообразно не отмечать пункты: «Выбрать список координатных номеров? (иначе все)» и «Выбрать список ингредиентов? (иначе все)», а использовать пункт (поставить галочку) «Выбрать коорд. номер и ингредиент из списка». В этом случае в появившейся экранной форме по каждому координатному номеру (створу) приводятся только те ингредиенты, которые наблюдались в этом створе. Выбор ингредиентов выполняют по каждому створу отдельно. Далее процедура выбора информации и перевода ее в файл с расширением «*.dan» не отличается от вышеописанной.
В целях создания удобных для работы небольших файлов, используя рассмотренную процедуру, рекомендуется сформировать отдельно файлы по створам, информация в которых может быть сопоставимой (например, для использования при корреляционном анализе).
Далее все работы по редактированию информации и прогнозированию рекомендуется выполнять только с использованием файлов, имеющих расширение «*.dan». Это связано с тем, что дальнейшую обработку информации удобнее вести по каждому ингредиенту отдельно, а не по их совокупности в пробах воды.
Для ввода ежедневных расходов речной воды из файла формата «Excel» можно использовать два варианта. Первый вариант применяют в том случае, если требуется проводить анализ временного ряда значений расхода речной воды вне связи его с данными изменения во времени других ингредиентов. Второй вариант применяют тогда, когда необходимо добавить информацию по расходам речной воды к данным по другим ингредиентам, уже загруженным в программу. При этом следует учесть то, что в загруженной информации (например, подготовленной в ГидрохимПК) уже имеются какие-то данные по расходам речной воды. Для ввода данных по обоим вариантам используют последовательность действий, описанную ниже. Для загрузки по второму варианту (это касается загрузки не только значений расходов воды, но и любой другой информации) необходимо предварительно перед началом выбора отметить галочкой на основной форме (см. рисунок А.1) пункт «Загрузка информации с добавлением?».
А.3.4.4 Для ввода ежедневных расходов речной воды в информацию определенного створа выбирают в меню пункт «.Файл» и далее в открывшейся форме нажимают кнопку «Открыть данные водпоста». В появившейся экранной форме в окне «Назначить координатный номер» записывают координатный номер того створа, в который предполагают ввести гидрологические данные (он может быть уже открыт в главном экране формы). Далее в окне «Назначить код ингредиента/расхода» записывают цифру 13. При нажатии кнопки «Выбрать файл» открывается стандартное для Windows окно выбора каталогов и файлов. Здесь на соответствующем месте жесткого диска отыскивают ранее сформированный нужный файл Excel («*.xls») с ежедневными расходами речной воды за интересуемый период. При нажатии кнопки «Открыть» информация файла с расходами воды будет загружена в данные ранее открытого файла с соответствующим координатным номером или в отдельный файл с указанным координатным номером (если ведется обычная загрузка, а не загрузка информации с добавлением). В окне «Загружено значений» автоматически указывается, сколько значений расхода речной воды было загружено в файл.
Для выхода из промежуточной экранной формы нажимают кнопку «Выход». Для запоминания откорректированного файла поступают аналогично тому, как это было указано в А.3.4.3 при перенесении информации в файл с расширением «*.dan».
Если в догружаемом файле уже есть часть вводимой информации, то появляется окно с дополнительными условиями выбора вида ввода информации:
а) добавление в память всех данных без замены и исключения (т.е. будет произведен ввод информации полностью без учета возможных дублей значений ингредиента по одному и тому же координатному номеру и одной и той же дате);
б) добавление в память данных с заменой по дублям ключей (при вводе всей информации по указанному координатному номеру имеющиеся ранее занесенные на одну и ту же дату данные будут заменены на новые);
в) добавление только данных, не имеющих дублей ключей (информация будет введена без замены ранее занесенных данных).
После выбора курсором условий ввода информации нажимают кнопку «Выполнить добавление данных» или кнопку «Отменить добавление» (для выхода из режима дополнительного ввода информации без добавления данных).
А.3.4.5 Если необходимо дополнить или совместить в одном файле с расширением «*.dan» информацию размещенную в двух отдельных файлах, то после загрузки информации из первого файла дополнительно в главном экране формы программы делают отметку в окне функции «Загрузка информации с добавлением?». Вновь нажимают кнопку «Файл», активизируют функцию «Открыть данные от «Прогноз», в открывшемся стандартном для Windows окне выбирают (открывают) нужный для совместного рассмотрения второй файл. После нажатия кнопки «Открыть» произойдет совмещение данных по створам, имеющих один и тот же координатный номер или, если координатные номера створов не совпадают, в окне «В данных» появится дополнительный координатный номер. При наличии совпадений во вносимых и ранее внесенных данных, как было указано выше, появляется окно с дополнительными условиями ввода информации. Сформированный таким образом файл позволяет включить в совместный анализ для оценки парных статистических связей и корректировки данных информацию по двум и более створам.
А.3.4.6 Для ввода результатов гидрохимических наблюдений из файла формата «Excel» активизируют закладку «открыть данные от «Excel»». В открывшемся стандартном для Windows окне выбора каталогов и файлов выбирают заранее сформированный файл с расширением «*xls», заполненный в соответствии с прилагаемым образцом к данной программе - «Образец занесения гидрохимических данных в Excel». В главном экране формы программы в окне «В данных» появляются внесенные координатные номера, а в окне «Код. Коорд. номер. ингр. Кол-во» появляются данные о количестве имеющихся в загруженном файле результатов наблюдений по каждому ингредиенту. В окне «Ингредиенты программы» соответственно появляется перечень всех ингредиентов с их кодовыми номерами, присутствующих в программе «ГХМ-прогноз.ехе».
А.4 Редактирование информации
А.4.1 Редактирование информации проводят только в случае, если в программу уже загружены необходимые данные. Основная цель проведения редактирования исходной для прогнозирования информации - это удаление и «флагирование» в файлах забракованных и сомнительных данных (редактирование осуществляется путем ввода цифровых отметок, отражающих соответствующие признаки качества результатов наблюдений по отдельным ингредиентам за определенные даты), а также добавление и восстановление исходной информации, исключение ненужных дублей значений ингредиентов.
А.4.2 Для редактирования данных в меню главной экранной формы следует нажать кнопку «Редактирование». В появившемся вложенном меню предлагаются следующие функции:
- «Добавить данные»;
- «Редактировать данные в таблице»;
- «Корректировать данные временного ряда»;
- «Корректировать данные по парной зависимости»;
- «Восстановить пропуски исходного временного ряда»;
- «Удалить информацию ПКН».
А.4.2.1 Для добавления новых текущих данных курсором «мышки» активизируют запись «Добавить данные» (добавление как первоначальный ввод данных возможен также и в случае отсутствия загруженных данных в программу). Пользуясь сервисом открывшейся экранной формы, приведенной на рисунке А.4, построчно заносят новые результаты наблюдений по отдельным ингредиентам. Заполненная данными строка запоминается (заносится в базу) только после нажатия кнопки «Запомнить строку». При этом можно пользоваться одной и той же строкой, внося в нее необходимые поправки, либо добавлять новые строки, пользуясь кнопкой «Добавить строку», и уже в них делать необходимые поправки. Для запоминания каждой строки с внесенными (исправленными) данными следует нажать кнопку «Запомнить строку». Кнопка «Удалить строку» позволяет удалить строку (запись строки), в которой установлен курсор. Внесенные в базу данные будут автоматически отсортированы по датам измерения (датам отбора пробы) и кодам ингредиентов.

Рисунок А.4 - Экранная форма программы, для ввода информации в базу данных
Для корректировки (исправления), удаления и «флагирования» данных можно использовать поочередно или выборочно указанные в закладке три рекомендуемые функции.
А.4.2.2 При активизации курсором «мышки» записи «Редактировать данные в таблице» открывается экранная форма, в которой в интересуемой записи створа и ингредиента курсором «мышки» ставят «галочку» и нажимают кнопку «Выбрать строку». В открывшейся таблице (см. рисунок А.5) наиболее удобно корректировать концентрации вещества, резко отличающиеся от реально возможных (проверять наличие нереальных нулевых или крайне высоких концентрации вещества и удалять их или «флагировать» путем присвоения номера соответствующего признака или исправлять значения ингредиента).
Правку в каждой ячейке запоминают нажатием на клавиатуре клавиши «Tab». При использовании кнопок «Добавить» и «Удалить» следует учитывать, что при добавлении и удалении строки в базе данных главной ячейкой в строке является ячейка с датой.
Рисунок А.5 - Экранная форма программы для редактирования исходных данных, представленных в виде таблицы
Оставленные, но забракованные или сомнительные значения ингредиента помечают («флагируют») в колонке «Признак» соответствующим номером:
0 - значение нормальное (проставлено по умолчанию);
1 - значение восстановленное (при использовании процедуры восстановления данных номер этого признака устанавливается автоматически);
2 - значение сомнительное;
3 - значение забраковано (ни при каких обстоятельствах это значение не может быть рекомендовано для прогнозирования);
4 - не использовать для прогноза (рекомендуется не использовать для прогнозирования, особенно при установлении парных зависимостей);
5 - временно восстановленные (при использовании процедуры восстановления данных номер этого признака устанавливается автоматически).
Если в таблицу были внесены изменения, то эти изменения будут сохраняться только на время работы с данным открытым файлом. Чтобы сохранить обновленный файл с введенными в него изменениями, следует после закрытия таблицы вернуться в главный экран формы программы (см. рисунок А.1) и воспользоваться соответствующей операцией в меню «Файл» для сохранения файла с откорректированной информацией под новым именем с расширением «*.dan».
А.4.2.3 При активизации в разделе главного меню «Редактирование» функции «Корректировать данные временного ряда» можно перейти к редактированию (удалению, исправлению или «флагированию») данных на основе просмотра графиков временного ряда концентраций интересуемого ингредиента (эта форма редактирования наиболее эффективна в связи с возможностью визуального контроля всего исходного временного ряда значении рассматриваемого ингредиента, особенно, если некоторые его значения резко отличаются от соседних). В открывшейся экранной форме, приведенной на рисунке А.6, следует нажать кнопку «Выбор: КН; ингредиент», а затем в следующей открывшейся форме поставить курсором «мышки» галочку в окне с интересуемым кодовым номером точки наблюдения на водном объекте и рассматриваемым ингредиентом и нажать кнопку «Выбрать строку». Далее следует указать в соответствующих окнах диапазон дат (если не устраивает диапазон дат, записанный по умолчанию), в пределах которых будет построен исходный график (см. рисунок А.6). Формат записи дат указан на экранной форме. По умолчанию (без корректировки дат) будет построен график на основе всех имеющихся данных. Далее, по приведенным ниже спискам в двух окнах, делают выбор (фильтрацию) используемых для построения графика данных по их качественным признакам. В первом окне, представлен список качеств измерений, который использовался в «ГидрохимПК» и «перешел» автоматически в рассматриваемую базу данных. Можно пользоваться кнопкой «Выделить весь список» для выбора всех данных независимо от значений, характеризующих качество измерений (удерживая на клавиатуре нажатой клавишу «Ctrl», можно провести выбор данных с использованием отдельных позиций списка качеств измерений, если в результате анализа результатов наблюдений в данных от «Гидрохим ПК» измеренным значениям ингредиентов были присвоены коды качества). Во втором окне осуществляют выбор признаков значений данных, сделанных дополнительно для целей прогнозирования в сформированном файле данных с расширением «*.dan» (если выделяется не весь список, то минимально должны быть отмечены нулевая, первая и пятая позиции). После работы с перечисленными списками для перехода к графику нажимают кнопку «Запомнить параметры». Пользуясь появившимся графиком, показанном на рисунке А.7, можно:
- оценить закономерности изменения во времени концентраций вещества;
- оценить границы характерных периодов времени, в которых можно наиболее эффективно прогнозировать концентрации рассматриваемого вещества по трендам их изменения;
- определить значения концентраций, которые носят аномальный характер во временном ряду концентраций и требуют удаления или «флагирования» перед работой с регрессионными зависимостями;
- пользуясь курсором можно выделять (увеличивать) на графике изображение интересуемого периода изменения значений ингредиента (выделение курсором прямоугольника сверху вниз в правую сторону - увеличение; сверху вниз в левую сторону - возврат к исходной позиции).
Рисунок А.6 - Экранная форма программы для выбора параметров временного ряда концентраций ингредиента перед построением графика этого ряда
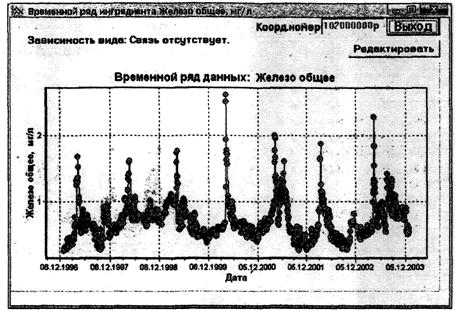
Рисунок А.7 - Экранная форма программы для просмотра временного ряда
В целях корректировки данных (удаление значений ингредиента или дублей этих значений, их исправление или «флагирование») нажимают кнопку «Редактировать». В появившейся в левой стороне графика таблицу, показанную на рисунке А.8, вносят необходимые изменения. Выполненные исправления в ячейках запоминают нажатием клавиши «Enter» или «Tab» (дата и код ингредиента не корректируются; удалить можно ту строку, в которой находится курсор). Результаты корректировки можно просматривать на графике, нажав кнопку «График». По отметкам в столбце с заголовком «Дубли» можно найти и удалить попавшие в файл дубли значений ингредиента на одну и ту же дату (при смещении таблицы и исчезновении столбца со значениями ингредиента «пропавший» столбец можно вернуть на место, смещая курсор к месту «пропавшего» столбца).
Если требуется запомнить откорректированный файл, то поступают аналогично тому, как это было указано при «Редактировании данных в таблице» (см. А.4.2.2).
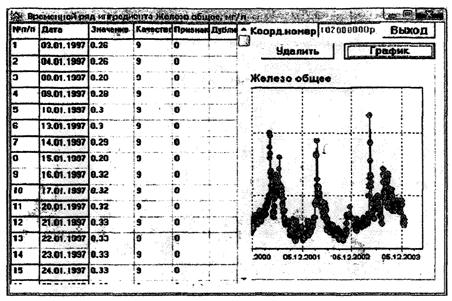
Рисунок А.8 - Экранная форма программы для корректировки данных временного ряда
А.4.2.4 При активизации в разделе главного меню «Редактирование» функции «Корректировать данные по парной зависимости» можно перейти к редактированию (удалению, исправлению или «флагированию») данных на основе просмотра графиков парной зависимости между независимой переменной, в роли которой выступает измеряемый с большой частотой ингредиент, и зависимой переменной, в роли которой выступает редко измеряемый ингредиент (последний может быть взят из другого близлежащего створа, координатный номер которого присутствует в рассматриваемом файле).
Вначале в открывшемся окне выбирают координатный номер точки наблюдения на водном объекте и ингредиент, выступающий в роли независимой переменной Выбор исходных данных выполняют аналогично указанному для формирования данных в процедуре корректировки данных временного ряда. После нажатия кнопки «Запомнить параметры» появляется окно для выбора координатного номера точки наблюдения на водном объекте и ингредиента, выступающего в роли зависимой переменной, при этом за основу автоматически берется период времени выбранный и зафиксированный для независимой переменной (дополнительная корректировка периода здесь исключена). После нажатия кнопки «Запомнить параметры» появляется окно с графиком парной зависимости. Из графика наглядно видно наличие или отсутствие связи между выбранными компонентами (вверху графика приводится вид регрессионной зависимости или указывается, что искомая статистическая связь недостоверна). Аномальные (нехарактерные) точки связи могут быть откорректированы, либо исключены из расчета. Для этого нажимают кнопку «Редактирование». В появившейся таблице сомнительные (нехарактерные в рамках рассматриваемой статистической связи) парные точки можно удалить или «отфлагировать», указывая признаки качества в соответствующих колонках по одному или обоим ингредиентам (X - независимая переменная, Y - зависимая). Выполненные исправления в ячейках запоминают нажатием клавиши «Enter» или «Tab» (дата не корректируются; удалить можно ту строку, в которой находится курсор). Результаты корректировки можно просматривать на графике, нажав кнопку «График». Для запоминания откорректированного файла в базе данных поступают аналогично тому, как это было указано при редактировании данных в таблице в А.4.2.2.
А.4.2.5 Для восстановления пропущенных в процессе наблюдений данных (или удаленных данных в процессе редактирования) следует активизировать в разделе главного меню «Редактирование» функцию «Восстановить пропуски временного ряда». В открывшемся окне после нажатия кнопки «Выбор: КН; ингредиент» выбирают строку с координатным номером точки наблюдения на водном объекте и ингредиентом, для которого требуется провести восстановление данных. В появившейся экранной форме «Ввод параметров для выбора одного ингредиента», показанной на рисунке А.6, действия оператора не отличаются от вышеуказанного по работе с этой формой. После нажатия кнопки «Запомнить параметры» появляется экранная форма выбора параметров для проведения восстановления данных, представленная на рисунке А.9. В левом верхнем окне приводится (автоматически определяется) средний шаг проведенных наблюдений во времени.

Рисунок А.9 - Экранная форма программы выбора параметров для восстановления пропусков исходного временного ряда
Пользуясь графиком (фрагменты его можно увеличивать, выделяя мышкой участок, который необходимо увеличить) и учитывая средний шаг наблюдений в редакционные окна «Миним. пропуск» и «Максим. пропуск» вводят ориентировочные условия для последующей оценки пропусков в исходных данных. После нажатия кнопки «Показать пропуски» появляется таблица, где указаны все даты, характеризующие начало-конец пропусков, количество дней в каждом пропуске, а также указание можно ли восстанавливать пропуск, исходя из заданных условий о допустимом количестве дней в минимальном и максимальном пропуске данных. Если в таблице имеются пропуски больше заданной продолжительности, при которых нельзя их восстанавливать, то, отказавшись от восстановления (нажимают кнопку «Отказ»), можно откорректировать максимальный пропуск данных и заново продолжить восстановление данных.
Восстановление данных можно выполнять по каждому пропуску данных отдельно, отметив его галочкой, или по всем пропускам сразу, отметив их все с помощью кнопки «Отметить все». Для продолжения процедуры при согласии с содержанием таблицы нажимают кнопку «Выбор» (при несогласии с данными таблицы нажимают кнопку «Отказ»). В появившейся снова форме, показанной на рисунке А.9, заполняют редакционные окна «Задать шаг восстановления (дни)» (при ежедневных наблюдениях шаг равен одним суткам, при подекадных наблюдениях - 10 дней, при помесячных - 30 дней и т.д.), «Задать число точек (слева и справа)» (указывают число точек, учитываемых при подборе статистической связи между заданными точками за пределами пропуска измерений; минимальное число точек должно быть не менее двух). Для восстановления данных нажимают кнопку «Восстановить пропуски». Восстановленные пропуски отражаются на графике в виде красных точек. Если проведенная процедура восстановления пропусков данных (расположение восстановленных точек на графике) не удовлетворяет пользователя, то эту операцию можно повторить, задав в редакционном окне «Задать число точек (слева и справа)» другой вариант числа точек (предварительно отменив красные точки восстановления нажатием кнопки «Отказ»). После нажатия кнопки «Подтвердить» восстановленные данные (красный цвет точек на графике заменяется на зеленый) запоминаются в анализируемом временном ряду данных только для текущего прогнозирования (при необходимости сохранения восстановленного ряда данных выполняют операцию сохранения файла с расширением «*.dan» с новым именем). Кнопка «Отказ» служит для отказа от проведенных действий по восстановлению данных и выхода из процедуры их восстановления. Нажатие кнопки «Выход» позволяет выйти из процедуры восстановления данных с сохранением восстановленных значений концентраций анализируемого вещества.
А.5 Прогнозирование
А.5.1 Прогнозирование можно проводить только тогда, когда в программу загружены необходимые исходные данные (файл с расширением «*.dat» или «*.dan»). Чтобы перейти непосредственно к прогнозированию, в главном экране формы программы (см. рисунок А.1) нажимают кнопку «Прогнозирование», после чего в появившейся закладке предлагаются следующие варианты прогнозирования:
- «По исходному временному ряду ежедневных данных»,
- «По временному ряду данных по декадам»;
- «По месячным и годовым данным, обобщенным по медиане»;
- «По месячным и годовым данным, обобщенным по моде»;
- «По парной зависимости с рассчитанной независ. переменной»;
- «По парной зависимости с вводом независ. переменной».
А.5.2 Вариант «По исходному временному ряду ежедневных данных» используют для прогнозирования по данным временного суточного ряда (например, по данным в створе водозабора или створе пункта первой категории). После выбора в данной закладке варианта прогнозирования появляется экранная форма, показанная на рисунке А.6, для выбора параметров временного ряда. На основе предложенного сервиса этой формы для прогнозирования выбирают интересуемую точку наблюдения на водном объекте, ингредиент и указывают необходимые признаки качества измерений и признаки значений данных. После нажатия кнопки «Запомнить параметры» появляется экранная форма, представленная на рисунке А.10, для выполнения процедуры данного варианта прогнозирования. В указанной экранной форме в соответствующем окне назначают дату для прогнозируемого значения ингредиента (по умолчанию предусмотрен прогноз на один шаг - на следующую очередную дату от имеющейся последней даты в загруженном файле). В случае выбора метода прогнозирования «По тренду» дополнительно появляется редакционное окно «Учитывать сезонную составляющую» (см. рисунок А.10). Учет сезонной составляющей для прогнозирования возможен только в том случае, если проводились суточные или декадные наблюдения (учитывая восстановленные данные) и в базе данных отсутствуют дубли или измерения, приходящиеся на одну и ту же календарную дату. При выборе прогнозирования с учетом сезонной составляющей в указанном редакционном окне ставится галочка. После этого экранная форма дополняется условиями выбора статистического метода прогнозирования изменения ряда остатков (установления зависимости изменений значений ряда остатков от времени после выделения сезонной составляющей), показанная на рисунке А.11. После выбора одного из указанных методов (в окне курсором ставится точка) нажимают кнопку «Получить прогноз».
Если объем исходной информации достаточен, то появляется график временного ряда значений ингредиента, показанный на рисунке А.12. Нажав кнопку «Просмотреть сезоны, ряд остатков» можно посмотреть на общий вид графиков временных рядов исходных данных, выделенной сезонной составляющей и остатков временного ряда после выделения (изъятия) временного ряда значений сезонной составляющей, показанный на рисунке А.13. Чем меньше отличается от прямой линии график остатков, тем существенней выражена сезонная составляющая для рассматриваемого ингредиента. Чем больше отличается от горизонтальной прямой линии график остатков, тем существенней выражен временной тренд изменения концентраций рассматриваемого ингредиента. Оба перечисленных факта следует учитывать при выборе метода прогнозировании, особенно, если прогноз выполняется более, чем на один шаг временного ряда. Наибольшие расхождения в кривых сезонной составляющей и остатков связаны с тем, что начало высоких значений в текущих сезонах не совпадает с их началом в выделенной среднемноголетней сезонной составляющей (фактическое значение ингредиента на графике равняется сумме значений сезонной составляющей и остатка с учетом знака «-» или «+» перед значением сезонной составляющей).

Рисунок А.10 - Исходная экранная форма программы для прогнозирования по исходному временному ряду суточных данных

Рисунок А.11 - Исходная экранная форма программы для прогнозирования по исходному временному ряду суточных данных с учетом сезонной составляющей
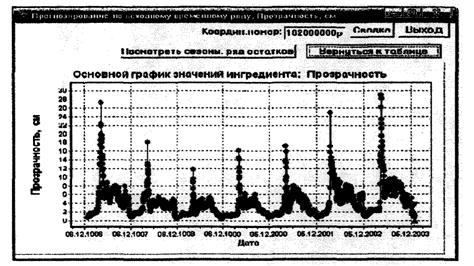
Рисунок А.12 - Экранная форма с примером графика суточного временного ряда значений ингредиента
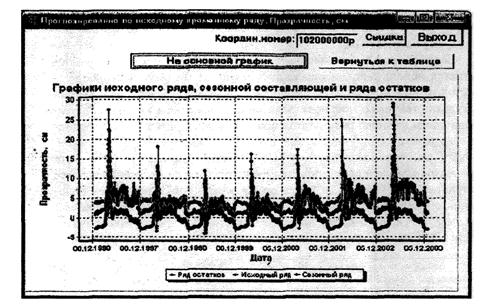
Рисунок А.13 - Экранная форма с графиками временных рядов исходных данных, выделенной сезонной составляющей и остатков временного ряда
После просмотра графика временного ряда (см. рисунок А.12) в целях снижения погрешности при выделении сезонной составляющей можно, нажав кнопку «Вернуться к таблице», выбрать по таблице другое, например, более позднее, начало временного ряда значений ингредиента. Если требуется правка данных, то для этого следует возвратиться в режим редактирования данных.
Анализ хода изменения сезонной составляющей и остатков позволяет определить наиболее вероятное изменение концентрации ингредиента на интересуемом шаге прогнозирования. Для рассматриваемого ингредиента на ретроспективном материале рекомендуется оценить и выбрать наиболее эффективные методы прогнозирования, при этом обязательно следует учитывать, как изменялось значение ингредиента в предыдущие годы: наблюдалось снижение или рост его значений (или то и другое).
Для перехода к сведениям о результатах прогноза следует нажать кнопку «Сводка» (см. рисунок А.13). Образец содержания сводки показан на рисунке А.14.
Если для получения окончательного результата прогноза предполагается использовать осредненный результат по ряду частных прогнозов, то для предполагаемой последующей процедуры осреднения результат текущего прогноза запоминают нажатием кнопки «Запомнить прогн.» (число результатов прогнозов введенных для осреднения автоматически указывается в скобках кнопки «Расчет средн. (0)»). При переходе к другому методу прогнозирования в формате «Сводка» в памяти суммирования будут оставаться занесенные ранее результаты прогноза. Для перехода на осредненный результат поведенных прогнозов в формате «Сводка» нажимают кнопку «Расчет средн. (0)». Освобождение памяти в формате «Сводка» от ранее занесенных данных производят нажатием кнопки «Очистить память».

Рисунок А.14 - Экранная форма сводки о результатах прогноза
Независимо от использования или не использования расчетов с учетом сезонной составляющей для получения окончательного (осредненного) результата прогноза желательно привлекать и другие методы прогнозирования, учитывая особенности изменения значений каждого интересуемого ингредиента в отдельные периоды годового цикла. В данной процедуре вначале с целью оценки наличия или отсутствия общей тенденции изменения значений ингредиента во времени (по тренду), а также характера и амплитуды колебания значений ингредиента анализируют временной ряд данных за весь период наблюдений (это возможно, если в этом периоде нет существенных пробелов в итоговой совместно рассматриваемой исходной и восстановленной информации). В результате указанной оценки выбирают период, значения ингредиента в котором могут быть использованы для прогнозирования. От правильного выбора периода времени и метода расчета зависит успешность окончательного решения задачи.
Для использования метода «По тренду» без учета сезонной составляющей курсором выбирают начало такого периода (см. рисунок А.10), в пределах которого значения ингредиента имеют тенденцию либо к возрастанию, либо к снижению. Эти периоды для каждого ингредиента специфичны и должны быть заранее определены в пределах годового цикла или многолетия на основе анализа изменчивости концентрации конкретного вещества. В зависимости от длительности этих периодов выбирают и возможную заблаговременность составления прогноза.
При использовании нескольких методов прогнозирования конечный результат берется в виде осредненных данных (осредненных средних значений ингредиента и отдельно осредненных верхних и нижних значений возможной погрешности проведенных вычислений). В связи с указанным очень важен правильный подбор одного или нескольких методов прогнозирования, исходя из характера изменений значений рассматриваемого ингредиента во времени (т.е. от пользователя программы требуется некоторый накопленный опыт прогнозирования, который может быть получен путем проведения предварительных прогнозов на основе уже имеющейся информации). Для последней цели в программу загружается выборочная информация, предшествующая назначенному условному времени составления прогноза, и в соответствии с поставленной задачей выполняется пробное прогнозирование суточных, декадных, годовых или месячных значений ингредиента.
В общем случае до накопления достаточного опыта прогнозирования рекомендуется составлять прогнозы с заблаговременностью не более одного - двух шагов временного ряда значений ингредиента.
А.5.3 Прогнозирование среднедекадных значений ингредиента «По временному ряду по декадам» выполняют аналогично таковым для суточных значений. В частности, если достаточно исходных данных, прогнозирование можно осуществлять по тренду изменения среднедекадных концентраций с учетом и без учета сезонной составляющей, а также с использованием других методов прогнозирования.
А.5.4 Процедура прогнозирования по месячным и годовым данным имеет некоторые особенности. Предварительно автоматически программными средствами проводят определение исходных статистических характеристик изменения месячных и годовых данных (при обобщении данных по медиане - значений ингредиента 20 %, 50 %, и 80 % обеспеченности, при обобщении данных по моде - модальных и обеспеченных на 20 % и 80 % значений ингредиента), на основе которых далее выполняют прогнозирование. После активизации варианта прогнозирования «По месячным и годовым данным, обобщенным по медиане» появляется экранная форма для выбора параметров временного ряда интересуемого ингредиента (см. рисунок А.6) (работа с этой формой описана в А.5.1.1). После нажатия кнопки «Запомнить параметры» появляется экранная форма «Методы и обобщенные значения ингредиента для прогноза», показанная на рисунке А.15, содержание которой используется для выбора метода прогнозирования, а также для работы с таблицей исходных для выполнения прогнозирования обобщенных значений ингредиента. В указанной таблице исходная информация приводится помесячно. При наличии в результатах месячных наблюдений менее четырех данных (не ежедневные и не ежедекадные наблюдения) в таблице в месячных данных приводятся единичные или среднеарифметические концентрации вещества (в числителе указывается число наблюдений за месяц). Единичные данные за месяц «идеализируются» и принимаются характерными для всего месяца. Если число наблюдений в месяце составляет четыре и более, то в месячных данных (в знаменателе) приводятся значения ингредиента 50 %-й обеспеченности (медианные значения).
Пользуясь методом выделения определенного месяца в горизонтальном поле таблицы и кнопкой «Удалить данные месяца», можно удалить явно ошибочные данные в каком-либо месяце. Если сделано указанное удаление или восстановление данных ранее не проводилось, в пропущенных месяцах данные могут быть восстановлены. Для этого курсором мышки нажимают кнопку «Восстановить параметры» (следует иметь в виду, что в весенний период рекомендуется проводить восстановление данных только при пропусках не более одного месяца подряд, а в остальные периоды - не более трех месяцев подряд).
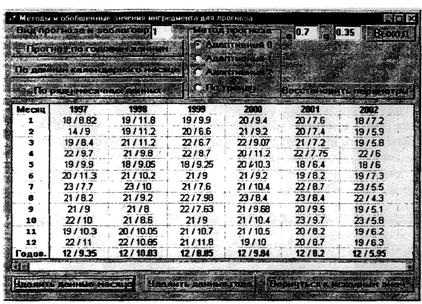
Рисунок А.15 - Экранная форма для выбора видов и методов прогноза, а также использования вспомогательной таблицы с исходными данными для прогнозирования
Далее в появившейся экранной форме, показанной на рисунке А.16, задают максимальный допустимый пропуск данных, просматривают во второй редакционной экранной форме имеющиеся пропуски, делают отметки тех пропусков, которые требуется восстановить, переходят из второй редакционной формы в первую, нажав кнопку «Выборг» или «Отказ». В первой редакционной форме после нажатия кнопки «Восполнить пропущ. точки» на графике появляются восстановленные данные в виде красных точек. Для запоминания восстановленных данных нажимают кнопку «Подтвердить» (восстановленные точки на графике после этого окрасятся в зеленый цвет). Для возврата к вспомогательной таблице нажимают кнопку «Выход». Перед выполнением прогнозирования, пользуясь курсором мышки и кнопкой «Удалить данные года», можно удалить данные определенного года (например, года с неполным или аномальным набором необходимых данных). Дополнительно можно также, пользуясь методом выделения определенного месяца в горизонтальном поле таблицы и кнопкой «Удалить данные месяца», из всех лет наблюдений убрать какой-либо один или несколько месяцев (например, для прогнозирования среднесезонных данных).
В последней строке вспомогательной таблицы приводятся медианные данные, рассчитанные по месячным значениям за соответствующий год (см. рисунок А.15).
В окне рядом с записью «Вид прогноза и заблаговр.» ставят цифру, показывающую, на какое число шагов будет выполняться прогноз (по умолчанию стоит цифра 1). Рекомендуется, чтобы устанавливаемый максимальный период заблаговременности прогноза не превышал одной трети имеющегося временного ряда значений ингредиента.

Рисунок А.16 - Экранная форма для организации восстановления пропусков месячных данных во вспомогательной таблице
Для выполнения прогнозирования требуется выбирать вид расчета. В меню предлагается три вида (см. рисунок А.15):
- «Прогноз по годовым данным»;
- «По данным календарного месяца»;
- «По ряду месячных данных».
При прогнозировании по годовым данным для экстраполяционного расчета используют имеющийся ряд годовых данных (нижняя строка таблицы). При прогнозировании по данным календарного месяца используют данные рассматриваемого календарного месяца (строка интересуемого месяца). При прогнозировании по ряду месячных данных берут последовательный ряд всех месячных данных, начиная с выбранного месяца среди представленных лет наблюдений. Отметку начала интересуемого периода (по месяцам или годам) выполняют размещением курсора.
Для прогнозирования предлагается четыре метода: три вида адаптивных методов и один по построению тренда изменения концентраций вещества во времени в пределах выбранного периода.
В случае использования для расчета метода построения тренда изменения концентраций вещества во времени выбирают такой период, в котором концентрации имеет сравнительно небольшую амплитуду колебаний и общую тенденцию либо к возрастанию, либо к снижению в пределах выделенного периода. Эти периоды для каждого ингредиента специфичны и должны быть заранее определены в пределах годового цикла или многолетия на основе анализа изменчивости во времени концентрации конкретного вещества.
Об особенностях применения адаптивных методов прогнозирования было указано в 7.3.2.3.
Последовательность операций при прогнозировании заключается в следующем (см. рисунок А.15)
- выбирают метод прогнозирования (делается отметка-точка мышкой в окне выбранного метода);
- устанавливают заблаговременность расчета (число шагов);
- нажимают кнопку выбора соответствующего (намеченного) метода прогнозирования;
- в таблице, в зависимости от выбранного метода прогнозирования, активизируют мышкой строку года или строку интересуемого месяца (в строке курсор устанавливают на выбранный начальный месяц или год в рассматриваемой последовательности данных временного ряда).
После завершения перечисленных действий появляется экранная форма с графиком(ми) значений анализируемого временного ряда. При наличии трех графиков, показанных на рисунке А.17, верхний график характеризует данные 20 %-й обеспеченности значений временного ряда, средний 50 %-ю обеспеченность, нижний - 80 %-ю обеспеченность. В результатах прогноза представляют значения 20 %-й и 80 %-й обеспеченности, только при условии, что в каждом месяце рассмотренного временного ряда имеется на менее четырех значений ингредиента. При наличии одного графика (графики значений 20 %-й и 80 %-й обеспеченности отсутствуют) спрогнозированное значение ингредиента дополняется двумя точками, характеризующими ожидаемый доверительный интервал варьирования значений этого ингредиента. Пользуясь кнопкой «Вернуться к таблице» можно вернуться к вспомогательной таблице и, изменив условия, вновь выполнить прогнозирование. Над графиком имеется кнопка «Сводка», нажатие которой позволяет получить информационную справку о результатах прогноза. Последнюю при необходимости можно дополнить или отредактировать и распечатать на принтере. Как и при прогнозировании суточных и декадных значений ингредиента, здесь также можно пользоваться функцией осреднения прогнозных данных, полученных разными методами.
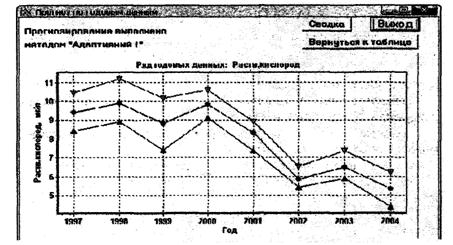
Рисунок А.17 - Экранная форма для графического представления результатов прогноза
А.5.5 Вариант прогнозирования «По месячным и годовым данным, обобщенным по моде», отличается от предыдущего только тем, что вместо медианы рассчитывается модальное значение ингредиента. Доверительный интервал при использовании адаптивных методов прогнозирования остается тем же - определяют медианное значение из отклонений от моды в соответствующем ряду обеспеченных на 20 % и 80 % значений ингредиента. Основное условие данного варианта прогнозирования - общее количество измеренных и восстановленных значений ингредиента для любого месяца должно быть не менее 28. При наличии такого количества данных рекомендуется использование как варианта с расчетом модальных, так и медианных значений ингредиента, при этом вероятность оправдываемости результатов прогноза с использованием моды может быть существенно выше, чем при использовании медианы.
А.5.6 Главной задачей прогнозирования по парной зависимости между значениями двух интересуемых ингредиентов является использование достоверных статистических связей между независимой переменной, в качестве которой берут часто измеряемый ингредиент, и зависимой переменной, в качестве которой выбирают редко измеряемый ингредиент в том же или рядом расположенном створе водного объекта.
А.5.6.1 Процедура прогнозирования по парной зависимости с рассчитанной независимой переменной заключается в следующем. Вначале осуществляют прогнозирование независимой переменной в виде интересуемых средних суточных, декадных, месячных или годовых значений с использованием одного из вариантов прогнозирования в данной программе (см. А.5.2 - А.5.5). Текстовый результат прогноза можно просмотреть, нажав кнопку «Сводка», в соответствующей экранной форме графического представления результатов прогноза. После выхода из режима предварительного прогнозирования (после нажатия кнопки «Выход») через экран главной формы программы вновь осуществляется вход в режим «Прогнозирование» (см. рисунок А.1), но уже с использованием закладки «По парной зависимости с рассчитанной независ. переменной». В появившейся экранной форме название независимой переменной будет зафиксировано автоматически. Если прогнозирование будет проводиться в пределах ретроспективного ряда данных, то следует откорректировать диапазон используемых для прогнозирования дат результатов наблюдений. Далее отмечают курсором используемые списки качеств измерения и признаков значения данных. После нажатия кнопки «Запомнить параметры» (см. рисунок А.6) появляется график изменения во времени относительных значений зависимой и независимой переменных, показанный на рисунке А.18. Цель данного графика - возможность выбрать наиболее характерный период для установления статистической связи между значениями сравниваемых ингредиентов. Красная черта на графике указывает на дату выбранного начала отсчета для установления статистической связи. Чтобы изменить дату начала отсчета, следует нажать кнопку «Таблица». В появившейся таблице курсором отмечают другую дату начала отсчета. В режиме таблицы можно временно (только в рамках данного расчета) удалить явно нехарактерные пары совмещенных значений ингредиентов. Для просмотра нового местоположения даты начала отсчета следует нажать кнопку «Временные ряды».
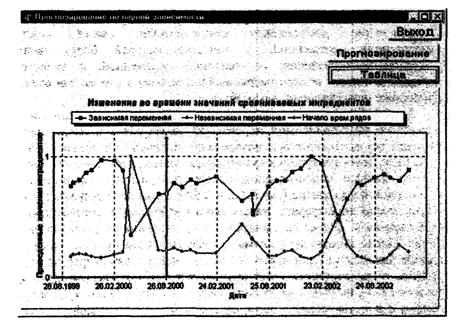
Рисунок А.18 - Экранная форма для графического представления изменения во времени относительных значений зависимой и независимой переменных
После нажатия кнопки «Прогнозирование» появляется график полученной статистической связи, на котором нанесены точка ожидаемого по прогнозу значения зависимой переменной и точки, характеризующие пределы возможной погрешности данного прогнозного значения (рисунок А.19). В приводимой погрешности учтена погрешность прогноза независимой переменной и погрешность определений по статистической зависимости между рассматриваемыми переменными. Для перехода к записи результатов прогноза нужно нажать кнопку «Сводка».
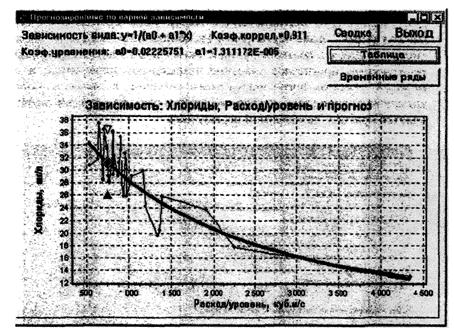
Рисунок А.19 - Экранная форма для графического представления полученной статистической связи между независимой и зависимой переменными и результата прогноза по заданному значению независимой переменной
А.5.6.2 Прогнозирование «По парной зависимости с вводом независ. переменной» отличается тем, что вводимый результат прогноза независимой переменной получен для заданного створа реки либо вне рассматриваемой программы, либо путем осреднения результатов прогноза независимой переменной, предварительно полученных по данной программе с использованием нескольких методов прогнозирования.
В результате выбора закладки «По парной зависимости с вводом независ. переменной» появляется форма для ввода результата прогноза независимой переменной, показанная на рисунке А.20. После нажатия кнопки «Выбор: КН; ингредиент» в появившейся форме выбирают нужную строку с координатным номером и ингредиентом, выступающим в роли независимой переменной (имеющиеся в базе данных значения независимой переменной будут использованы на стадии установления статистической связи). Появившаяся в окнах экранной формы выше черты ранее введенная информация не корректируется. Далее в соответствующие окна вводят информацию, характеризующую прогнозное значение независимой переменной и возможный диапазон погрешности этого значения, а также указывают конкретный срок (день, декада, месяц или год), на который осуществляется прогноз независимой переменной.
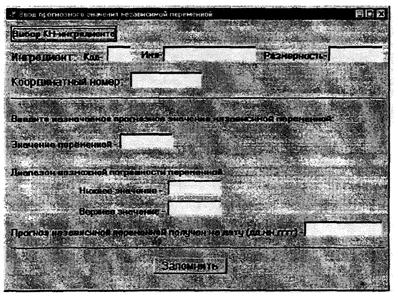
Рисунок А.20 - Экранная форма для ввода значений независимой переменной
После нажатия кнопки «Запомнить» появляется форма с предложением уточнить или подтвердить параметры вводимой независимой переменной. Поскольку эта информация будет использоваться для установления статистической связи, следует обратить внимание на выбираемые «признаки значения данных». После нажатия кнопки «Запомнить данные» появляется аналогичная форма для выбора и ввода параметров зависимой переменой, которые также будут использованы для установления статистической связи. Далее, после выхода из последней экранной формы, процедура расчета не отличается от прогнозирования по парной зависимости, рассмотренной в А.5.6.1.
Приложение Б
(справочное)
Примеры прогнозирования изменения содержания ЗВ в водных объектах во времени1
______________
1 Примеры рассчитаны на основе материалов, предоставленных ГУ «Нижегородский ЦГМС-Р»
В.1 Богородский водозабор на р. Оке (код створа 102000000р). Требуется прогноз среднемесячной (медианной) концентрации железа общего на январь 2002 г. (для примера расчета по ретроспективной информации исходный временной ряд следует искусственно сузить: 01.01.1901 - 31.12.2001). В используемой базе данных пропущенные суточные наблюдения уже восстановлены. Вначале для общего просмотра изменения среднемесячной концентрации железа во времени выбирают метод прогноза «По тренду» и вид прогноза «По данным календарного месяца». В итоге получают график, показанный на рисунке В.1. По этому графику можно сделать вывод, что имеет место высокий темп изменения концентраций во времени. Из методов прогнозирования здесь подходит, прежде всего, адаптивный метод второго порядка и в меньшей степени адаптивный метод первого порядка (для использования метода «По тренду» здесь мало данных - всего две точки: 2000 и 2001 гг.; метод «Адаптивный 0» не подходит, поскольку в предыстории в 1997 - 1999 гг. имел место линейный тренд).

Рисунок В.1 - Иллюстрация изменения средних за январь концентраций железа общего во времени в створе Богородского водозабора
Используя метод «Адаптивный 2» получим следующие прогнозные данные: среднее значение - 0,223 мг/дм3, доверительный интервал варьирования от 0,193 до 0,236 мг/дм3; по методу «Адаптивный 1» - среднее значение - 0,545 мг/дм3, интервал от 0,514 до 0,557 мг/дм3. Результаты прогноза по обоим методам вводят в память для осреднения данных, используя сервис, предусмотренный в формате «Сводки». Теперь проводят прогнозирование по ряду месячных данных. Вначале для общего просмотра хода изменения месячных концентраций в качестве начального для отсчета выбирают январь 2001 г. и метод прогноза «По тренду». В итоге получают график, показанный на рисунке В.2.
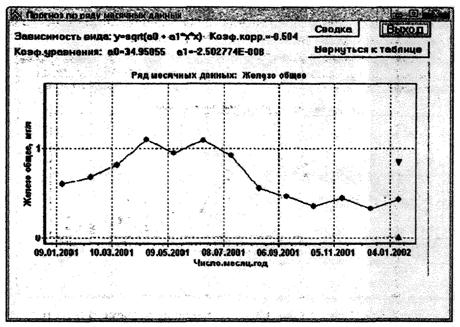
Рисунок В.2 - Иллюстрация изменения среднемесячных концентраций железа общего во времени в створе Богородского водозабора
Из графика видно, что, начиная с января 2001 г., можно использовать метод «Адаптивный 1», т.к. роль первых точек временного ряда здесь мала благодаря низким весовым коэффициентам при первых членах в полиномиальной зависимости (в принципе с таким же успехом можно использовать и весь временной ряд, результат прогноза будет примерно одинаков). С июня 2001 г. для прогнозирования можно использовать метод «По тренду». По первому из них получают среднюю концентрацию 0,392 мг/дм3 и интервал от 0,349 до 0,468 мг/дм3 (рисунок В.3); по второму методу соответственно среднюю - 0,298 мг/дм3 и интервал от 0,122 до 0,473 мг/дм3. После введения последних результатов прогноза в память для осреднения данных и последующего осреднения всех результатов прогноза, полученных по разным методам получают среднюю концентрацию 0,364 мг/дм3 и интервал - от 0,295 до 0,434 мг/дм3.
Действительно состоявшаяся концентрация железа общего в январе 2002 г. составила 0,403 мг/дм3. Прогноз можно считать оправдавшимся, поскольку состоявшаяся концентрация попала в прогнозный интервал варьирования значения ингредиента.
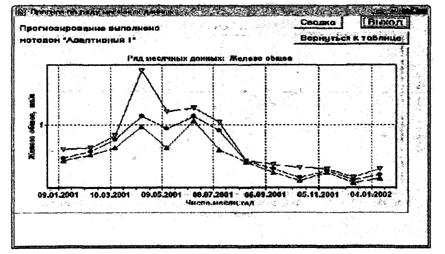
Рисунок В.3 - Иллюстрация изменения среднемесячных и обеспеченных на 20 % и 80 % концентраций железа общего во времени в створе Богородского водозабора
В.2 Богородский водозабор (код створа 102000000р). Требуется прогноз среднегодовой концентрации железа общего на 2002 г. Вначале для общего просмотра изменения среднегодовой концентрации железа во времени выбирают метод прогнозирования «По тренду» и вид прогноза «Прогноз по годовым данным». В результате получают график, показанный на рисунке В.4. Как видно из графика, в пределах 1997 - 2001 гг. незначительная линейная тенденция наметилась только в период 1998 - 2001 гг. В этот период в качестве методов прогнозирования подходят «По тренду» и «Адаптивный 1».
По методу «Адаптивный 1» - среднее значение - 0,529 мг/дм3 и интервал - 0,405 - 0,763 мг/дм3; «По тренду» - среднее значение - 0,563 мг/дм3 и интервал от 0,453 до 0,673 мг/дм3. Осредненные результаты прогноза: среднее значение - 0,546 мг/дм3, интервал от 0,429 до 0,718 мг/дм3. Состоявшееся среднегодовое значение в 2002 г. равно 0,510 мг/дм3. В целом, прогноз можно считать оправдавшимся.
В.3 В створе выше г. Дзержинска (координатный номер 561204333р) ведутся наблюдения ГУ «Нижегородский ЦГМС-Р». Требуется определить по прогнозу среднемесячную концентрацию (медианное значение) хлоридов в ноябре 2002 г. (в рассматриваемом примере условно будем считать, что в исходной информации имеются данные только по 15 июля 2002 г.). В главном экране формы программы в горизонтальном меню нажимают кнопку «Прогнозирование». В появившемся подменю выбирают вариант прогнозирования «По месячным и годовым данным, обобщенным по медиане». В следующей экранной форме в створе с координатным номером 561204333р выбирают интересуемый ингредиент (хлориды), в редакционном окне в качестве конца периода записывают 15.07.2002, вводят необходимые признаки качества измерений и признаки значений данных и нажимают кнопку «Запомнить параметры».
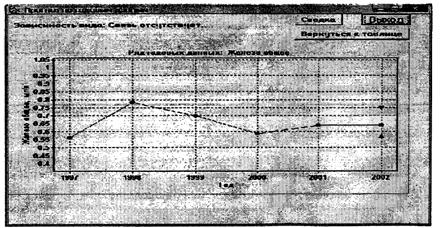
Рисунок В.4 - Иллюстрация изменения среднегодовых концентраций железа общего во времени в створе Богородского водозабора
Далее, вначале восстанавливают значения концентраций хлоридов в тех месяцах, где отсутствуют данные. Для этого ставят курсор в любом месте пропуска среднемесячных концентраций в появившейся на экране таблице, показанной на рисунке В.5, и нажимают кнопку «Восстановить параметры». В появившейся экранной форме, показанной на рисунке В.6, в редакционном окне «Задайте максим. пропуск (мес.)» ставят цифру 2. Для проверки правильности выбора максимального пропуска нажимают кнопку «Показать пропуски». В появившейся таблице, представленной на рисунке В.7, приведены все пропуски в исходных данных и указано для каждого из них правомерность восполнения данных с выбранным шагом.
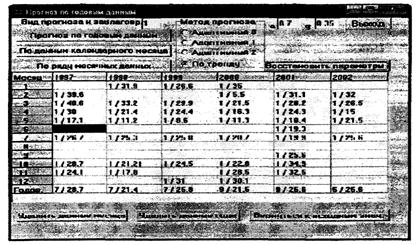
Рисунок B.5 - Иллюстрация исходной для составления прогноза таблицы среднемесячных концентраций хлоридов в створе выше г. Дзержинска
В рассматриваемом примере выбранный шаг позволяет восстановить все пропущенные данные. Для продолжения расчета нажимают последовательно кнопки «Отметить все» и «Выбор». Во вновь появившейся экранной форме нажимают кнопки «Восстановить пропущ. точки» и «Подтвердить» (на графике восстановленные среднемесячные концентрации хлоридов до подтверждения отображаются в виде красных, а после подтверждения зеленых точек) (см. рисунок В.8).

Рисунок В.6 - Иллюстрация изменения среднемесячных концентраций хлоридов во времени в створе выше г. Дзержинска до восстановления пропусков в наблюдениях
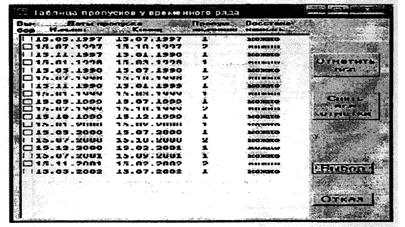
Рисунок В.7 - Экранная форма для принятия решения по восполнению пропусков в результатах наблюдений в створе выше г. Дзержинска

Рисунок В.8 - Иллюстрация восстановленных среднемесячных концентраций хлоридов в створе выше г. Дзержинска
Затем для общего просмотра изменения среднемесячной концентрации хлоридов во времени выбирают метод прогнозирования «По тренду» и вид прогнозирования «По данным календарного месяца». Результат прогноза показан на рисунке В.9.
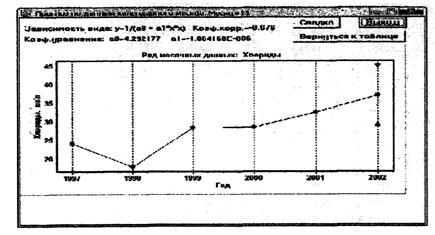
Рисунок В.9 - Иллюстрация изменения ноябрьских среднемесячных концентраций хлоридов во времени в створе выше г. Дзержинска
Ход изменения концентрации хлоридов показывает, что можно использовать метод прогнозирования «По тренду» «По данным календарного месяца» и, начиная с апреля 2002 г., «По ряду месячных данных» (другие методы дают очень высокую погрешность прогноза). В результате прогнозирования по методу «По тренду» получают среднюю концентрацию, равную 37,06 мг/дм3, и интервал от 29,12 до 45,0 мг/дм3; по методу «По данным календарного месяца» (период заблаговременности прогнозирования 4 месяца) - среднюю концентрацию 34,31 мг/дм3, интервал от 31,14 до 37,47 мг/дм3 (рисунок В.10). Осредненные результаты прогноза составят: среднее значение - 35,68 мг/дм3, интервал от 30,13 до 41,23 мг/дм3. Состоявшееся содержание хлоридов в ноябре 2002 г. равно 32,4 мг/л. В целом, прогноз можно считать оправдавшимся.
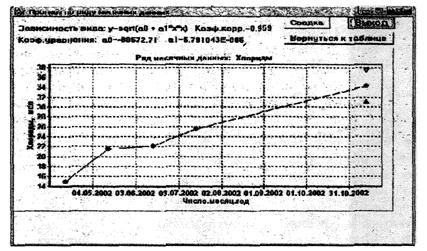
Рисунок В.10 - Иллюстрация изменения среднемесячных концентраций хлоридов во времени (с апреля 2002 г.) в створе выше г. Дзержинска
В.4 Створ выше г. Дзержинска (код створа 561204333р). Требуется прогноз концентрации хлоридов на 04.07.2001. Поскольку наблюдения в рассматриваемом створе ведутся УГМС по хлоридам один раз в месяц, прогноз на конкретную дату возможен только при использовании парной статистической связи, например, с расходами воды по данным наблюдения в створе Богородского водозабора. В связи с этим вначале составляют прогноз для расхода речной воды. Нажимают в горизонтальном меню главной экранной форме программы кнопку «Прогнозирование», а появившейся закладке выбирают вариант прогнозирования «По исходному временному ряду ежедневных данных». В экранной форме «Ввод параметров для выбора одного ингредиента» нажимают кнопку «Выбор: КН; ингредиент». В появившейся таблице курсором (галочкой) отмечают ингредиент «Расход/уровень» в створе Богородского водозабора (КН - 102000000р) и нажимают кнопку «Выбрать одну строку». В новой экранной форме устанавливают условный конец диапазона дат. Для рассматриваемого примера условно назначают дату «01.06.2001» (т.е. в расчет войдут все даты до 01.06.2001; перед прогнозированием это желательно проверить по информации в таблице). Далее в «Списке качеств измерения» и «Списке признаков значений данных» нажимают кнопки «Выделить весь список». После нажатия кнопки «Запомнить параметры» переходят в экранную форму для определения условий прогнозирования. Проверяют наличие требуемой даты для прогноза (04.07.2001), выбирают метод прогнозирования «По тренду», ставят галочку в позиции учитывать сезонную составляющую и в методе прогнозирования ряда остатков отмечают метод «Адаптивный 1», позволяющий усиливать значимость в полиномиальной связи последних значений временного ряда, и нажимают кнопку «Получить прогноз». Нажав кнопку «Сводка», можно посмотреть на результат прогноза расхода речной воды. Прогнозное значение получается равным 0 м3/с, на графике видно, что это явно неверное значение. Нажимают кнопку «Вернуться к таблице» для подбора более соответствующего задаче прогноза значения alfa. Вместо значения alfa, равного 0,7, подставляют более низкие значения и повторяют прогнозирование. В рассматриваемом примере при значениях alfa от 07 до 0,2 в период, когда происходит существенное изменение водности реки, прогнозные значения расхода получаются явно заниженными. В связи с этим выбирают значение alfa, равное 0,1, и выполняют окончательное прогнозирование расхода воды на 04.07.2001 (в сводке результатов расчета он равен 979,68 м3/с). Далее нажимают кнопку «Выход» при этом прогнозные данные по расходу автоматически запоминаются. В режиме «Прогнозирование» выбирают вариант прогнозирования «По парной зависимости с рассчитанной независ. переменной» (если прогнозные значения были получены вне данной программы, то следует выбирать вариант «По парной зависимости с вводом независ. переменной»). Далее повторяют ввод параметров независимой переменной (название ее заблокировано и не корректируется), где условно вновь назначают конец диапазона - «04.07.2001» и отвечают на остальные вопросы. В следующей экранной форме выбирают координатный номер створа выше г. Дзержинска (561004333р) и ингредиент - «Хлориды». Диапазон дат не корректируется (он автоматически остается тем же, что был назначен ранее для независимой переменной), в списках качеств измерений нажимают кнопку «Выделить весь список», в списке признаков значении данных выбирают «Выделить весь список». После нажатия кнопки «Запомнить параметры» переходят к просмотру графика «Изменение во времени значений сравниваемых ингредиентов», показанного на рисунке В.11.

Рисунок В.11 - Иллюстрация изменения во времени относительных значений концентраций хлоридов и расходов воды в р. Оке в створе выше г. Дзержинска
На графике визуально по ходу изменения спаренных во времени относительных значений (не в мг/дм3) ингредиентов можно оценить тесноту обратной (или прямой) статистической связи между ними на всем отрезке времени систематических наблюдений. Если время для начала оценки статистической связи целесообразно сдвинуть на более поздний срок, то следует нажать кнопку «Таблица» и курсором выбрать новое начало срока для установления статистической связи (здесь имеется также возможность без запоминания, только на момент данного прогноза, удалить некоторые явно случайные нехарактерные парные точки). Нажав кнопку «Временные ряды» на появившемся графике по красной черте можно проследить, насколько удачно выбран новый срок начала отсчета для установления статистической связи. Нажав кнопку «Прогнозирование», получают график статистической связи, показанный на рисунке В.12, между значениями сравниваемых ингредиентов, а также точки прогнозных значений хлоридов. Точка на графике с концентрацией хлоридов, равная 5,5 мг/дм3 (при расходе 759 м3/с) явно нехарактерна для рассмотренных взаимозависимых пар данных и искажает направленность траектории статистической связи. Для данного расчета эту точку следует удалить, перейдя в таблицу с исходными данными (нажав кнопку «Таблица»). После удаления нехарактерной концентрации хлоридов для повторения прогнозирования курсор устанавливают на концентрацию хлоридов в первой строке таблицы и нажимают кнопку «Прогнозирование». На появившемся графике, показанном на рисунке В.13, видно, что статистическая связь стала более точно аппроксимирующей изменения концентраций хлоридов в зависимости от расхода речной воды.

Рисунок В.12 Иллюстрация статистической связи между концентрациями хлоридов и расходами воды в р. Оке в створе выше г. Дзержинска

Рисунок В.13 - Иллюстрация статистической связи между концентрациями хлоридов и расходами воды в р. Оке в створе выше г. Дзержинска после удаления нехарактерной концентрации хлоридов
Для перехода к просмотру и печати текста результатов прогноза следует нажать кнопку «Сводка». Полученный результат прогноза по хлоридам составил: значение ингредиента - 25,49 мг/дм3; доверительный интервал варьирования от 18,6 до 32,19 мг/дм3. Действительное наблюденное значение хлоридов на дату прогноза составило 19,9 мг/дм3. Таким образом, прогноз можно считать оправдавшимся.
В.5 Богородский водозабор (код створа 102000000р). Требуется прогноз прозрачности речной воды на 20 апреля 2003 года (в рассматриваемом примере условно будем считать, что исходные данные заканчиваются 19 апреля 2003 года). При выборе временного ряда данных его конец назначим на 20.04.2003 (при этом последняя дата наблюдений остается 19.04.2003). Прогнозирование выполняют с учетом сезонной составляющей. Для этого в методах прогнозирования выбирают «По тренду» и ставят «галочку» в окне «Учитывать сезонную составляющую». В методах прогнозирования ряда остатков предварительно можно выбрать любой метод для просмотра сезонной составляющей (отмечают «Адаптивный 0»). После нажатия кнопки «Получить прогноз» появляется экранная форма, показанная на рисунке В.14.
Указанной цели могут соответствовать два метода «Адаптивный 0» и «Адаптивный 1». Метод «Адаптивный 2» будет давать явно завышенный результат значения цветности, метод «По тренду» в рассматриваемом случае не подходит по содержанию. По методу «Адаптивный 0» получим прогнозное значение цветности 24,32 см и доверительный интервал от 23,39 до 25,25 см (см. рисунок В.14); по методу «Адаптивный 1» - 35,07 см и интервал от 32,3 до 37,83 см. Поскольку по прогнозу можно ожидать лишь небольшое повышение или снижение значения цветности, подбирают такое значение alfa, при котором это условие имеет место. Таким значением alfa будет 0,5, а результат прогноза составит 30,13 см с доверительным интервалом от 27,82 до 32,44 см. Осредненный результат прогноза по двум использованным методам составит 27,22 см, доверительный интервал от 25,6 до 28,85 см. Действительное значение цветности на 20.04.2003 составило 28,02 см. Таким образом, данный прогноз можно считать оправдавшимся.
Рисунок В.14 - Иллюстрация изменения ежесуточных значений прозрачности воды в р. Оке во времени в створе Богородского водозабора
Приложение В
(справочное)
Образец структуры информации в виде таблиц Microsoft Excel
|
1997 |
||||||||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
1 |
605 |
575 |
596 |
1260 |
2310 |
974 |
911 |
749 |
626 |
671 |
1100 |
1030 |
|
2 |
603 |
573 |
596 |
1270 |
2270 |
968 |
881 |
755 |
617 |
671 |
1100 |
1010 |
|
3 |
600 |
578 |
590 |
1310 |
2146 |
956 |
872 |
749 |
611 |
611 |
1080 |
992 |
|
4 |
596 |
573 |
590 |
1350 |
2200 |
950 |
863 |
740 |
611 |
689 |
1070 |
972 |
|
5 |
602 |
573 |
590 |
1430 |
2160 |
950 |
872 |
752 |
605 |
704 |
1050 |
959 |
|
6 |
597 |
573 |
600 |
1540 |
2060 |
953 |
872 |
743 |
596 |
713 |
1040 |
945 |
|
7 |
593 |
564 |
606 |
1690 |
1950 |
956 |
872 |
737 |
596 |
728 |
1010 |
918 |
|
8 |
594 |
557 |
616 |
2140 |
1920 |
956 |
872 |
728 |
593 |
734 |
1010 |
905 |
|
9 |
599 |
559 |
616 |
2280 |
1910 |
956 |
866 |
719 |
599 |
740 |
1000 |
891 |
|
10 |
599 |
550 |
626 |
2360 |
1910 |
962 |
854 |
713 |
596 |
752 |
1040 |
870 |
|
11 |
599 |
545 |
645 |
2540 |
1850 |
974 |
842 |
701 |
605 |
767 |
1050 |
857 |
|
12 |
599 |
543 |
668 |
2740 |
1790 |
974 |
842 |
698 |
608 |
779 |
1060 |
849 |
|
13 |
605 |
541 |
680 |
2820 |
1750 |
971 |
833 |
692 |
608 |
794 |
1070 |
836 |
|
И |
605 |
541 |
698 |
2720 |
1670 |
962 |
830 |
692 |
611 |
803 |
1090 |
792 |
|
15 |
605 |
543 |
710 |
2680 |
1610 |
956 |
515 |
689 |
611 |
866 |
1110 |
786 |
|
16 |
605 |
543 |
728 |
2640 |
1510 |
950 |
803 |
683 |
614 |
920 |
1120 |
791 |
|
17 |
616 |
545 |
799 |
2640 |
1400 |
944 |
788 |
683 |
614 |
941 |
1140 |
795 |
|
18 |
616 |
554 |
818 |
2630 |
1350 |
950 |
782 |
665 |
617 |
965 |
1190 |
787 |
|
19 |
616 |
554 |
844 |
2630 |
1300 |
956 |
770 |
659 |
617 |
998 |
1240 |
784 |
|
20 |
616 |
561 |
878 |
2630 |
1200 |
962 |
761 |
677 |
623 |
1010 |
1260 |
790 |
|
21 |
616 |
573 |
925 |
2620 |
1120 |
962 |
752 |
683 |
629 |
1030 |
1240 |
787 |
|
22 |
616 |
580 |
972 |
2610 |
1080 |
956 |
746 |
677 |
632 |
1030 |
1190 |
787 |
|
23 |
616 |
580 |
1030 |
2600 |
1060 |
956 |
737 |
665 |
635 |
1040 |
1160 |
781 |
|
24 |
610 |
580 |
1060 |
2590 |
1030 |
953 |
734 |
659 |
641 |
1040 |
1110 |
781 |
|
25 |
610 |
590 |
1090 |
2540 |
1010 |
947 |
743 |
656 |
644 |
1050 |
1090 |
770 |
|
26 |
621 |
590 |
1190 |
2470 |
998 |
935 |
743 |
653 |
656 |
1060 |
1090 |
773 |
|
27 |
626 |
590 |
1210 |
2440 |
989 |
923 |
740 |
650 |
662 |
1100 |
1090 |
773 |
|
28 |
615 |
596 |
1240 |
2400 |
980 |
920 |
737 |
644 |
665 |
1110 |
1090 |
756 |
|
29 |
571 |
1260 |
2370 |
974 |
920 |
737 |
635 |
674 |
1110 |
1060 |
741 |
|
|
30 |
573 |
1270 |
2350 |
968 |
917 |
734 |
632 |
674 |
1110 |
1060 |
730 |
|
|
31 |
573 |
1280 |
947 |
734 |
632 |
1100 |
718 |
|||||
|
1998 |
||||||||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
1 |
718 |
781 |
659 |
2070 |
4430 |
1900 |
826 |
750 |
1550 |
958 |
1500 |
1210 |
|
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
Библиография
[1] Тарасов М.Н., Клименко О.А., Семенов И.В. и др. Вопросы исследования и прогнозирования загрязненности рек // Гидрохимические материалы. - 1977. - Т. 67. - 114 с.
[2] Временные методические рекомендации по оперативному прогнозированию загрязненности рек. - Л.: Гидрометеоиздат, 1981. - 103 с.
[3] Плохинский Н.А. Биометрия. - М.: Изд-во МГУ, 1970. - 367 с.
[4] Лукашин Ю.П. Адаптивные методы краткосрочного прогнозирования. - М.: «Статистика», 1979. - 254 с.
Ключевые слова: методы, прогнозирование во времени, содержание загрязняющих веществ, водные объекты, результаты гидрохимических наблюдений, рекомендации
Ласт регистрации изменений
|
Номер изменения |
Номер страницы |
Номер документа (ОРН) |
Подпись |
Дата |
||||
|
измененной |
замененной |
новой |
аннулированной |
внесения изменений |
введения изменений |
|||